notebook_login()Prompting LLMs Using Different Prompting Styles
deep learning
LLM
python
In this notebook I use 20 math reasoning dataset questions to prompt three 7B-parameter LLMs using 3 different prompting styles.
Background
In this notebook, I test the performance of different LLMs on a small set of samples from math reasoning datasets using zero-shot, zero-shot-Chain-of-Thought and Plan-and-Solve+ (PS+) prompting techniques. The purpose of this exercise is for me to get some practice prompting LLMs.
In a previous blog post, I prompted questions from math reasoning datasets to different model chat interfaces (HuggingChat, Zephyr Chat and ChatGPT). However, when presenting these results to a fastai study group, one of the more experienced members noted that these model interfaces have built-in system prompts that will interfere with the prompts provided by the user. So, in order to get a sense of how these models perform without a system prompt, I decided to prompt these models directly using HuggingFace in this exercise.
Models Tested
I’ll test three models in this exercise:
Prompting Styles
I’ll show an example of the three different prompting styles that I’ll use for this evaluation.
Zero-shot
Q: After eating at the restaurant, Sally, Sam, and Alyssa decided to divide the bill evenly. If each person paid 45 dollars, what was the total of the bill?
A: The answer is
Zero-shot-Chain-of-Thought
Q: After eating at the restaurant, Sally, Sam, and Alyssa decided to divide the bill evenly. If each person paid 45 dollars, what was the total of the bill?
A: Let’s think step by step.
PS+
Q: After eating at the restaurant, Sally, Sam, and Alyssa decided to divide the bill evenly. If each person paid 45 dollars, what was the total of the bill?
A: Let’s first understand the problem, extract relevant variables and their corresponding numerals, and devise a plan. Then, let’s carry out the plan, calculate intermediate results (pay attention to calculation and common sense), solve the problem step by step, and show the answer.
Loading and Trying Out the Models
I’ll start by loading each model and testing out a prompt for each manually:
::: {#cell-5 .cell _cell_guid=‘b1076dfc-b9ad-4769-8c92-a6c4dae69d19’ _uuid=‘8f2839f25d086af736a60e9eeb907d3b93b6e0e5’ quarto-private-1=‘{“key”:“execution”,“value”:{“iopub.execute_input”:“2023-10-31T01:58:45.248095Z”,“iopub.status.busy”:“2023-10-31T01:58:45.247784Z”,“iopub.status.idle”:“2023-10-31T01:59:51.608104Z”,“shell.execute_reply”:“2023-10-31T01:59:51.607351Z”,“shell.execute_reply.started”:“2023-10-31T01:58:45.248068Z”}}’ scrolled=‘true’ trusted=‘true’}
!pip install git+https://github.com/huggingface/transformers.git huggingface_hub
from transformers import pipeline
from huggingface_hub import notebook_login
import pandas as pd, torch:::
Mistral-7B-Instruct-v0.1
pipe = pipeline(
"text-generation",
model="mistralai/Mistral-7B-Instruct-v0.1",
torch_dtype=torch.bfloat16,
device_map="auto")messages = [
{"role": "user", "content": """
Q: After eating at the restaurant, Sally, Sam, and Alyssa decided to divide the bill evenly. If each person paid 45 dollars, what was the total of the bill?
A: Let's first understand the problem, extract relevant variables and their corresponding numerals, and devise a plan. Then, let's carry out the plan, calculate intermediate results (pay attention to calculation and common sense), solve the problem step by step, and show the answer.
"""},
]
pipe.use_default_system_prompt = False
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.<s>[INST]
Q: After eating at the restaurant, Sally, Sam, and Alyssa decided to divide the bill evenly. If each person paid 45 dollars, what was the total of the bill?
A: Let's first understand the problem, extract relevant variables and their corresponding numerals, and devise a plan. Then, let's carry out the plan, calculate intermediate results (pay attention to calculation and common sense), solve the problem step by step, and show the answer.
[/INST] Plan:
1. Extract the relevant variables and their corresponding numerals.
2. Devise a plan to solve the problem.
3. Carry out the plan and calculate intermediate results.
4. Solve the problem step by step.
5. Show the answer.
Solution:
1. Variables and their corresponding numerals:
- Total bill (T)
- Number of people (N)
- Payment per person (P)
2. Plan:
We need to determine the total bill (T) based on the number of people (N) and the payment per person (P). We can use the following equation:
T = P * N
3. Carrying out the plan and calculating intermediate results:
We are given the payment per person (P) as 45 dollars. We need to find the total bill (T) by multiplying the payment per person by the number of people. We are also given the number of people (N) as Sally, Sam, and Alyssa.
T = 45 * N
4. Solving the problem step by step:
We can substitute the given values into the equationzephyr-7b-alpha
pipe = pipeline(
"text-generation",
model="HuggingFaceH4/zephyr-7b-alpha",
torch_dtype=torch.bfloat16,
device_map="auto")messages = [
{"role": "user", "content": """
Q: After eating at the restaurant, Sally, Sam, and Alyssa decided to divide the bill evenly. If each person paid 45 dollars, what was the total of the bill?
A: Let's first understand the problem, extract relevant variables and their corresponding numerals, and devise a plan. Then, let's carry out the plan, calculate intermediate results (pay attention to calculation and common sense), solve the problem step by step, and show the answer.
"""},
]
pipe.use_default_system_prompt = False
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])/opt/conda/lib/python3.10/site-packages/transformers/generation/utils.py:1473: UserWarning: You have modified the pretrained model configuration to control generation. This is a deprecated strategy to control generation and will be removed soon, in a future version. Please use and modify the model generation configuration (see https://huggingface.co/docs/transformers/generation_strategies#default-text-generation-configuration )
warnings.warn(<|user|>
Q: After eating at the restaurant, Sally, Sam, and Alyssa decided to divide the bill evenly. If each person paid 45 dollars, what was the total of the bill?
A: Let's first understand the problem, extract relevant variables and their corresponding numerals, and devise a plan. Then, let's carry out the plan, calculate intermediate results (pay attention to calculation and common sense), solve the problem step by step, and show the answer.
</s>
<|assistant|>
Let's assume the total bill is x.
Each person paid 45 dollars, so each person's share of the bill is 45.
If the total bill is x, then the sum of each person's share is also x, as each person's share is one-third of the total bill.
Therefore, we have:
x = 45 + 45 + 45 (the sum of each person's share)
x = 135 (the total bill)
So the total bill was $135.
In summary, we identified the variables (total bill and each person's share), calculated intermediate results (total of each person's share), and solved the problem by setting up an equation and calculating the total bill.Llama-2-7b-chat-hf
pipe = pipeline(
"text-generation",
model="meta-llama/Llama-2-7b-chat-hf",
torch_dtype=torch.bfloat16,
device_map="auto")messages = [
{"role": "user", "content": """
Q: After eating at the restaurant, Sally, Sam, and Alyssa decided to divide the bill evenly. If each person paid 45 dollars, what was the total of the bill?
A: Let's first understand the problem, extract relevant variables and their corresponding numerals, and devise a plan. Then, let's carry out the plan, calculate intermediate results (pay attention to calculation and common sense), solve the problem step by step, and show the answer.
"""},
]
pipe.use_default_system_prompt = False
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])<s>[INST] Q: After eating at the restaurant, Sally, Sam, and Alyssa decided to divide the bill evenly. If each person paid 45 dollars, what was the total of the bill?
A: Let's first understand the problem, extract relevant variables and their corresponding numerals, and devise a plan. Then, let's carry out the plan, calculate intermediate results (pay attention to calculation and common sense), solve the problem step by step, and show the answer. [/INST] Great, let's dive into the problem!
After eating at the restaurant, Sally, Sam, and Alyssa decided to divide the bill evenly. If each person paid $45, what was the total of the bill?
To solve this problem, we need to identify the variables involved and determine their values. Let's do this by breaking down the information given in the problem:
Variables:
* Sally
* Sam
* Alyssa
* Total bill
Values:
* Sally paid $45
* Sam paid $45
* Alyssa paid $45
* Total bill = $45 + $45 + $45 = $135
Now, let's put this information together to find the total of the bill:
Total bill = $135
So, the total of the bill was $135.
Let me know if you have any questions or if you'd like me to explain the steps in more detail!Testing All Prompts
I have entered 20 questions (from the Appendix of the paper Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models (Lei Wang, et al)) into a CSV file:
df = pd.read_csv("/kaggle/input/questions5/questions.csv")
df.head()| dataset | question | |
|---|---|---|
| 0 | AQuA | The average wages of a worker during a fortnig... |
| 1 | AQuA | If 27 bottles of soda cost A cents, how much w... |
| 2 | GSM8K | James decides to run 3 sprints 3 times a week.... |
| 3 | GSM8K | In a dance class of 20 students, 20% enrolled ... |
| 4 | MultiArith | The school cafeteria ordered 42 red apples and... |
To prepare the questions for the prompts, I’ll prepend each question with "Q:" and append each question with "\n\nA: <instruction>" where <instruction> is the given instruction based on the type of prompt I’m constructing. For example, for Zero-shot prompting:
"Q: " + df.question[1] + "\n\nA: The answer is"'Q: If 27 bottles of soda cost A cents, how much will B bottles cost in dollars? Answer Choices: (A) AB/2700 (B) 27/AB (C) AB/270 (D) 2700/AB (E) 100AB/27\n\nA: The answer is'I’ll use the same parameters for these models as the official chat interfaces published by the model authors.
I’ll also create a copy of the DataFrame with questions in order to populate responses for each model.
model_names = ['Mistral-7B-Instruct-v0.1', 'zephyr-7b-alpha', 'Llama-2-7b-chat-hf']
prompting_styles = ['Zero-shot', 'Zero-shot-CoT', 'PS+']
dfs = []
for name in model_names:
model_dfs = []
for style in prompting_styles:
# create a DataFrame for each prompting style
temp_df = df.copy()
temp_df['model'] = name
temp_df['prompting_style'] = style
temp_df['response'] = None
model_dfs.append(temp_df)
# Create a DataFrame for each model and store in a list
model_df = pd.concat(model_dfs)
dfs.append(model_df)I now have three DataFrames, one for each of my models, and each with 20 rows of questions for each prompting style.
dfs[0].head()| dataset | question | model | prompting_style | response | |
|---|---|---|---|---|---|
| 0 | AQuA | The average wages of a worker during a fortnig... | Mistral-7B-Instruct-v0.1 | Zero-shot | None |
| 1 | AQuA | If 27 bottles of soda cost A cents, how much w... | Mistral-7B-Instruct-v0.1 | Zero-shot | None |
| 2 | GSM8K | James decides to run 3 sprints 3 times a week.... | Mistral-7B-Instruct-v0.1 | Zero-shot | None |
| 3 | GSM8K | In a dance class of 20 students, 20% enrolled ... | Mistral-7B-Instruct-v0.1 | Zero-shot | None |
| 4 | MultiArith | The school cafeteria ordered 42 red apples and... | Mistral-7B-Instruct-v0.1 | Zero-shot | None |
dfs[1].head()| dataset | question | model | prompting_style | response | |
|---|---|---|---|---|---|
| 0 | AQuA | The average wages of a worker during a fortnig... | zephyr-7b-alpha | Zero-shot | None |
| 1 | AQuA | If 27 bottles of soda cost A cents, how much w... | zephyr-7b-alpha | Zero-shot | None |
| 2 | GSM8K | James decides to run 3 sprints 3 times a week.... | zephyr-7b-alpha | Zero-shot | None |
| 3 | GSM8K | In a dance class of 20 students, 20% enrolled ... | zephyr-7b-alpha | Zero-shot | None |
| 4 | MultiArith | The school cafeteria ordered 42 red apples and... | zephyr-7b-alpha | Zero-shot | None |
dfs[2].head()| dataset | question | model | prompting_style | response | |
|---|---|---|---|---|---|
| 0 | AQuA | The average wages of a worker during a fortnig... | Llama-2-7b-chat-hf | Zero-shot | None |
| 1 | AQuA | If 27 bottles of soda cost A cents, how much w... | Llama-2-7b-chat-hf | Zero-shot | None |
| 2 | GSM8K | James decides to run 3 sprints 3 times a week.... | Llama-2-7b-chat-hf | Zero-shot | None |
| 3 | GSM8K | In a dance class of 20 students, 20% enrolled ... | Llama-2-7b-chat-hf | Zero-shot | None |
| 4 | MultiArith | The school cafeteria ordered 42 red apples and... | Llama-2-7b-chat-hf | Zero-shot | None |
There should be three instances of each question, one for each prompting style:
dfs[0].groupby(dfs[0].question).count()['dataset'].unique(),\
dfs[1].groupby(dfs[1].question).count()['dataset'].unique(),\
dfs[2].groupby(dfs[2].question).count()['dataset'].unique()(array([3]), array([3]), array([3]))Each model’s DataFrame should have 20 rows for each of the three prompting styles:
dfs[0].groupby(dfs[0].prompting_style).count()['dataset'].unique(),\
dfs[1].groupby(dfs[1].prompting_style).count()['dataset'].unique(),\
dfs[2].groupby(dfs[2].prompting_style).count()['dataset'].unique()(array([20]), array([20]), array([20]))And finally, I’ll check that each DataFrame should have Zero-shot, Zero-shot-CoT and PS+ as the prompting styles:
dfs[0].prompting_style.unique(),\
dfs[1].prompting_style.unique(),\
dfs[2].prompting_style.unique()(array(['Zero-shot', 'Zero-shot-CoT', 'PS+'], dtype=object),
array(['Zero-shot', 'Zero-shot-CoT', 'PS+'], dtype=object),
array(['Zero-shot', 'Zero-shot-CoT', 'PS+'], dtype=object))Finally, I’ll create a dictionary to lookup the instruction for a given prompting style, to append to the question in the prompt:
instructions = {
'Zero-shot': 'The answer is',
'Zero-shot-CoT': "Let's think step by step.",
'PS+': "Let’s first understand the problem, extract relevant variables and their corresponding numerals, and devise a plan. Then, let’s carry out the plan, calculate intermediate results (pay attention to calculation and common sense), solve the problem step by step, and show the answer."
}instructions['PS+']'Let’s first understand the problem, extract relevant variables and their corresponding numerals, and devise a plan. Then, let’s carry out the plan, calculate intermediate results (pay attention to calculation and common sense), solve the problem step by step, and show the answer.'With my DataFrames with questions and prompting styles ready, I can prompt the models one at a time. The Kaggle GPUs were running out of memory if I tried to load more than one of these models, so I have to create a new session for each model run. I export the model responses into a CSV before stopping the session so I can combine all models’ responses into one DataFrame at the end to analyze the results.
Mistral-7B-Instruct-v0.1
pipe = pipeline(
"text-generation",
model="mistralai/Mistral-7B-Instruct-v0.1",
torch_dtype=torch.bfloat16,
device_map="auto")for i in range(len(dfs[0])):
messages = [
{"role": "user", "content": "Q: " + dfs[0].question.iloc[i] + "\n\nA: " + instructions[dfs[0].prompting_style.iloc[i]] }
]
pipe.use_default_system_prompt = False
prompt = pipe.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True)
outputs = pipe(
prompt,
do_sample=True,
temperature= 0.1,
max_new_tokens= 2048,
top_p= 0.95,
repetition_penalty= 1.2,
top_k= 50,
return_full_text= False)
dfs[0].response.iloc[i] = outputs[0]["generated_text"]dfs[0].head()| dataset | question | model | prompting_style | response | |
|---|---|---|---|---|---|
| 0 | AQuA | The average wages of a worker during a fortnig... | Mistral-7B-Instruct-v0.1 | Zero-shot | To solve this problem, we need to use the for... |
| 1 | AQuA | If 27 bottles of soda cost A cents, how much w... | Mistral-7B-Instruct-v0.1 | Zero-shot | To convert the number of bottles from one uni... |
| 2 | GSM8K | James decides to run 3 sprints 3 times a week.... | Mistral-7B-Instruct-v0.1 | Zero-shot | To find out how many total meters James runs ... |
| 3 | GSM8K | In a dance class of 20 students, 20% enrolled ... | Mistral-7B-Instruct-v0.1 | Zero-shot | Let's break down this problem step by step:\n... |
| 4 | MultiArith | The school cafeteria ordered 42 red apples and... | Mistral-7B-Instruct-v0.1 | Zero-shot | 33 extra apples.\n\nHere's the reasoning behi... |
dfs[0].to_csv('mistral_responses.csv')zephyr-7b-alpha
pipe = pipeline(
"text-generation",
model="HuggingFaceH4/zephyr-7b-alpha",
torch_dtype=torch.bfloat16,
device_map="auto")for i in range(len(dfs[1])):
messages = [
{"role": "user", "content": "Q: " + dfs[1].question.iloc[i] + "\n\nA: " + instructions[dfs[1].prompting_style.iloc[i]] }
]
pipe.use_default_system_prompt = False
prompt = pipe.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True)
outputs = pipe(
prompt,
do_sample=True,
temperature= 0.7,
max_new_tokens= 1024,
top_p= 0.95,
repetition_penalty= 1.2,
top_k= 50,
return_full_text= False)
dfs[1].response.iloc[i] = outputs[0]["generated_text"]dfs[1].head()| dataset | question | model | prompting_style | response | |
|---|---|---|---|---|---|
| 0 | AQuA | The average wages of a worker during a fortnig... | zephyr-7b-alpha | Zero-shot | The total earnings for the first seven days ar... |
| 1 | AQuA | If 27 bottles of soda cost A cents, how much w... | zephyr-7b-alpha | Zero-shot | (A) AB/2700 \n\nExplanation: Let's say the pri... |
| 2 | GSM8K | James decides to run 3 sprints 3 times a week.... | zephyr-7b-alpha | Zero-shot | James runs 3 sprints of 60 meters each, three ... |
| 3 | GSM8K | In a dance class of 20 students, 20% enrolled ... | zephyr-7b-alpha | Zero-shot | Let's calculate this using math:\n\nFirstly, l... |
| 4 | MultiArith | The school cafeteria ordered 42 red apples and... | zephyr-7b-alpha | Zero-shot | Let's calculate the total number of apples (re... |
dfs[1].to_csv('zephyr_responses.csv')Llama-2-7b-chat-hf
pipe = pipeline(
"text-generation",
model="meta-llama/Llama-2-7b-chat-hf",
torch_dtype=torch.bfloat16,
device_map="auto")for i in range(len(dfs[2])):
messages = [
{"role": "user", "content": "Q: " + dfs[2].question.iloc[i] + "\n\nA: " + instructions[dfs[2].prompting_style.iloc[i]] }
]
pipe.use_default_system_prompt = False
prompt = pipe.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True)
outputs = pipe(
prompt,
do_sample=True,
temperature= 0.1,
max_new_tokens= 1024,
top_p= 0.95,
repetition_penalty= 1.2,
top_k= 50,
return_full_text= False)
dfs[2].response.iloc[i] = outputs[0]["generated_text"]dfs[2].head()| dataset | question | model | prompting_style | response | |
|---|---|---|---|---|---|
| 0 | AQuA | The average wages of a worker during a fortnig... | Llama-2-7b-chat-hf | Zero-shot | To find the wage of the worker on the 8th da... |
| 1 | AQuA | If 27 bottles of soda cost A cents, how much w... | Llama-2-7b-chat-hf | Zero-shot | To find the cost of B bottles in dollars, we... |
| 2 | GSM8K | James decides to run 3 sprints 3 times a week.... | Llama-2-7b-chat-hf | Zero-shot | To find out how many total meters James runs... |
| 3 | GSM8K | In a dance class of 20 students, 20% enrolled ... | Llama-2-7b-chat-hf | Zero-shot | To find out what percentage of the entire gr... |
| 4 | MultiArith | The school cafeteria ordered 42 red apples and... | Llama-2-7b-chat-hf | Zero-shot | Great question! To find out how many extra a... |
dfs[2].to_csv('llama2_responses.csv')Grading the Responses
I really liked the way Johnathan Whitaker (on the Data Science Castnet YouTube channel) used gradio as a tool to check responses from an LLM, so I’m using the approach from his notebook below.
For each row of data, the gradio app displays the question, response and two buttons (“Correct” and “Incorrect”). If the answer is correct, I’ll press “Correct” and the is_correct column value will be set to 1. If it’s not, I’ll press “Incorrect” and is_correct will stay 0.
#install gradio (quick fix for install error on colab)
import locale
locale.getpreferredencoding = lambda: "UTF-8"
!pip install -q gradioI’ll load the three CSVs (each with responses for 3 prompting styles across 20 questions from each model) into a single DataFrame, and sort it by the question column so it’s easier for me to grade the responses.
import gradio as gr, pandas as pd
from functools import partial
dfs = []
files = ['llama2_responses.csv', 'mistral_responses.csv', 'zephyr_responses.csv']
for file in files:
df = pd.read_csv(file)
df = df.drop('Unnamed: 0', axis=1)
df['is_correct'] = 0
dfs.append(df)
df = pd.concat(dfs, axis=0, ignore_index=True)
# sort by question so it's easier to grade
df = df.sort_values(by=['question'])
df = df.reset_index(drop=True)df.head()| dataset | question | model | prompting_style | response | is_correct | |
|---|---|---|---|---|---|---|
| 0 | Coin Flip | 'A coin is heads up. Lorena does not flip the ... | zephyr-7b-alpha | PS+ | Problem understanding:\n- The question asks wh... | 0 |
| 1 | Coin Flip | 'A coin is heads up. Lorena does not flip the ... | zephyr-7b-alpha | Zero-shot | Yes, according to the given scenario, since no... | 0 |
| 2 | Coin Flip | 'A coin is heads up. Lorena does not flip the ... | Llama-2-7b-chat-hf | Zero-shot | No, the coin is no longer heads up. Since no... | 0 |
| 3 | Coin Flip | 'A coin is heads up. Lorena does not flip the ... | Mistral-7B-Instruct-v0.1 | Zero-shot | Yes, the coin is still heads up.\n\nHere's th... | 0 |
| 4 | Coin Flip | 'A coin is heads up. Lorena does not flip the ... | Llama-2-7b-chat-hf | PS+ | Great! Let's tackle this problem together. H... | 0 |
The gradio app consists of a Textbox which will display the text of the question and response. I’ll modify the existing get_text function, which takes an index and returns a concatenated string.
The label function is called when the user clicks either of the buttons. If the button clicked has a value of "Correct" then the choice parameter will be "correct" and the is_correct column will be set to 1. The label function returns the next index and string to display.
def get_text(idx):
""" Combine the question and answer into a single string """
global df
text = 'Q: ' + df.iloc[idx]['question'] + '\n\nA: ' + df.iloc[idx]['response']
return text
def label(idx, choice='correct'):
""" Set `is_correct` column to `1` if response is correct """
if choice == 'correct':
df.loc[idx, 'is_correct'] = 1
return idx+1, get_text(idx+1) # Move on to next oneIn order to avoid the gradio app from timing out, I have called queue on the demo object before I launch it.
with gr.Blocks() as demo:
starting_idx = 0
with gr.Column():
idx = gr.Slider(value=starting_idx, label="idx") # Progress bar, borrowed the idea from https://www.kaggle.com/code/nbroad/create-science-wikipedia-dataset
text = gr.Textbox(value=get_text(0), label="text")
with gr.Row():
correct_btn = gr.Button(value="Correct")
incorrect_btn = gr.Button(value="Incorrect")
correct_btn.click(fn=partial(label, choice='correct'), inputs=[idx], outputs=[idx, text])
incorrect_btn.click(fn=partial(label, choice='incorrect'), inputs=[idx], outputs=[idx, text])
#demo.launch(debug=True, show_error=True)
demo.queue().launch(share=True, show_error=True)Here is an example of what the gradio app looks like:
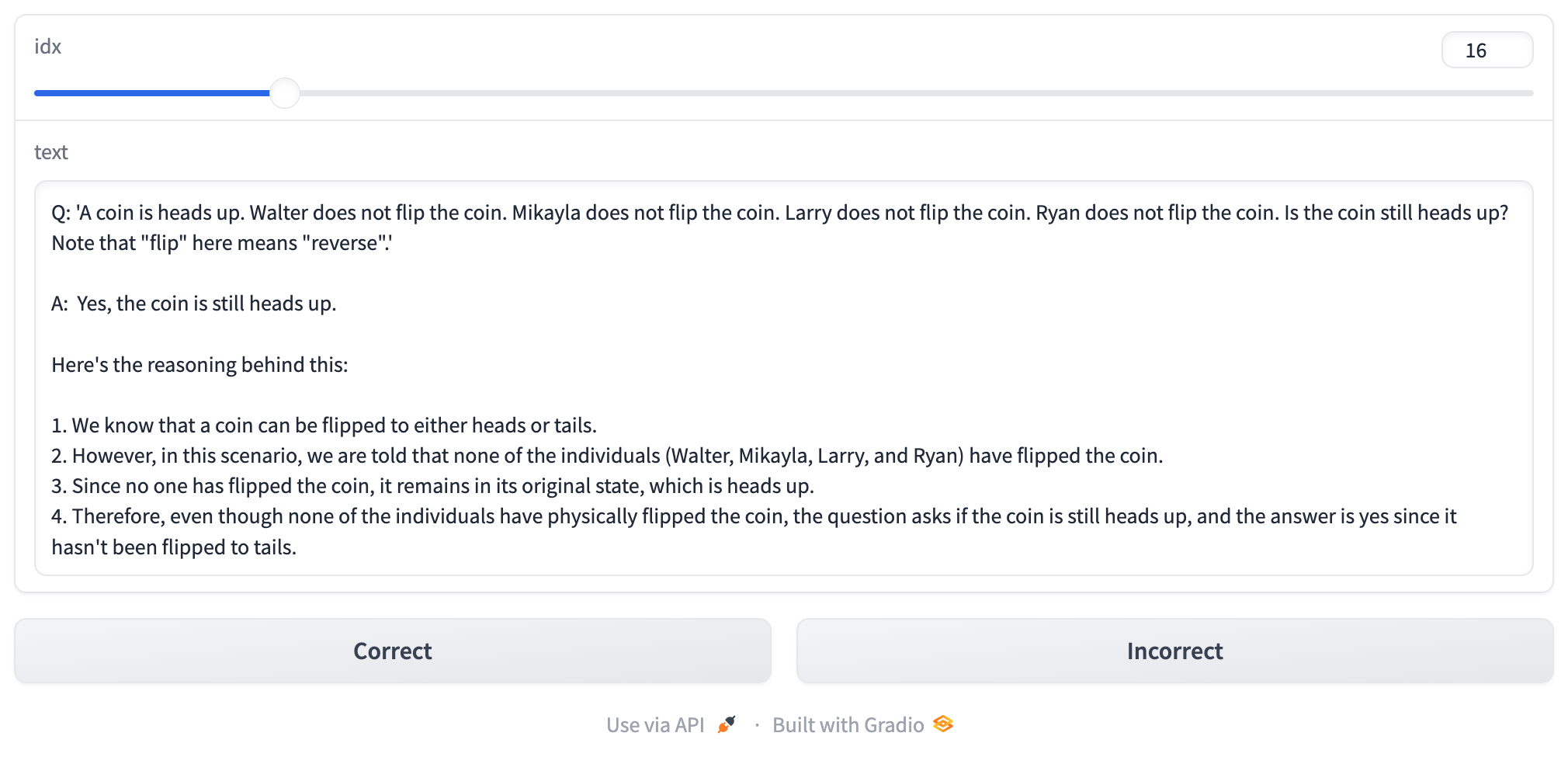
df.to_csv('graded_responses.csv', index=False)Results
With all of the model responses graded, I can now calculate the percentage of correct responses from each model for each dataset and prompting style.
df.groupby(['model', 'prompting_style'])['is_correct'].mean() * 100model prompting_style
Llama-2-7b-chat-hf PS+ 25.0
Zero-shot 45.0
Zero-shot-CoT 30.0
Mistral-7B-Instruct-v0.1 PS+ 60.0
Zero-shot 60.0
Zero-shot-CoT 45.0
zephyr-7b-alpha PS+ 30.0
Zero-shot 45.0
Zero-shot-CoT 45.0
Name: is_correct, dtype: float64Overall, the best performing model and prompting style (60% correct) was the Mistral-7B-Instruct-v0.1 model using the PS+ and Zero-shot prompting styles. Mistral was the only model where PS+ outperformed Zero-shot and Zero-shot-CoT.
df.groupby(['model'])['is_correct'].mean() * 100model
Llama-2-7b-chat-hf 33.333333
Mistral-7B-Instruct-v0.1 55.000000
zephyr-7b-alpha 40.000000
Name: is_correct, dtype: float64Overall the best performing model across all prompting styles was Mistral (55%) following by Zephyr (40%) and Llama-2 coming in last at 33.33%.
df.groupby(['dataset'])['is_correct'].mean() * 100dataset
AQuA 5.555556
AddSub 77.777778
CSQA 27.777778
Coin Flip 77.777778
GSM8K 50.000000
Last Letters 0.000000
MultiArith 38.888889
SVAMP 77.777778
SingleEq 72.222222
StrategyQA 0.000000
Name: is_correct, dtype: float64Across all models and prompting styles, the highest performing datasets (78% correct) were AddSub, Coin Flip and SVAMP. The lowest performing datasets (0% correct) were Last Letters and StrategyQA.
Final Thoughts
I want to reiterate that the purpose of this exercise for me to get some practice prompting LLMs. I also got some experience setting up a gradio app to help me evaluate the responses of the models.
Given the small sample size for each model (20 questions and responses for each prompting style) I don’t think these results can be used to conclude anything about the performance of these prompting styles and models. Yes, Mistral and Zephyr out-performed Llama-2 on these 20 questions across these 3 particular prompting styles, but testing the models on another thousand questions might yield different results.
I hope you enjoyed this blog post!