Paper Summary: Training Data for the Price of a Sandwich
In this blog post I’ll summarize what I learned from the paper Training Data for the Price of a Sandwich: Common Crawl’s Impact on Generative AI by Stefan Baack and Mozilla Insights. This blog post originally started as a presentation I gave to the cluster-of-stars fastai study group–I have reformatted it to a more narrative style. I have also added more detail and context, as well as my reactions and ponderings.
This blog post is split up into seven sections, closely following the paper’s structure:
- What is Common Crawl (referred to as CC)
- CC’s use in Generative AI
- CC’s Mission
- CC’s Data
- Filtering CC for AI
- CC and Trustworthy AI
A couple of terms that may need to be defined for some readers:
- LLM = Large Language Model. A model with a lot of parameters (like an equation with lots of variables) that can predict the next word in a sentence (generally speaking).
- document = a word, sentence, file, book, webpage, or any sequence of text that is used to train a language model.
What is Common Crawl (CC)?
CC is a small (3-ish employees) nonprofit organization providing 9.5+ petabytes of freely available archive of web crawl data dating back to 2008 (250 billion web pages), with 3 to 5 billions pages added each month.
This data is not a single dataset. Instead, it’s offered as individual crawls of varying sizes. The data is extremely popular, cited in over 10,000 papers.
A key point that will come up again throughout this paper is that CC data is not a representative sample of the internet. More on that later.
CC use in Generative AI
One of the most impactful concepts in this paper was that of infrastructure as contrasted with data.
Media studies scholar Luke Munn says:
One of the things that make infrastructures so powerful is that they model their own ideals. They privilege certain logics and then operationalize them. And in this sense… they both register wider societal values and establish blueprints for how they should be carried out.
CC has an infrastructural role within generative AI R&D: it provides a basis from which AI builders create training datasets. Its data is never used directly, instead, AI builders filter CC data before using it in training.
CC data is primarily used for pre-training a model, meaning when an architecture is fed data in order to predict the next token in a sequence of tokens. During this phase, we expect the model to store patterns or associations between words in a language (like English) in the sense that given an English word or subword, it can predict the next word or subword that in a grammatically sensible way. For example, if the model is prompted “the bird is” after being pre-trained on sensible data it will likely predict the next word to be “red” or “hungry” or something sensible. This is contrasted with fine-tuning where a model that can generally predict the next token sensibly is then trained on domain-specific data to predict the next token of a particular domain (such as ornithology, the study of birds). So, if a model fine-tuned on ornithological data is prompted “a group of ravens is called” it will hopefully predict the next word as “unkindness.”
82% of the GPT-3 tokens are from CC. More accurately speaking (see below) 60% of the training data seen by GPT-3 is from CC.
From Brown et al. 2020:
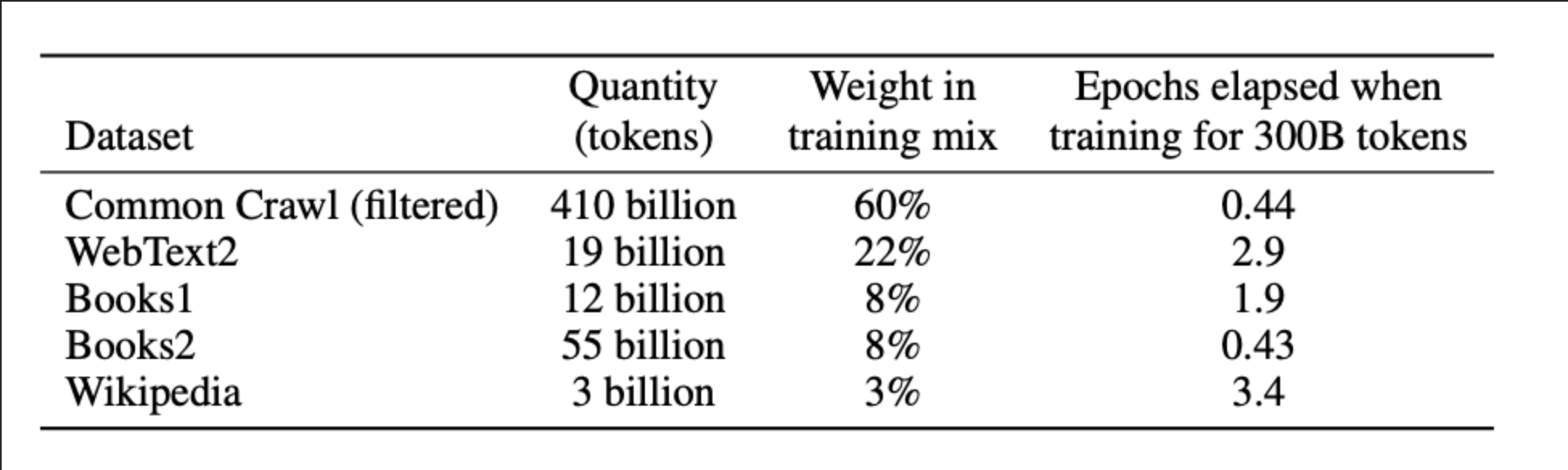
More boradly speaking, of the 47 LLM papers between 2019-2023 reviewed by Stefan and Mozilla Insights, 64% used filtered CC data. The top 5-most used filtered datasets were:
CC’s Mission
CC’s stated mission is to provide:
high quality crawl data that was previously only available to large search engine corporations [to] small startups or even individuals
Founder Gil Elbaz said in an interview (emphasis mine):
I felt like a world where many companies are bringing innovation forth, across the world…is ultimately the world that I want to live in. I started to think about creating a neutral data company…that wants to democratize access to information to provide data to other companies
Its guiding principle is that less curation of the provided data enables more research and innovation by downstream users.
The authors revisit this mission later on when discussing the relationship between CC and trustworthy AI.
CC’s Data
Overview
CC aims to support “machine scale analysis” which means automated, large-scale analysis of web data across web domains, as opposed to human scale analysis where a person (or many people) ingests information with their senses and then processes and analyzes it with their brain.
How does CC pick which parts of the internet to crawl? CC data consists of samples of URLs from web domains sampled from the CrawlDB, which stores 25+ billion URLs (as well as a score for each URL, when it was last fetches, whether it was successfully crawled and other fields).
CC contains three types of data (see this site for examples) - WARC (WebARChive) files which store the raw crawl data (HTML code) - WAT (Web Archive Transformation) files which store computed metadata for the data stored in the WARC - WET (WARC Encapsulated Text) files which store extracted plaintext from the data stored in the WARC
The CC crawling process is designed to automatically find (a pre-defined maximum number of) new URLs considered good quality CC thinks of “quality” in terms of how CC’s data represents the web as a whole as well as the quality of the URLs included in the crawls.
The uncertainty of CC about how their data reflects the web as a whole is due to not knowing the size of the web as a whole. As one of CC’s staff put it:
the web is practically infinite.
Earlier they mentioned that 3 to 5 billion URLs are added each month. Why not more? Because there is a tradeoff between the size of a crawl and the quality of the crawl. To expand the size of the crawl they have to include lower quality URLs, and many lower quality URLs are spam. Crawlers can get stuck in “crawler traps” which are these pockets of the internet where spam URLs are directed to one another. If a crawler gets stuck in there, potentially a majority of the crawled URLs can be spam, and the crawl data contains spammy content.
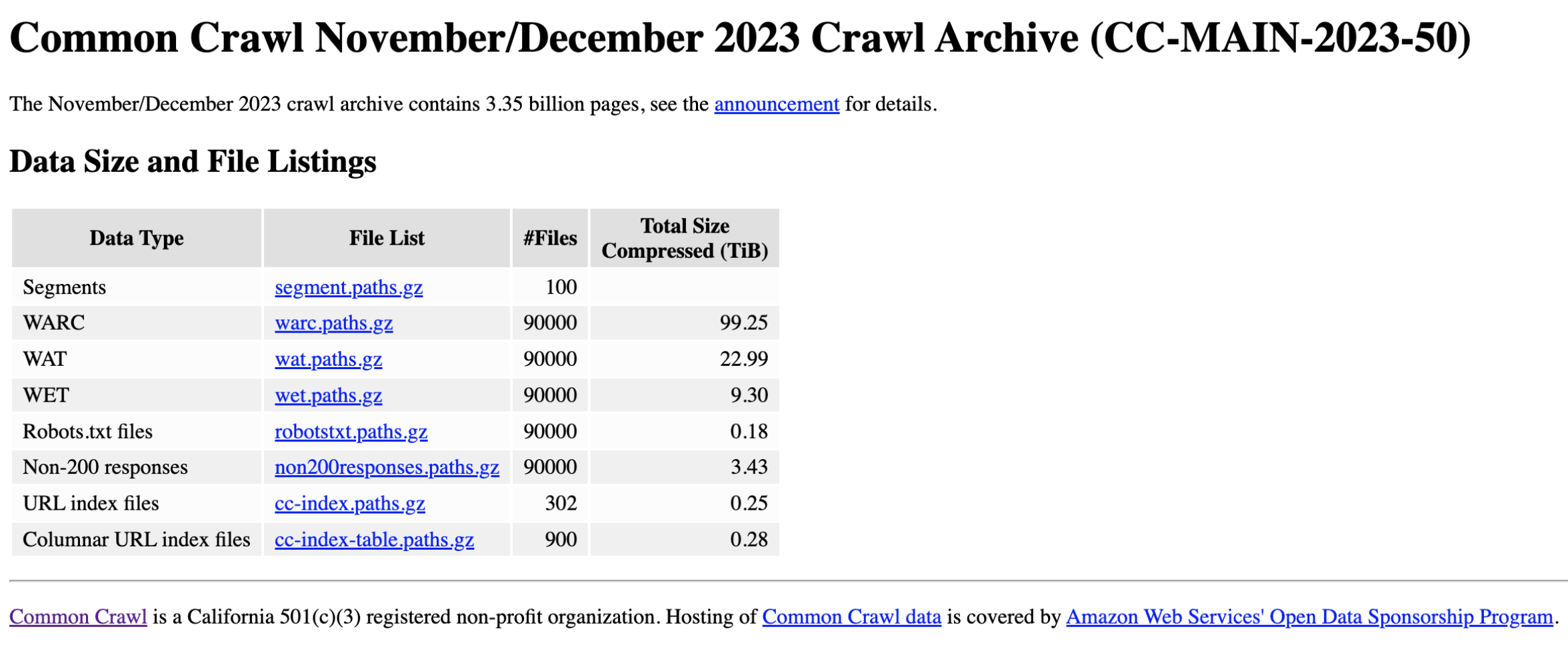
Here’s a screenshot of information of a CC main crawl (1 TiB = 2^40 bytes, around 1100 GB):
Here is a list of all their main crawls.
CrawlDB
URLs are added to CrawlDB during main crawls, discovery crawls (crawls with the sole purpose of fetching more URLs), and sitemap analyses.
a Sitemap is an XML file that lists URLs for a site along with additional metadata about each URL (when it was last updated, how often it usually changes, and how important it is, relative to other URLs in the site)
Harmonic Centrality Score
How are URLs scored? and thereby sampled to include in the next crawl? With the Harmonic Centrality Score.
The Harmonic Centrality Score measures the importance of a node in a network based on its distance all other nodes. - Shorter distance = higher score. - More direct and indirect links to a domain = higher score. - Captures how accessible a domain is to other web pages.
“High quality” implies a higher Harmonic Centrality Score. The score for a URL is increased if the URL has never been crawled before or hasn’t been crawled in awhile.
Filtering CC for AI
As mentioned earlier, AI builders filter CC data before using it to pre-train their models. This section goes into more detail around filtering.
Types of filtering
- By language (most of CC data is in English)
- Keywords or simple heuristics (only keep lines that end in a punctuation mark, or remove documents with certain keywords)
- The List of Dirty, Naughty, Obscene, and Otherwise Bad Words used for C4 dataset is problematic because the words included in that list are not inherently “bad” or “harmful”. It depends on context. For example, here are some words included in this list of “bad words” that are not “bad” given a particular context:
- “domination” (filtering out webpages that have the word “domination” will exclude pages with a discussion about domination of one group or system on another)
- “sexuality” and similar terms are of course normal and healthy words to use in many contexts.
- anatomical words (“penis”, “vagina”, “clitoris”, “vulva”) are all perfectly “good” words in many contexts. Furthermore, the censorship of female sexuality is perpetuated by the inclusion of those words in this “bad word” list.
- slurs reclaimed by racial and gender/sex minorities are used in non-derogatory ways in their communities and cultures—exluding these words excludes their representation in the data.
- The List of Dirty, Naughty, Obscene, and Otherwise Bad Words used for C4 dataset is problematic because the words included in that list are not inherently “bad” or “harmful”. It depends on context. For example, here are some words included in this list of “bad words” that are not “bad” given a particular context:
- AI classifiers (only keeps documents statistically similar to reference dataset)
- Pile-CC (EletheurAI) uses an AI classifier trained on OpenWebText2 (deduplicated Reddit comments with 3+ upvotes). Most Reddit users are male and white so this is not a representative dataset of the global population. Reddit has also struggled moderating toxicity.
- GPT-3 is pre-trained on CC filtered by using a classifier trained on WebText as a proxy for “high-quality” documents. Documents that are similar to WebText are deemed “low quality”.
- Deduplication (remove one document if it is exactly he same or similar to another—“similar” in a statistical sense)
- GPT-3 is pre-trained on CC data that was filtered to remove documents with high overlap with other documents (fuzzy deduplication).
(In)adequacy of Filtering Methods
There is a fundamental unresolved conflict or dilemma: the amount of data desired is too large for manual curation but automated filtering for toxicity and bias are significantly limited. The authors discuss solutions to this later on.
CC and Trustworthy AI
Mozilla defines Trustworthy AI is AI that is:
demonstrably worthy of trust, tech that considers accountability, agency, and individual and collective well-being…[trustworthy] AI-driven products and services are designed with human agency and accountability from the beginning
What stood out to me from this definition were the terms accountability, agency and well-being.
Upside of CC
The filtered CC versions used in LLM training are inherently more auditable than any proprietary training datasets because CC data is freely accessible online.
LLMs open and transparent about their data typically come from outside of Big Tech (e.g., Bloom), achieving CC’s mission of making this data accessible to small startups and individuals.
Downsides of CC
While filtered CC data is more auditable than proprietary datasets, AI builders don’t necessarily take the opportunity to be transparent about their CC use. In other words, what use is this auditability if how this freely accessible data is filtered is not disclosed?
The size and diversity of CC makes it hard to understand what an LLM is trained on. This is reinforced by the (false) assumption among some AI builders that CC represents the “entire internet” and somehow is a proxy for representing “all human knowledge”. CC staff explicitly state:
Often it is claimed that Common Crawl contains the entire web, but that’s absolutely not true. Based on what I know about how many URLs exist, it’s very, very small.
Training of generative AI on massive amounts of copyrighted material could trend towards making the internet less open and collaborative (“data revolts”: when content platforms block crawlers to protect their data). Note that CC stays within the bounds of US fair use policy for copyrighted materials. It only copies HTML code, no images or media or full copies of domains.
Here’s an example of how content platforms block crawlers, from NY Times’ robot.txt:
User-agent: CCBot
Disallow: /Recommendations for using CC to train AI
- Put more effort into filtering CC. Filter more types of problematic content (e.g., content that is racist or mysoginist).
- Problematic content should be annotated (if it’s not filtered out). There are some models who are trained on problematic content in order to better detect it. These models will need to be trained on problematic data.
- Consistently provide proper dataset documentation. (See “Dataset Audit Card” example on page 7 of Large Datasets: A Pyrrhic Win for Computer Vision?)
Recommendations for LLM-based end-user products
- Better industry standards and government regulation for evaluating filtered CC versions and downstream model effects.
- More nuanced, culturally contextual tools to evaluate profanity, racism, discrimination, etc. found in the datasets.
- A descriptive demographic overview of the dataset content (e.g., what region and culture does this data represent?)
- Evaluations by human moderators under fair, safe conditions (‘It’s destroyed me completely’: Kenyan moderators decry toll of training of AI models).
- Evaluating the effects of individual datasets on model behavior (like EletheurAI’s Language Model Evaluation Harness).
- Trustworthy intermediaries who filter CC for various purposes (e.g., subject matter experts or cultural experts who can curate data to match their subject or culture appropriately).
The Future of CC
CC’s Shortcomings
- CC is not a “neutral data” organization as its samples are not representative of the web and because the web is not representative of all people (about 40% or 3 billion people in the world do not have internet access). I would go further and say that there is no such thing as neutral data, even raw data is not neutral because data collection, and the environment within which data is collected is not neutral.
- CC’s lack of transparency (around its data governance) is at odds with its self-image as a public resource. For a long time, there was almost no public communication from CC outside of its mailing list (which mostly dealt with technical questions) and its blog (mostly dedicated to announcing new crawl data).
Recommendations for CC
- Add a Terms of Use to the data. If AI builders want to use your data, they should have to document their filtering methodology, and take approaches to better filter (or annotate) their data for problematic, biased and harmful content.
- CC should conduct more curated, values-oriented crawls so that digitally marginalized communities are more included. Since a URL’s quality is determined by its Harmonic Centrality Score, and since that score is determined by how accessible the URL is to other URLs, URLs from communities without socioeconomic power and/or resources will not be deemed “accessible” as such and will be scored low. Additionally, many communities will post popular links to Facebook, but because it doesn’t allow crawlers, CC won’t get to see that URL.
- Add a community-driven approach to identify relevant content for crawls. Let the people themselves tell you directly what content matters to them and represents their interests and cultures.
- Provide quality and toxicity evaluations, or language labeling.
- Create a formal way to make requests about crawls.
- Provide educational resources about the limitations of CC data.
- Foster discussions of filtering and data analysis tools.
- Increase the number and diversity of high-quality datasets curated by humans equitably. In other words, it’s okay if these datasets are small if they are high quality and there are a lot of them.
Final Thoughts
I really enjoyed this paper. I came away from it inspired and empowered. If we can put our heads together and expand the filtered CC data space to include more intentional and representative data about cultures, topics and ideologies that are either ignored or filtered out in the most popular datasets today, we can reshape how LLMs predict the next token.
As always, I hope you enjoyed this blog post!