Improving Kaggle Private Score with Multi-Target Classification
deep learning
fastai
kaggle competition
paddy doctor
python
In this notebook I apply Jeremy Howard’s approach to multi-target classification in fastai to improve a Kaggle submission score.
Author
Vishal Bakshi
Published
May 15, 2024
Background
In this notebook, I’ll use the code from Jeremy’s Road to the Top, Part 4 notebook to train a model that classifies both the disease and the variety of the rice paddy. In the fastai course Part 1 Lesson 7 video, Jeremy encourages viewers/students to see how this model scores and to explore the inputs and outputs in order to understand how the model behaves. I’ll do just that in this notebook.
There are 10 unique labels (including normal) and 10 unique variety values. This means the model will have to predict 10 + 10 = 20 different probabilities.
Jeremy creates a get_variety helper function which returns the variety column value for a given image path. Note that when he created df, he passes index_col='image_id' in order to make the index of that DataFrame the image path for easier lookup.
Jeremy’s DataBlock consists of three blocks—one ImageBlock that processes the inputs and two CategoryBlocks, one per target (label and variety). Because there are three blocks we have to specify that the number of inputs, n_inp is 1. Note that we can specify a list of get_y getters, one for each target.
As done in his notebook, I’ll first test this approach by training a single-target classifier for disease label. Since there are three blocks, the loss function and metrics will receive three things: the predictions (inp), the disease labels and the variety labels.
tst_files = get_image_files(path/'test_images')tst_files.sort()tst_dl = dls.test_dl(tst_files)probs = learn.tta(dl=tst_dl)# get the index (class) of the maximum prediction for each itemidxs = probs[0].argmax(dim=1)# convert indexes to vocab stringsmapping =dict(enumerate(dls.vocab))# add vocab strings to sample submission file and export to CSVss = pd.read_csv(path/'sample_submission.csv')results = pd.Series(idxs.numpy(), name='idxs').map(mapping)ss.label = resultsss.to_csv('subm2.csv', index=False)!head subm2.csv
Jeremy picks the first ten activations of the model as the disease classes and the second ten as the variety classes. The disease_loss and variety_loss are defined accordingly:
Downloading: "https://download.pytorch.org/models/resnet34-b627a593.pth" to /root/.cache/torch/hub/checkpoints/resnet34-b627a593.pth
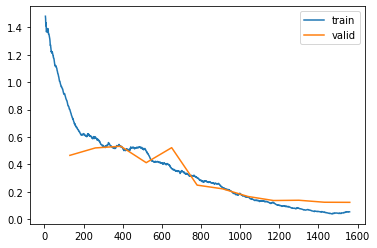
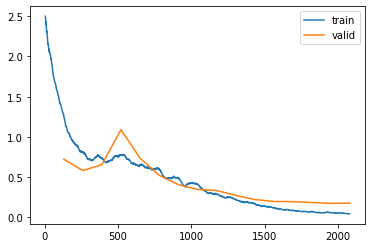
Jeremy mentioned that we might have to train this model for longer before it performs as well as the single-target model since we are asking to do more (predicts twice the number of targets). I’ll train and submit with 12 epochs first as a baseline.
learn.fine_tune(12, 0.01)
epoch
train_loss
valid_loss
disease_err
variety_err
disease_loss
variety_loss
time
0
3.191633
1.969826
0.419990
0.219125
1.272959
0.696868
01:19
epoch
train_loss
valid_loss
disease_err
variety_err
disease_loss
variety_loss
time
0
1.266333
0.694686
0.154733
0.059106
0.489899
0.204788
01:06
1
0.887806
0.605122
0.146564
0.053340
0.440036
0.165086
01:06
2
0.834215
1.014124
0.188371
0.090341
0.617206
0.396918
01:06
3
0.709637
0.634970
0.117732
0.058145
0.439491
0.195479
01:06
4
0.587873
0.580158
0.120135
0.045651
0.420883
0.159275
01:06
5
0.453230
0.404975
0.084575
0.031716
0.295974
0.109001
01:06
6
0.332355
0.315852
0.069678
0.017780
0.252630
0.063222
01:07
7
0.240017
0.276671
0.054781
0.025469
0.197499
0.079172
01:07
8
0.166121
0.182990
0.039885
0.012494
0.140265
0.042726
01:06
9
0.112039
0.182566
0.036040
0.011533
0.138646
0.043920
01:06
10
0.081297
0.177871
0.034599
0.008650
0.136665
0.041206
01:06
11
0.074365
0.173486
0.031716
0.008650
0.133155
0.040331
01:06
probs = learn.tta(dl=learn.dls.valid)
There are 20 predictions for each image.
probs[0].shape
torch.Size([2081, 20])
The first 10 predictions are for the disease label.
The model is much more accurate at predicting the variety of rice.
I’ll submit TTA predictions on the test set:
tst_files = get_image_files(path/'test_images')tst_files.sort()tst_dl = dls.test_dl(tst_files)probs = learn.tta(dl=tst_dl)# get the index (class) of the maximum prediction for each itemidxs = probs[0][:,:10].argmax(dim=1)# convert indexes to vocab stringsmapping =dict(enumerate(dls.vocab[0]))# add vocab strings to sample submission file and export to CSVss = pd.read_csv(path/'sample_submission.csv')results = pd.Series(idxs.numpy(), name='idxs').map(mapping)ss.label = resultsss.to_csv('subm3.csv', index=False)!head subm3.csv
That’s a slightly better TTA validation error rate.
tst_files = get_image_files(path/'test_images')tst_files.sort()tst_dl = dls.test_dl(tst_files)probs = learn.tta(dl=tst_dl)# get the index (class) of the maximum prediction for each itemidxs = probs[0][:,:10].argmax(dim=1)# convert indexes to vocab stringsmapping =dict(enumerate(dls.vocab[0]))# add vocab strings to sample submission file and export to CSVss = pd.read_csv(path/'sample_submission.csv')results = pd.Series(idxs.numpy(), name='idxs').map(mapping)ss.label = resultsss.to_csv('subm4.csv', index=False)!head subm4.csv
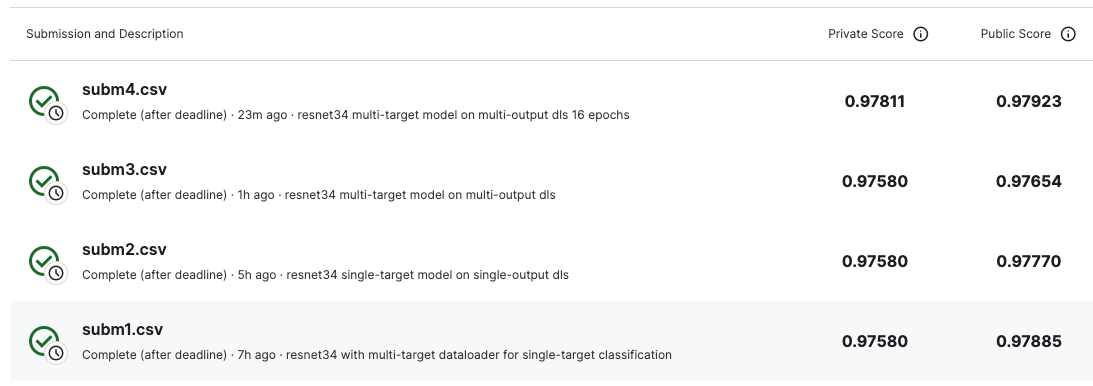
The Private scored improved to 0.97811! That’s not insignificant. Training on multi-target, at least for a resnet34 on the Resize(192, method='squish') item transform and aug_transforms(size=128, min_scale=0.75) batch transform. Here is the summary of the four submissions from this notebook:
Final Thoughts
I am so glad that I ran this experiment since I am currently involved in a Kaggle competition where I was considering multi-target classification. There’s no certainty that it’ll improve my Private score in that situation, but it’s promising to see it improve the Paddy Disease Classification Private score here. Many thanks to Jeremy for introducing us to these engaging concepts.