tok_ds[0]['input']'According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .'financial_phrasebank Datasetfinancial_phrasebank dataset and achieve 74%+ accuracy on the validation and test set.
In a previous blog post I finetuned the TinyStories-33M and the TinyStories-8M model on the financial_phrasebank dataset and achieved the following results:
| Arch | Fine-tuning Learning Rate | Best Val Acc | Best Test Acc |
|---|---|---|---|
| TinyStories-33M | 5e-04 | 86% | 79% |
| TinyStories-8M | 8e-05 | 85% | 86% |
| TinyStories-8M | 5e-04 | 79% | 86% |
In this notebook, I’ll finetune the smaller TinyStories-3M model and see how it performs. I also suspect these smaller models might perform better on a (synthetically generated) simpler version of this dataset, which I plan to explore in a future notebook.
::: {#cell-3 .cell _cell_guid=‘b1076dfc-b9ad-4769-8c92-a6c4dae69d19’ _kg_hide-input=‘false’ _kg_hide-output=‘false’ _uuid=‘8f2839f25d086af736a60e9eeb907d3b93b6e0e5’ trusted=‘true’}
from datasets import load_dataset
from transformers import AutoModelForSequenceClassification, AutoTokenizer, TrainingArguments, Trainer, TrainerCallback
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn.functional as F
import gc
def report_gpu():
print(torch.cuda.list_gpu_processes())
gc.collect()
torch.cuda.empty_cache()
#model_nm = "roneneldan/TinyStories-33M"
#model_nm = "roneneldan/TinyStories-1M"
model_nm = "roneneldan/TinyStories-3M"
#model_nm = "roneneldan/TinyStories-8M"
tokz = AutoTokenizer.from_pretrained(model_nm)
def tok_func(x): return tokz(x["input"], padding=True, truncation=True):::
Much of the code in this section is boilerplate, tokenizing the dataset and splitting it into training, validation and test sets.
::: {#cell-6 .cell _kg_hide-input=‘false’ trusted=‘true’}
dataset = load_dataset(
"financial_phrasebank", "sentences_allagree",
split="train" # note that the dataset does not have a default test split
)
dataset = dataset.rename_columns({'label':'labels', 'sentence': 'input'}):::
::: {#cell-7 .cell _kg_hide-input=‘false’ trusted=‘true’}
tokz.add_special_tokens({'pad_token': '[PAD]'})
tokz.padding_side = "left" # https://github.com/huggingface/transformers/issues/16595 and https://www.kaggle.com/code/baekseungyun/gpt-2-with-huggingface-pytorch
tok_ds = dataset.map(tok_func, batched=True):::
tok_ds[0]['input']'According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .'tok_ds[0]['input_ids'][100:110] # first 100 elements are 50257 ('[PAD]')[50257, 50257, 50257, 50257, 50257, 50257, 4821, 284, 17113, 837]tokz.decode(50257), tokz.decode(4821), tokz.decode(284), tokz.decode(17113)('[PAD]', 'According', ' to', ' Gran')tok_ds[0]['labels']1::: {#cell-12 .cell _kg_hide-input=‘false’ quarto-private-1=‘{“key”:“execution”,“value”:{“iopub.execute_input”:“2024-08-23T01:41:38.808024Z”,“iopub.status.busy”:“2024-08-23T01:41:38.807754Z”,“iopub.status.idle”:“2024-08-23T01:41:38.845469Z”,“shell.execute_reply”:“2024-08-23T01:41:38.844522Z”,“shell.execute_reply.started”:“2024-08-23T01:41:38.808000Z”}}’ trusted=‘true’ execution_count=8}
split_dataset = tok_ds.train_test_split(test_size=225/2264, seed=42)
training_split = split_dataset['train'].train_test_split(test_size=0.2, seed=42)
train_ds = training_split['train']
eval_ds = training_split['test']
test_ds = split_dataset['test']
train_ds, eval_ds, test_ds(Dataset({
features: ['input', 'labels', 'input_ids', 'attention_mask'],
num_rows: 1631
}),
Dataset({
features: ['input', 'labels', 'input_ids', 'attention_mask'],
num_rows: 408
}),
Dataset({
features: ['input', 'labels', 'input_ids', 'attention_mask'],
num_rows: 225
})):::
train_ds[0]['input']'The result will also be burdened by increased fixed costs associated with operations in China , and restructuring costs in Japan .'train_ds[0]['labels']0The dataset distributions show a predominance of neutral (1) sentences:
train_ds.to_pandas()['labels'].value_counts() / len(train_ds)labels
1 0.622318
2 0.251993
0 0.125690
Name: count, dtype: float64eval_ds.to_pandas()['labels'].value_counts() / len(eval_ds)labels
1 0.615196
2 0.257353
0 0.127451
Name: count, dtype: float64test_ds.to_pandas()['labels'].value_counts() / len(test_ds)labels
1 0.555556
2 0.240000
0 0.204444
Name: count, dtype: float64Much of the code in this section is either helper functions (like get_acc, MetricCallback, or results_to_dataframe) or boilerplate code to prepare a HuggingFace trainer:
::: {#cell-21 .cell _kg_hide-input=‘false’ quarto-private-1=‘{“key”:“execution”,“value”:{“iopub.execute_input”:“2024-08-23T01:41:38.970265Z”,“iopub.status.busy”:“2024-08-23T01:41:38.969900Z”,“iopub.status.idle”:“2024-08-23T01:41:38.975805Z”,“shell.execute_reply”:“2024-08-23T01:41:38.974762Z”,“shell.execute_reply.started”:“2024-08-23T01:41:38.970237Z”}}’ trusted=‘true’ execution_count=14}
get_acc functiondef get_acc(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return {"accuracy": (predictions == labels).astype(np.float32).mean().item()}:::
::: {#cell-22 .cell _kg_hide-input=‘false’ quarto-private-1=‘{“key”:“execution”,“value”:{“iopub.execute_input”:“2024-08-23T01:41:38.977184Z”,“iopub.status.busy”:“2024-08-23T01:41:38.976868Z”,“iopub.status.idle”:“2024-08-23T01:41:38.997095Z”,“shell.execute_reply”:“2024-08-23T01:41:38.996382Z”,“shell.execute_reply.started”:“2024-08-23T01:41:38.977159Z”}}’ trusted=‘true’ execution_count=15}
MetricCallback function# thanks Claude
class MetricCallback(TrainerCallback):
def __init__(self):
self.metrics = []
self.current_epoch_metrics = {}
def on_log(self, args, state, control, logs=None, **kwargs):
if logs is not None:
self.current_epoch_metrics.update(logs)
def on_epoch_end(self, args, state, control, **kwargs):
if hasattr(state, 'log_history') and state.log_history:
# Get the last logged learning rate
last_lr = state.log_history[-1].get('learning_rate', None)
else:
last_lr = None
self.metrics.append({
"epoch": state.epoch,
"learning_rate": last_lr,
**self.current_epoch_metrics
})
self.current_epoch_metrics = {} # Reset for next epoch
def on_train_end(self, args, state, control, **kwargs):
# Capture final metrics after the last epoch
if self.current_epoch_metrics:
self.metrics.append({
"epoch": state.num_train_epochs,
"learning_rate": self.metrics[-1].get('learning_rate') if self.metrics else None,
**self.current_epoch_metrics
}):::
::: {#cell-23 .cell _kg_hide-input=‘false’ quarto-private-1=‘{“key”:“execution”,“value”:{“iopub.execute_input”:“2024-08-23T01:41:38.998622Z”,“iopub.status.busy”:“2024-08-23T01:41:38.998220Z”,“iopub.status.idle”:“2024-08-23T01:41:39.012673Z”,“shell.execute_reply”:“2024-08-23T01:41:39.011892Z”,“shell.execute_reply.started”:“2024-08-23T01:41:38.998587Z”}}’ trusted=‘true’ execution_count=16}
results_to_dataframe functiondef results_to_dataframe(results, model_name):
rows = []
for result in results:
initial_lr = result['learning_rate']
for metric in result['metrics']:
row = {
'model_name': model_name,
'initial_learning_rate': initial_lr,
'current_learning_rate': metric.get('learning_rate'),
}
row.update(metric)
rows.append(row)
df = pd.DataFrame(rows)
# Ensure specific columns are at the beginning
first_columns = ['model_name', 'initial_learning_rate', 'current_learning_rate', 'epoch']
other_columns = [col for col in df.columns if col not in first_columns]
df = df[first_columns + other_columns]
return df:::
::: {#cell-24 .cell _kg_hide-input=‘false’ quarto-private-1=‘{“key”:“execution”,“value”:{“iopub.execute_input”:“2024-08-23T01:41:39.014245Z”,“iopub.status.busy”:“2024-08-23T01:41:39.013872Z”,“iopub.status.idle”:“2024-08-23T01:41:39.030099Z”,“shell.execute_reply”:“2024-08-23T01:41:39.029259Z”,“shell.execute_reply.started”:“2024-08-23T01:41:39.014211Z”}}’ trusted=‘true’ execution_count=17}
make_cm functiondef make_cm(df):
"""Create confusion matrix for true vs predicted sentiment classes"""
cm = confusion_matrix(y_true=df['label_text'], y_pred=df['pred_text'], labels=['negative', 'neutral', 'positive'])
disp = ConfusionMatrixDisplay(cm, display_labels=['negative', 'neutral', 'positive'])
fig, ax = plt.subplots(figsize=(4,4))
disp.plot(ax=ax,text_kw={'fontsize': 12}, cmap='Blues', colorbar=False);
# change label font size without changing label text
ax.xaxis.label.set_fontsize(16)
ax.yaxis.label.set_fontsize(16)
# make tick labels larger
ax.tick_params(axis='y', labelsize=14)
ax.tick_params(axis='x', labelsize=14):::
::: {#cell-25 .cell _kg_hide-input=‘false’ quarto-private-1=‘{“key”:“execution”,“value”:{“iopub.execute_input”:“2024-08-23T01:41:39.031837Z”,“iopub.status.busy”:“2024-08-23T01:41:39.031456Z”,“iopub.status.idle”:“2024-08-23T01:41:39.044381Z”,“shell.execute_reply”:“2024-08-23T01:41:39.043355Z”,“shell.execute_reply.started”:“2024-08-23T01:41:39.031805Z”}}’ trusted=‘true’ execution_count=18}
get_prediction functiondef get_prediction(model, text, tokz):
# Determine the device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Move the model to the appropriate device
model = model.to(device)
# Tokenize the input text
inputs = tokz(text, return_tensors="pt", truncation=True, padding=True)
# Move input tensors to the same device as the model
inputs = {k: v.to(device) for k, v in inputs.items()}
# Get the model's prediction
model.eval() # Set the model to evaluation mode
with torch.no_grad():
outputs = model(**inputs)
# Ensure logits are on CPU for numpy operations
logits = outputs.logits.detach().cpu()
# Get probabilities
probs = torch.softmax(logits, dim=-1)
# Get the predicted class
p_class = torch.argmax(probs, dim=-1).item()
# Get the probability for the predicted class
p = probs[0][p_class].item()
labels = {0: "negative", 1: "neutral", 2: "positive"}
print(f"Probability: {p:.2f}")
print(f"Predicted label: {labels[p_class]}")
return p_class, p:::
::: {#cell-26 .cell _kg_hide-input=‘false’ quarto-private-1=‘{“key”:“execution”,“value”:{“iopub.execute_input”:“2024-08-23T01:41:39.045837Z”,“iopub.status.busy”:“2024-08-23T01:41:39.045528Z”,“iopub.status.idle”:“2024-08-23T01:41:39.062039Z”,“shell.execute_reply”:“2024-08-23T01:41:39.061035Z”,“shell.execute_reply.started”:“2024-08-23T01:41:39.045813Z”}}’ trusted=‘true’ execution_count=19}
get_trainer functiondef get_trainer(lr, bs=16):
args = TrainingArguments(
'outputs',
learning_rate=lr,
warmup_ratio=0.1,
lr_scheduler_type='cosine',
fp16=True,
eval_strategy="epoch",
logging_strategy="epoch",
per_device_train_batch_size=bs,
per_device_eval_batch_size=bs*2,
num_train_epochs=3,
weight_decay=0.01,
report_to='none')
model = AutoModelForSequenceClassification.from_pretrained(model_nm, num_labels=3) # 3 labels for 3 classes
model.resize_token_embeddings(len(tokz))
model.config.pad_token_id = model.config.eos_token_id
trainer = Trainer(model, args, train_dataset=train_ds, eval_dataset=eval_ds,
tokenizer=tokz, compute_metrics=get_acc, callbacks=[metric_callback])
return trainer, args:::
::: {#cell-27 .cell _kg_hide-input=‘false’ quarto-private-1=‘{“key”:“execution”,“value”:{“iopub.execute_input”:“2024-08-23T01:41:39.063570Z”,“iopub.status.busy”:“2024-08-23T01:41:39.063250Z”,“iopub.status.idle”:“2024-08-23T01:41:39.074965Z”,“shell.execute_reply”:“2024-08-23T01:41:39.074094Z”,“shell.execute_reply.started”:“2024-08-23T01:41:39.063545Z”}}’ trusted=‘true’ execution_count=20}
get_test_df functiondef get_test_df(trainer):
test_df = test_ds.to_pandas()[['input', 'labels']]
preds = trainer.predict(test_ds).predictions.astype(float)
probs = F.softmax(torch.tensor(preds), dim=1)
predicted_classes = torch.argmax(probs, dim=1).numpy()
test_df['predicted'] = predicted_classes
test_df['match'] = test_df['labels'] == test_df['predicted']
acc = test_df['match'].mean()
label_map = {i: label_text for i, label_text in enumerate(test_ds.features["labels"].names)}
test_df['label_text'] = test_df['labels'].apply(lambda x: label_map[x])
test_df['pred_text'] = test_df['predicted'].apply(lambda x: label_map[x])
return test_df, acc:::
While there are other hyperparameters to tune (epochs, warmup_ratio, weight_decay) I’ll focus this notebook on fine-tuning with different learning rates. I’ll start with the same learning rates that I used for the 33M and 8M models:
::: {#cell-30 .cell _kg_hide-input=‘false’ trusted=‘true’}
metrics = []
trainers = []
learning_rates = [1e-6, 1e-5, 3e-5, 5e-5, 8e-5, 1e-4, 3e-4, 5e-4, 8e-4, 1e-3, 1e-2, 1e-1]
for lr in learning_rates:
print(f"Learning Rate: {lr}")
metric_callback = MetricCallback()
trainer, args = get_trainer(lr, bs=64)
trainer.train()
metrics.append({
"learning_rate": lr,
"metrics": metric_callback.metrics
})
trainers.append(trainer)
# clean up
report_gpu()
!rm -r /kaggle/working/outputs:::
::: {#cell-31 .cell _kg_hide-input=‘false’ quarto-private-1=‘{“key”:“execution”,“value”:{“iopub.execute_input”:“2024-08-23T01:45:45.333740Z”,“iopub.status.busy”:“2024-08-23T01:45:45.332543Z”,“iopub.status.idle”:“2024-08-23T01:45:45.364670Z”,“shell.execute_reply”:“2024-08-23T01:45:45.363631Z”,“shell.execute_reply.started”:“2024-08-23T01:45:45.333706Z”}}’ trusted=‘true’ execution_count=22}
metrics_df = results_to_dataframe(metrics, model_name="TinyStories-3M")
metrics_df = metrics_df.query('current_learning_rate.notna()'):::
The highest validation set accuracy (73%) was obtained with a learning rate of 8e-5.
metrics_df.query('eval_accuracy == eval_accuracy.max()')| model_name | initial_learning_rate | current_learning_rate | epoch | learning_rate | loss | grad_norm | eval_loss | eval_accuracy | eval_runtime | eval_samples_per_second | eval_steps_per_second | train_runtime | train_samples_per_second | train_steps_per_second | total_flos | train_loss | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 19 | TinyStories-3M | 0.00008 | 0.0 | 3.0 | 0.0 | 0.5798 | 620476.375 | 0.653758 | 0.732843 | 0.3241 | 1259.023 | 6.172 | 8.6789 | 563.784 | 4.494 | 6.090918e+12 | 0.757333 |
learning_rates[4] == 0.00008TrueThis model achieved a 67% test set accuracy.
test_df, acc = get_test_df(trainers[4])
acc/opt/conda/lib/python3.10/site-packages/torch/nn/parallel/_functions.py:68: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.
warnings.warn('Was asked to gather along dimension 0, but all '0.6666666666666666This 3M parameter finetuned model predicts neutral sentences the best (116/125) followed by positive sentences (25/54) and lastly, negative sentences (22/46). I’ll reiterate that the dataset contains a majority of neutral sentences, followed by positive sentences and the least represented sentiment is negative.
make_cm(test_df)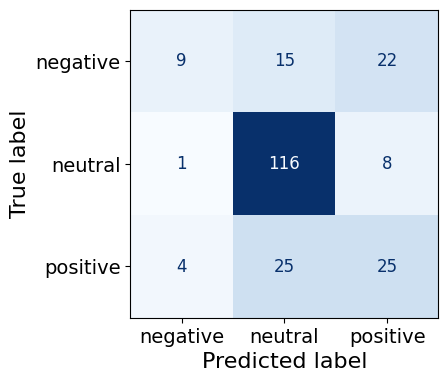
As the learning rate increases (starting at 1e-6) the validation set accuracy increases until it reaches a peak at a learning rate of 8e-5. It reaches a bit of a second peak at 1e-3.
::: {#cell-42 .cell _kg_hide-input=‘false’ quarto-private-1=‘{“key”:“execution”,“value”:{“iopub.execute_input”:“2024-08-23T01:47:31.483177Z”,“iopub.status.busy”:“2024-08-23T01:47:31.482465Z”,“iopub.status.idle”:“2024-08-23T01:47:32.335008Z”,“shell.execute_reply”:“2024-08-23T01:47:32.334026Z”,“shell.execute_reply.started”:“2024-08-23T01:47:31.483144Z”}}’ trusted=‘true’ execution_count=29}
final_epoch_metrics = metrics_df.query("epoch == 3")
plt.scatter(final_epoch_metrics['initial_learning_rate'], final_epoch_metrics['eval_accuracy']);
plt.xscale('log')
plt.xlabel('Learning Rate (log scale)')
plt.ylabel('Validation Set Accuracy')
plt.title('Learning Rate vs. Final Epoch Validation Accuracy');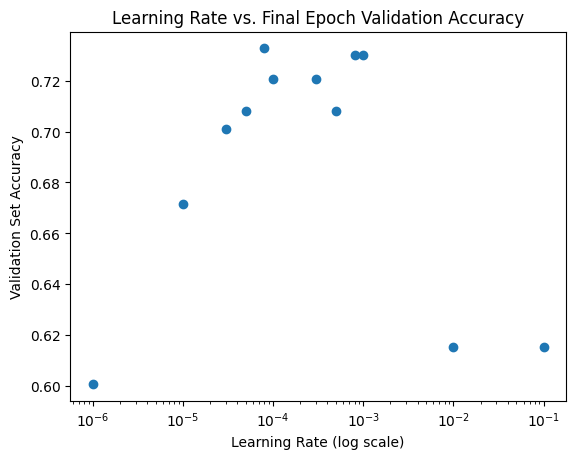
:::
I’ll test the model (run a “sanity check”) on three made-up sentences. I don’t want to weigh these results too much as they are cherry-picked sentences, but this model gets 2/3 right.
text = "The net sales went up from USD $3.4M to USD $5.6M since the same quarter last year"
_ = get_prediction(trainers[4].model, text, tokz)Probability: 0.55
Predicted label: positivetext = "The net sales went down from USD $8.9M to USD $1.2M since the same quarter last year"
_ = get_prediction(trainers[4].model, text, tokz)Probability: 0.53
Predicted label: positivetext = "The net sales stayed the as the same quarter last year"
_ = get_prediction(trainers[4].model, text, tokz)Probability: 0.74
Predicted label: neutraltest_dfs = []
accs = []
for t in trainers:
test_df, acc = get_test_df(t)
test_dfs.append(test_df)
accs.append(acc)8e-5 is also the learning rate with the highest test set accuracy (67%).
accs[0.52,
0.6177777777777778,
0.6355555555555555,
0.6488888888888888,
0.6666666666666666,
0.6266666666666667,
0.6311111111111111,
0.6133333333333333,
0.6133333333333333,
0.6577777777777778,
0.5555555555555556,
0.5555555555555556]I’ll train 10 models for the best-performing learning rate (8e-5) to see if the results are consistent.
learning_rates[4]8e-05To prevent (all but the first) models from getting the same loss and accuracy per epoch, I’ll reset the random seed each iteration.
set_seed functionimport random
def set_seed(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)::: {#cell-57 .cell _kg_hide-input=‘false’ trusted=‘true’}
best_metrics = []
best_trainers = []
lr = learning_rates[4]
for i in range(10):
set_seed(42 + i) # Use a different seed for each run
metric_callback = MetricCallback()
trainer, args = get_trainer(lr=lr, bs=64)
trainer.train()
best_metrics.append({
"learning_rate": lr,
"metrics": metric_callback.metrics
})
best_trainers.append(trainer)
# clean up
report_gpu()
!rm -r /kaggle/working/outputs:::
::: {#cell-58 .cell _kg_hide-input=‘false’ quarto-private-1=‘{“key”:“execution”,“value”:{“iopub.execute_input”:“2024-08-23T02:00:30.938906Z”,“iopub.status.busy”:“2024-08-23T02:00:30.938414Z”,“iopub.status.idle”:“2024-08-23T02:00:30.975415Z”,“shell.execute_reply”:“2024-08-23T02:00:30.974320Z”,“shell.execute_reply.started”:“2024-08-23T02:00:30.938873Z”}}’ trusted=‘true’ execution_count=43}
best_metrics_df = results_to_dataframe(best_metrics, model_name="TinyStories-3M")
best_metrics_df = best_metrics_df.query('current_learning_rate.notna()')
best_metrics_df.head(3)| model_name | initial_learning_rate | current_learning_rate | epoch | learning_rate | loss | grad_norm | eval_loss | eval_accuracy | eval_runtime | eval_samples_per_second | eval_steps_per_second | train_runtime | train_samples_per_second | train_steps_per_second | total_flos | train_loss | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | TinyStories-3M | 0.00008 | 0.000068 | 1.0 | 0.000068 | 0.9378 | 679908.0000 | 0.809436 | 0.656863 | 0.3223 | 1265.836 | 6.205 | NaN | NaN | NaN | NaN | NaN |
| 2 | TinyStories-3M | 0.00008 | 0.000024 | 2.0 | 0.000024 | 0.7057 | 660703.8750 | 0.647278 | 0.715686 | 0.3267 | 1248.882 | 6.122 | NaN | NaN | NaN | NaN | NaN |
| 3 | TinyStories-3M | 0.00008 | 0.000000 | 3.0 | 0.000000 | 0.5673 | 626431.0625 | 0.636278 | 0.713235 | 0.3271 | 1247.404 | 6.115 | 8.6262 | 567.227 | 4.521 | 6.090918e+12 | 0.736961 |
:::
The minimum accuracy achieved by this learning rate was about 71% and the maximum accuracy was 78%, which is a considerably wide range.
final_accs = best_metrics_df.query("epoch == 3")['eval_accuracy']
final_accs.describe()count 10.000000
mean 0.743627
std 0.018421
min 0.713235
25% 0.737132
50% 0.745098
75% 0.747549
max 0.784314
Name: eval_accuracy, dtype: float64final_accs.value_counts()eval_accuracy
0.747549 2
0.745098 2
0.742647 1
0.713235 1
0.725490 1
0.784314 1
0.735294 1
0.750000 1
Name: count, dtype: int64::: {#cell-62 .cell _kg_hide-input=‘false’ trusted=‘true’}
test_dfs = []
accs = []
for t in best_trainers:
test_df, acc = get_test_df(t)
test_dfs.append(test_df)
accs.append(acc):::
The minimum test set accuracy is 64% and the maximum is about 74% for this learning rate (8e-5).
accs = pd.Series(accs)
accs.value_counts()0.684444 2
0.720000 2
0.693333 1
0.640000 1
0.715556 1
0.671111 1
0.737778 1
0.702222 1
Name: count, dtype: int64accs.describe()count 10.000000
mean 0.696889
std 0.028558
min 0.640000
25% 0.684444
50% 0.697778
75% 0.718889
max 0.737778
dtype: float64accs0 0.640000
1 0.693333
2 0.715556
3 0.684444
4 0.671111
5 0.737778
6 0.720000
7 0.720000
8 0.702222
9 0.684444
dtype: float64The model with the best test set accuracy (74%) also gets 2/3 of my sanity check sentiments correct.
text = "The net sales went up from USD $3.4M to USD $5.6M since the same quarter last year"
_ = get_prediction(best_trainers[5].model, text, tokz)Probability: 0.74
Predicted label: positivetext = "The net sales went down from USD $8.9M to USD $1.2M since the same quarter last year"
_ = get_prediction(best_trainers[5].model, text, tokz)Probability: 0.73
Predicted label: positivetext = "The net sales stayed the as the same quarter last year"
_ = get_prediction(best_trainers[5].model, text, tokz)Probability: 0.47
Predicted label: neutralI’ll summarize my results so far for the 33M, 8M and now 3M TinyStories fine-tuned models:
| Arch | Fine-tuning Learning Rate | Best Val Acc | Best Test Acc |
|---|---|---|---|
| TinyStories-33M | 5e-04 | 86% | 79% |
| TinyStories-8M | 8e-05 | 85% | 86% |
| TinyStories-8M | 5e-04 | 79% | 86% |
| TinyStories-3M | 8e-05 | 78% | 74% |
I’ll do the final TinyStories architecture, 1M parameters, in the next notebook in this series.
I hope you enjoyed this blog post! Follow me on Twitter @vishal_learner.