Conducting a Question-by-Question Error Analysis on Full Text Search Results
python
RAG
information retrieval
fastbookRAG
In this blog post, I conduct a detailed error analysis of 39 questions from a set of 202, where none of the 6 full text search methods retrieved sufficient context to answer them. I examine each question, categorize the errors, and discuss potential improvements and implications for future work.
Author
Vishal Bakshi
Published
September 5, 2024
Background
In this notebook I’ll do a deep dive error analysis of my full text search results, where I implemented 6 different keyword-based full text searches to retrieve context sufficient to answer questions from the end-of-chapter Questionnaires in fastbook. Here is the summary of results from those experiments:
As a reminder, the two metrics I use for evaluation are Score and Answer Rate
The evaluation metric for each question, that I’m simply calling score, is binary: can the retrieved context answer the question (1) or not (0)? The evaluation metric across a set of questions, which I’m calling the Answer Rate, is the mean score for those questions.
While this is a straightforward pair of metrics, they do involve some judgment. After reading the retrieved context, I decide if it’s enough to answer the question.
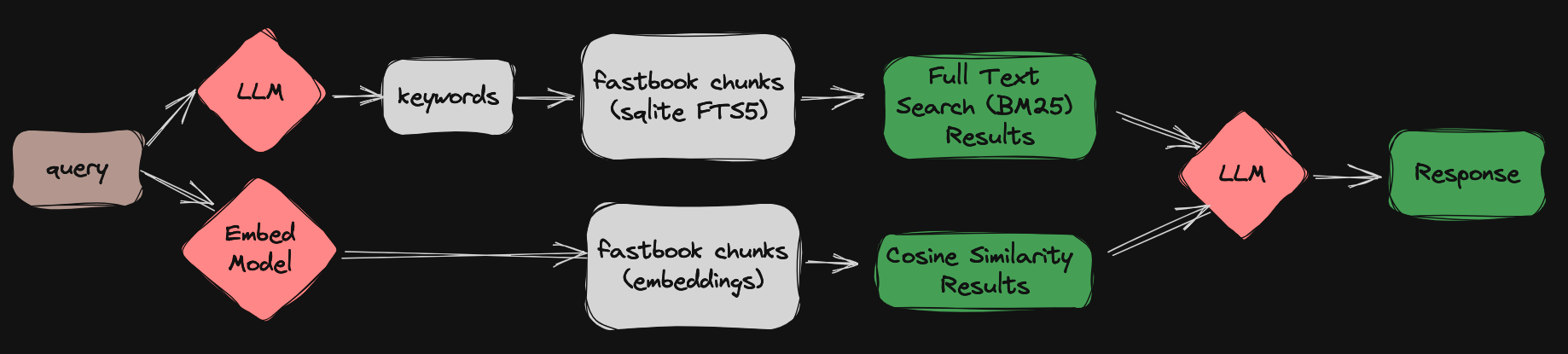
This notebook is a part of series of blog posts for a project I’m calling fastbookRAG where I’m trying to answer questions from the fastbook end-of-chapter Questionnaires using the following pipeline:
fastbookRAG diagram
Here are the number of unanswered questions per chapter:
Chapter
# of Questions
1
2
2
4
4
7
8
10
9
5
10
5
13
6
Total
39
Error Analysis
For 39 questions, none of the 6 full-text search methods retrieved enough context to provide an answer. I’ll be looking at each of those 39 questions, their “gold standard” answer (obtained from the fastai Forums Questionnaire wikis), and the relevant context from the fastbook chapter.
I have three objectives for this error analysis:
Understand what kinds of questions are difficult to answer using full text search.
Identify ambigious questions that need to be removed from the evaluation set (e.g. “How does it solve it?”).
Identify unanswerable questions (i.e. “to be done by the reader” type questions) that need to be removed.
The underlying goal of this analysis: look at your data!
For each of the 39 questions, I will write four sections:
Relevant Context: the paragraph(s) from the fastbook text that are sufficient to answer the question.
Analysis: my interpretation/explanation for why a keyword-based search did not retrieve the context.
Conclusion: what I think is needed to retrieve the sufficient context (and if I think this question should be removed)
Tags: keywords (no pun intented) that describe the type of error.
Chapter, Question Number: 1 5
Question Text: ""What were the two theoretical misunderstandings that held back the field of neural networks?""
Answer: ""In 1969, Marvin Minsky and Seymour Papert demonstrated in their book, "Perceptrons", that a single layer of artificial neurons cannot learn simple, critical mathematical functions like XOR logic gate. While they subsequently demonstrated in the same book that additional layers can solve this problem, only the first insight was recognized, leading to the start of the first AI winter.
In the 1980's, models with two layers were being explored. Theoretically, it is possible to approximate any mathematical function using two layers of artificial neurons. However, in practices, these networks were too big and too slow. While it was demonstrated that adding additional layers improved performance, this insight was not acknowledged, and the second AI winter began. In this past decade, with increased data availability, and improvements in computer hardware (both in CPU performance but more importantly in GPU performance), neural networks are finally living up to its potential.""
Keywords: "neural, networks, theoretical, misunderstandings, field"
Relevant Context:
An MIT professor named Marvin Minsky (who was a grade behind Rosenblatt at the same high school!), along with Seymour Papert, wrote a book called Perceptrons (MIT Press), about Rosenblatt’s invention. They showed that a single layer of these devices was unable to learn some simple but critical mathematical functions (such as XOR). In the same book, they also showed that using multiple layers of the devices would allow these limitations to be addressed. Unfortunately, only the first of these insights was widely recognized. As a result, the global academic community nearly entirely gave up on neural networks for the next two decades.
In the 1980’s most models were built with a second layer of neurons, thus avoiding the problem that had been identified by Minsky and Papert (this was their “pattern of connectivity among units,” to use the framework above). And indeed, neural networks were widely used during the ’80s and ’90s for real, practical projects. However, again a misunderstanding of the theoretical issues held back the field. In theory, adding just one extra layer of neurons was enough to allow any mathematical function to be approximated with these neural networks, but in practice such networks were often too big and too slow to be useful.
Analysis:
I think the reason none of the methods retrieved both contexts (they generally only retrieved the second paragraph) is due to the choice of keywords. The second paragraph contains four of the five keywords (neural, networks, theoretical, field). The first paragraph does not contain any of the keywords.
Conclusion: Keep the question in the evaluation set. I expect semantic search to retrieve both paragraphs.
Tags: insufficient keywords, semantic search
Question 16
print_data(1)
Chapter, Question Number: 1 16
Question Text: ""What do you need in order to train a model?""
Answer: ""You will need an architecture for the given problem. You will need data to input to your model. For most use-cases of deep learning, you will need labels for your data to compare your model predictions to. You will need a loss function that will quantitatively measure the performance of your model. And you need a way to update the parameters of the model in order to improve its performance (this is known as an optimizer).""
Keywords: "train, model, training, models, dataset, data"
Relevant Context:
From this picture we can now see some fundamental things about training a deep learning model:
A model cannot be created without data.
A model can only learn to operate on the patterns seen in the input data used to train it.
This learning approach only creates predictions, not recommended actions.
It’s not enough to just have examples of input data; we need labels for that data too (e.g., pictures of dogs and cats aren’t enough to train a model; we need a label for each one, saying which ones are dogs, and which are cats).
Machine learning is a discipline where we define a program not by writing it entirely ourselves, but by learning from data. Deep learning is a specialty within machine learning that uses neural networks with multiple layers. Image classification is a representative example (also known as image recognition). We start with labeled data; that is, a set of images where we have assigned a label to each image indicating what it represents. Our goal is to produce a program, called a model, which, given a new image, will make an accurate prediction regarding what that new image represents.
Every model starts with a choice of architecture, a general template for how that kind of model works internally. The process of training (or fitting) the model is the process of finding a set of parameter values (or weights) that specialize that general architecture into a model that works well for our particular kind of data. In order to define how well a model does on a single prediction, we need to define a loss function, which determines how we score a prediction as good or bad.
Analysis:
The keywords for this question are not sufficient (they are too general) to find the 3 relevant paragraphs. You can imagine that the words “train”, “model”, “training”, “models”, “dataset”, and “data” are plentiful in an introductory chapter about machine and deep learning.
Conclusion: Keep the question in the evaluation set. This is another question for which the sufficient context that needs to be retrieved is better suited for semantic search.
Chapter, Question Number: 2 1
Question Text: ""Provide an example of where the bear classification model might work poorly in production, due to structural or style differences in the training data.""
Answer: ""Working with video data instead of images
Handling nighttime images, which may not appear in this dataset
Dealing with low-resolution camera images
Ensuring results are returned fast enough to be useful in practice
Recognizing bears in positions that are rarely seen in photos that people post online (for example from behind, partially covered by bushes, or when a long way away from the camera)""
Keywords: "bear, classification, model, production, training, data, structural, style, differences"
Relevant Context:
This can result in disaster! For instance, let’s say we really were rolling out a bear detection system that will be attached to video cameras around campsites in national parks, and will warn campers of incoming bears. If we used a model trained with the dataset we downloaded there would be all kinds of problems in practice, such as:
Working with video data instead of images
Handling nighttime images, which may not appear in this dataset
Dealing with low-resolution camera images
Ensuring results are returned fast enough to be useful in practice
Recognizing bears in positions that are rarely seen in photos that people post online (for example from behind, partially covered by bushes, or when a long way away from the camera)
Analysis:
Only two of the keywords are in the relevant context (“model” and “data”).
Conclusion: Keep the question in the evaluation set. This is another question that might perform better using semantic search.
Chapter, Question Number: 2 12
Question Text: ""What does the `splitter` parameter to `DataBlock` do?""
Answer: ""In fastai DataBlock, you provide the splitter argument a way for fastai to split up the dataset into subsets (usually train and validation set). For example, to randomly split the data, you can use fastai's predefined RandomSplitter class, providing it with the proportion of the data used for validation.""
Keywords: "splitter, DataBlock, parameter, function, data"
Relevant Context:
Often, datasets that you download will already have a validation set defined. Sometimes this is done by placing the images for the training and validation sets into different folders. Sometimes it is done by providing a CSV file in which each filename is listed along with which dataset it should be in. There are many ways that this can be done, and fastai provides a very general approach that allows you to use one of its predefined classes for this, or to write your own. In this case, however, we simply want to split our training and validation sets randomly. However, we would like to have the same training/validation split each time we run this notebook, so we fix the random seed (computers don’t really know how to create random numbers at all, but simply create lists of numbers that look random; if you provide the same starting point for that list each time—called the seed—then you will get the exact same list each time):
splitter=RandomSplitter(valid_pct=0.2, seed=42)
Analysis:
There are 4 occurences of the word “splitter” in Chapter 2 of the fastbook. Two of them, splitter and Splitter, occur in the relevant paragraph. I think what misled the full text search were the other keywords (DataBlock, parameter, function, data). I’m not sure if semantic search will perform better, since the explanatory text doesn’t explicitly say something like “the splitter parameter’s purpose is…” as it focuses more on the randomness of the split (which is more related to RandomSplitter than the splitter parameter itself).
Conclusion:
This may just be a question that is unanswerable. I’ll keep it in the evaluation set for now, but might remove it if the semantic search baselines aren’t able to retrieve the relevant context.
Tags: difficult question
Question 24
print_data(4)
Chapter, Question Number: 2 24
Question Text: ""What are three examples of problems that could occur when rolling out a bear warning system in practice?""
Answer: ""The model we trained will likely perform poorly when:
Handling night-time images
Dealing with low-resolution images (ex: some smartphone images)
The model returns prediction too slowly to be useful""
Keywords: "bear, warning, system, problems, rollout, examples"
Relevant Context:
This can result in disaster! For instance, let’s say we really were rolling out a bear detection system that will be attached to video cameras around campsites in national parks, and will warn campers of incoming bears. If we used a model trained with the dataset we downloaded there would be all kinds of problems in practice, such as:
Working with video data instead of images
Handling nighttime images, which may not appear in this dataset
Dealing with low-resolution camera images
Ensuring results are returned fast enough to be useful in practice
Recognizing bears in positions that are rarely seen in photos that people post online (for example from behind, partially covered by bushes, or when a long way away from the camera)
Analysis: This question has the same relevant context as Chapter 2, Question 1. Only 1 of the keywords is in the context (“problems”) and that keyword appears 10 times in the chapter text.
Conclusion: Keep the question in the evaluation set. I would expect semantic search to perform better for this question.
Chapter, Question Number: 2 27
Question Text: ""What are the three steps in the deployment process?""
Answer: ""Manual process - the model is run in parallel and not directly driving any actions, with humans still checking the model outputs.
Limited scope deployment - The model's scope is limited and carefully supervised. For example, doing a geographically and time-constrained trial of model deployment, that is carefully supervised.
Gradual expansion - The model scope is gradually increased, while good reporting systems are implemented in order to check for any significant changes to the actions taken compared to the manual process (i.e. the models should perform similarly to the humans, unless it is already anticipated to be better).""
Keywords: "deployment, process, steps"
Relevant Context:
Where possible, the first step is to use an entirely manual process, with your deep learning model approach running in parallel but not being used directly to drive any actions. The humans involved in the manual process should look at the deep learning outputs and check whether they make sense. For instance, with our bear classifier a park ranger could have a screen displaying video feeds from all the cameras, with any possible bear sightings simply highlighted in red. The park ranger would still be expected to be just as alert as before the model was deployed; the model is simply helping to check for problems at this point.
The second step is to try to limit the scope of the model, and have it carefully supervised by people. For instance, do a small geographically and time-constrained trial of the model-driven approach. Rather than rolling our bear classifier out in every national park throughout the country, we could pick a single observation post, for a one-week period, and have a park ranger check each alert before it goes out.
Then, gradually increase the scope of your rollout. As you do so, ensure that you have really good reporting systems in place, to make sure that you are aware of any significant changes to the actions being taken compared to your manual process. For instance, if the number of bear alerts doubles or halves after rollout of the new system in some location, we should be very concerned. Try to think about all the ways in which your system could go wrong, and then think about what measure or report or picture could reflect that problem, and ensure that your regular reporting includes that information.
Analysis: Only one of the keywords, “process”, appears in the relevant context for this question, a word that appears 25 times in Chapter 2.
Conclusion: Keep the question in the evaluation set. Not enough of the keywords in the relevant context are in the keywords used for full text search.
Tags: insufficient keywords, distracting keywords
Chapter 4 (7 questions)
Question 1
print_data(6)
Chapter, Question Number: 4 1
Question Text: ""How is a grayscale image represented on a computer? How about a color image?""
Answer: ""Images are represented by arrays with pixel values representing the content of the image. For grayscale images, a 2-dimensional array is used with the pixels representing the grayscale values, with a range of 256 integers. A value of 0 represents black, and a value of 255 represents white, with different shades of gray in between. For color images, three color channels (red, green, blue) are typically used, with a separate 256-range 2D array used for each channel. A pixel value of 0 represents black, with 255 representing solid red, green, or blue. The three 2D arrays form a final 3D array (rank 3 tensor) representing the color image.""
Keywords: "grayscale, image, images, color, computer, representation"
Relevant Context:
You can see that the background white pixels are stored as the number 0, black is the number 255, and shades of gray are between the two. The entire image contains 28 pixels across and 28 pixels down, for a total of 784 pixels. (This is much smaller than an image that you would get from a phone camera, which has millions of pixels, but is a convenient size for our initial learning and experiments. We will build up to bigger, full-color images soon.)
Analysis: I scanned the Chapter 2 notebook and did not find an explanation about how color images are represented on a computer. Some of the methods did retrieve the relevant context shown above.
Conclusion: Remove this question from the evaluation set as the chapter doesn’t include context to answer it.
Tags: unanswerable
Question 12
print_data(7)
Chapter, Question Number: 4 12
Question Text: ""What is SGD?""
Answer: ""SGD, or stochastic gradient descent, is an optimization algorithm. Specifically, SGD is an algorithm that will update the parameters of a model in order to minimize a given loss function that was evaluated on the predictions and target. The key idea behind SGD (and many optimization algorithms, for that matter) is that the gradient of the loss function provides an indication of how that loss function changes in the parameter space, which we can use to determine how best to update the parameters in order to minimize the loss function. This is what SGD does.""
Keywords: "SGD, stochastic, gradient, descent, optimization, algorithm"
Relevant Context:
To be exact, we’ll discuss the roles of arrays and tensors and of broadcasting, a powerful technique for using them expressively. We’ll explain stochastic gradient descent (SGD), the mechanism for learning by updating weights automatically. We’ll discuss the choice of a loss function for our basic classification task, and the role of mini-batches. We’ll also describe the math that a basic neural network is actually doing. Finally, we’ll put all these pieces together.
To be more specific, here are the steps that we are going to require, to turn this function into a machine learning classifier:
Initialize the weights.
For each image, use these weights to predict whether it appears to be a 3 or a 7.
Based on these predictions, calculate how good the model is (its loss).
Calculate the gradient, which measures for each weight, how changing that weight would change the loss
Step (that is, change) all the weights based on that calculation.
Go back to the step 2, and repeat the process.
Iterate until you decide to stop the training process (for instance, because the model is good enough or you don’t want to wait any longer).
Analysis: The paragraphs that answer this question are relatively far apart in the document so even a 3-paragraph chunk would not capture both. Furthermore, the paragraph that lists the seven steps of SGD only contains one of the keywords, “gradient.”
Conclusion: Keep the question in the evaluation set. I’m not so sure this question will be answerable by semantic search but I don’t see any reason to remove it (other than it’s hard to answer).
Tags: insufficient keywords
Question 13
print_data(8)
Chapter, Question Number: 4 13
Question Text: ""Why does SGD use mini-batches?""
Answer: ""We need to calculate our loss function (and our gradient) on one or more data points. We cannot calculate on the whole datasets due to compute limitations and time constraints. If we iterated through each data point, however, the gradient will be unstable and imprecise, and is not suitable for training. As a compromise, we calculate the average loss for a small subset of the dataset at a time. This subset is called a mini-batch. Using mini-batches are also more computationally efficient than single items on a GPU.""
Keywords: "SGD, mini-batches, minibatches, stochastic, gradient, descent"
Relevant Context:
In order to take an optimization step we need to calculate the loss over one or more data items. How many should we use? We could calculate it for the whole dataset, and take the average, or we could calculate it for a single data item. But neither of these is ideal. Calculating it for the whole dataset would take a very long time. Calculating it for a single item would not use much information, so it would result in a very imprecise and unstable gradient. That is, you’d be going to the trouble of updating the weights, but taking into account only how that would improve the model’s performance on that single item.
So instead we take a compromise between the two: we calculate the average loss for a few data items at a time. This is called a mini-batch. The number of data items in the mini-batch is called the batch size. A larger batch size means that you will get a more accurate and stable estimate of your dataset’s gradients from the loss function, but it will take longer, and you will process fewer mini-batches per epoch. Choosing a good batch size is one of the decisions you need to make as a deep learning practitioner to train your model quickly and accurately. We will talk about how to make this choice throughout this book.
Another good reason for using mini-batches rather than calculating the gradient on individual data items is that, in practice, we nearly always do our training on an accelerator such as a GPU. These accelerators only perform well if they have lots of work to do at a time, so it’s helpful if we can give them lots of data items to work on. Using mini-batches is one of the best ways to do this. However, if you give them too much data to work on at once, they run out of memory—making GPUs happy is also tricky!
Analysis: I’m surprised that none of the methods retrieved this context. The term “mini-batch” appears 14 times in the Chapter 4 text and 5 times in the three paragraphs of the relevant context.
Conclusion: Keep the question in the evaluation set. My guess is that the other keywords (“SGD”, “stochastic”, “gradient”, “descent”) distract the full text search. I would expect semantic search to succeed for this question.
Tags: insufficient keywords, semantic search
Question 14
print_data(9)
Chapter, Question Number: 4 14
Question Text: ""What are the seven steps in SGD for machine learning?""
Answer: ""Initialize the parameters - Random values often work best.
Calculate the predictions - This is done on the training set, one mini-batch at a time.
Calculate the loss - The average loss over the minibatch is calculated
Calculate the gradients - this is an approximation of how the parameters need to change in order to minimize the loss function
Step the weights - update the parameters based on the calculated weights
Repeat the process
Stop - In practice, this is either based on time constraints or usually based on when the training/validation losses and metrics stop improving.""
Keywords: "SGD, steps, machine, learning, gradient, descent"
Relevant Context:
To be more specific, here are the steps that we are going to require, to turn this function into a machine learning classifier:
Initialize the weights.
For each image, use these weights to predict whether it appears to be a 3 or a 7.
Based on these predictions, calculate how good the model is (its loss).
Calculate the gradient, which measures for each weight, how changing that weight would change the loss
Step (that is, change) all the weights based on that calculation.
Go back to the step 2, and repeat the process.
Iterate until you decide to stop the training process (for instance, because the model is good enough or you don’t want to wait any longer).
Analysis: Similar to Chapter 4, Question 12, only two of the keywords, “machine” and “learning”, are found in the relevant context. Not only that, but those two keywords are rather distracting as there are 8 occurences of “machine” and 53 occurences of “learning” in the chapter text, distracting the full text search from finding the relevant context.
Conclusion: Keep the question in the evaluation set. I think this a tough question to answer for full text search, but semantic search might perform better.
Chapter, Question Number: 4 23
Question Text: ""What is the function to calculate new weights using a learning rate?""
Answer: ""The optimizer step function""
Keywords: "function, calculate, weight, weights, learning, rate"
Relevant Context:
Deciding how to change our parameters based on the values of the gradients is an important part of the deep learning process. Nearly all approaches start with the basic idea of multiplying the gradient by some small number, called the learning rate (LR). The learning rate is often a number between 0.001 and 0.1, although it could be anything. Often, people select a learning rate just by trying a few, and finding which results in the best model after training (we’ll show you a better approach later in this book, called the learning rate finder). Once you’ve picked a learning rate, you can adjust your parameters using this simple function:
w -= gradient(w) * lr
This is known as stepping your parameters, using an optimizer step. Notice how we subtract the gradient * lr from the parameter to update it. This allows us to adjust the parameter in the direction of the slope by increasing the parameter when the slope is negative and decreasing the parameter when the slope is positive. We want to adjust our parameters in the direction of the slope because our goal in deep learning is to minimize the loss.
Analysis: Some of the methods (like BM25_C) did retrieve the first paragraph (“Deciding how to change…”) but did not capture the third paragraph that has the answer (“This is known…optimizer step”). The keywords are also distracting, here are the occurences of each keyword in the chapter text:
keyword
Occurences
function
157
calculate
69
weight
67
learning
53
weights
43
rate
33
That being said, “learning rate” does appear five times in the first paragraph. The problem is that none of the keywords appear in the second paragraph, which has the answer.
Conclusion: Keep the question in the evaluation set. This is an example of where chunking strategy would make a difference. I’m not so sure semantic search will be successful unless the three paragraphs in the relevant context are in one chunk.
Tags: insufficient keywords, chunking strategy
Question 28
print_data(11)
Chapter, Question Number: 4 28
Question Text: ""What are the ""bias"" parameters in a neural network? Why do we need them?""
Answer: ""Without the bias parameters, if the input is zero, the output will always be zero. Therefore, using bias parameters adds additional flexibility to the model.""
Keywords: "bias, biases, neural, network, networks, parameters"
Relevant Context:
The function weights*pixels won’t be flexible enough—it is always equal to 0 when the pixels are equal to 0 (i.e., its intercept is 0). You might remember from high school math that the formula for a line is y=w*x+b; we still need the b. We’ll initialize it to a random number too:
bias = init_params(1)
In neural networks, the w in the equation y=w*x+b is called the weights, and the b is called the bias. Together, the weights and bias make up the parameters.
Analysis: This is another example of how chunking strategy effects the retrieval performance. Multiple approaches retrieved the third paragraph (“In neural networks…”) as it contains 4 of the 6 keywords (“bias”, “neural”, “networks”, and “parameters”). However, if the chunking strategy (1- or 3-paragraph) didn’t capture the two paragraphs before it, the answer was not retrieved (“…it is always equal to 0…”).
Conclusion: This question is answerable, but is sensitive to chunking strategy for full text search. Perhaps semantic search will perform better.
Tags: chunking strategy, semantic search
Question 31
print_data(12)
Chapter, Question Number: 4 31
Question Text: ""Why do we have to zero the gradients?""
Answer: ""PyTorch will add the gradients of a variable to any previously stored gradients. If the training loop function is called multiple times, without zeroing the gradients, the gradient of current loss would be added to the previously stored gradient value.""
Keywords: "zero, zeroing, gradient, gradients, optimization"
Relevant Context:
The gradients have changed! The reason for this is that loss.backward actually adds the gradients of loss to any gradients that are currently stored. So, we have to set the current gradients to 0 first:
weights.grad.zero_()
bias.grad.zero_();
Analysis: The methods did not retrieve any of the relevant context. My guess is that the key keyword is 0 but the Claude-generated keywords don’t include that number (they only have “zero” and “zeroing”).
Conclusion: Keep the question in the evaluation set. I would imagine semantic search performing better for this question.
Tags insufficient keywords, semantic search
Chapter 8 (10 questions)
Question 2
print_data(13)
Chapter, Question Number: 8 2
Question Text: ""How does it solve it?""
Answer: ""The key idea of collaborative filtering is latent factors. The idea is that the model can tell what kind of items you may like (ex: you like sci-fi movies/books) and these kinds of factors are learned (via basic gradient descent) based on what items other users like.""
Keywords: "solve, solves, solution, solutions, how"
Relevant Context:
The key foundational idea is that of latent factors. In the Netflix example, we started with the assumption that you like old, action-packed sci-fi movies. But you never actually told Netflix that you like these kinds of movies. And Netflix never actually needed to add columns to its movies table saying which movies are of these types. Still, there must be some underlying concept of sci-fi, action, and movie age, and these concepts must be relevant for at least some people’s movie watching decisions.
Since we don’t know what the latent factors actually are, and we don’t know how to score them for each user and movie, we should learn them.
Analysis: This is an amiguous question as it doesn’t provide any context for Claude to generate relevant keywords. Both paragraphs of the relevant context are needed to fully answer this question and they are far apart in the document, so having the right keywords is critical.
Conclusion: Remove this question from the evaluation set because it is too ambiguous for keyword-based or semantic search.
Tags: unanswerable
Question 3
print_data(14)
Chapter, Question Number: 8 3
Question Text: ""Why might a collaborative filtering predictive model fail to be a very useful recommendation system?""
Answer: ""If there are not many recommendations to learn from, or enough data about the user to provide useful recommendations, then such collaborative filtering systems may not be useful.""
Keywords: "collaborative, filtering, predictive, model, recommendation, system, fail"
Relevant Context:
The biggest challenge with using collaborative filtering models in practice is the bootstrapping problem. The most extreme version of this problem is when you have no users, and therefore no history to learn from. What products do you recommend to your very first user?
Analysis: The keywords are distracting the full text search. “collaborative” (12 times), “filtering” (12), and “model” (63) appear many other times in the chapter text. A better keyword would have been “problem” which appears twice in the relevant context.
Conclusion: Keep the question in the evaluation set. I think this question will perform better with semantic search.
Tags: insufficient keywords, semantic search
Question 4
print_data(15)
Chapter, Question Number: 8 4
Question Text: ""What does a crosstab representation of collaborative filtering data look like?""
Answer: ""In the crosstab representation, the users and items are the rows and columns (or vice versa) of a large matrix with the values filled out based on the user's rating of the item.""
Keywords: "crosstab, collaborative, filtering, data, representation"
Relevant Context:
We have selected just a few of the most popular movies, and users who watch the most movies, for this crosstab example. The empty cells in this table are the things that we would like our model to learn to fill in. Those are the places where a user has not reviewed the movie yet, presumably because they have not watched it. For each user, we would like to figure out which of those movies they might be most likely to enjoy.
Because each user will have a set of these factors and each movie will have a set of these factors, we can show these randomly initialized values right next to the users and movies in our crosstab, and we can then fill in the dot products for each of these combinations in the middle.
Analysis: The two main pieces of context that answer this question are images which I have not shown above. The text that I have shown doesn’t fully explain the answer to this question.
Conclusion: I will remove this question from the evaluation set because it requires images to answer this question and currently I am not storing images in the database.
Tags: unanswerable, requires image
Question 6
print_data(16)
Chapter, Question Number: 8 6
Question Text: ""What is a latent factor? Why is it ""latent""?""
Answer: ""As described above, a latent factor are factors that are important for the prediction of the recommendations, but are not explicitly given to the model and instead learned (hence "latent").""
Keywords: "latent, factor, factors, hidden, unobservable, underlying"
Relevant Context:
The key foundational idea is that of latent factors. In the Netflix example, we started with the assumption that you like old, action-packed sci-fi movies. But you never actually told Netflix that you like these kinds of movies. And Netflix never actually needed to add columns to its movies table saying which movies are of these types. Still, there must be some underlying concept of sci-fi, action, and movie age, and these concepts must be relevant for at least some people’s movie watching decisions.
Since we don’t know what the latent factors actually are, and we don’t know how to score them for each user and movie, we should learn them.
Analysis: This is similar to Question #2 in this chapter. The word “latent” shows up 17 times in the chapter, and “factors” 61 times.
Conclusion: Keep the question in the evaluation set. It’s likely that full text search, even with better keywords, just might not be able to retrieve this context. I would think semantic search would.
Tags: insufficient keywords, semantic search
Question 8
print_data(17)
Chapter, Question Number: 8 8
Question Text: ""What does pandas.DataFrame.merge do?""
Answer: ""It allows you to merge DataFrames into one DataFrame.""
Keywords: "pandas, dataframe, merge, join, combine"
Relevant Context:
We can merge this with our ratings table to get the user ratings by title:
ratings = ratings.merge(movies)
ratings.head()
Analysis: Only those three lines are relevant for this question and they don’t explicitly answer the question (i.e. there isn’t an explicit definition of .merge).
Conclusion: Remove this question from the evaluation set.
Tags: unanswerable
Question 12
print_data(18)
Chapter, Question Number: 8 12
Question Text: ""What does an embedding contain before we start training (assuming we're not using a pretained model)?""
Answer: ""The embedding is randomly initialized.""
Keywords: "embedding, embeddings, training, pretrained, model, models"
Relevant Context:
This is what embeddings are. We will attribute to each of our users and each of our movies a random vector of a certain length (here, n_factors=5), and we will make those learnable parameters. That means that at each step, when we compute the loss by comparing our predictions to our targets, we will compute the gradients of the loss with respect to those embedding vectors and update them with the rules of SGD (or another optimizer).
So far, we’ve used Embedding without thinking about how it really works. Let’s re-create DotProductBias without using this class. We’ll need a randomly initialized weight matrix for each of the embeddings. We have to be careful, however. Recall from <> that optimizers require that they can get all the parameters of a module from the module’s parameters method. However, this does not happen fully automatically. If we just add a tensor as an attribute to a Module, it will not be included in parameters:
Analysis: There are over 50 occurences of the words “embedding” and “embeddings”. Perhaps if “initialize” was a keyword the full text search would have retrieved the relevant context.
Conclusion: Keep the question in the evaluation set. Chalk this one up to a lack of appropriate keywords. Perhaps semantic search would do better in this situation.
Tags: insufficient keywords, semantic search
Question 17
print_data(19)
Chapter, Question Number: 8 17
Question Text: ""What would happen if we used cross-entropy loss with MovieLens? How would we need to change the model?""
Answer: ""We would need to ensure the model outputs 5 predictions. For example, with a neural network model, we need to change the last linear layer to output 5, not 1, predictions. Then this is passed into the Cross Entropy loss.""
Keywords: "cross-entropy, loss, MovieLens, model, change"
Analysis: There is no relevant context from the chapter text that answers this question.
Conclusion: Remove this question from the evaluation set.
Tags: unanswerable
Question 23
print_data(20)
Chapter, Question Number: 8 23
Question Text: ""What does argsort do in PyTorch?""
Answer: ""This just gets the indices in the order that the original PyTorch Tensor is sorted.""
Keywords: "argsort, pytorch, sorting, indices, tensor, arrays"
Relevant Context:
idxs = movie_bias.argsort()[:5]
idxs = movie_bias.argsort(descending=True)[:5]
idxs = movie_bias.argsort(descending=True)[:5]
Analysis: This is another example of the chapter text not having the answer explicit. A
Conclusion: I’ll remove this question from the evaluation set. Although an LLM would likely know what argsort does, so the code examples might be enough.
Tags: unanswerable
Question 29
print_data(21)
Chapter, Question Number: 8 29
Question Text: ""When using a neural network in collaborative filtering, why can we have different numbers of factors for movies and users?""
Answer: ""In this case, we are not taking the dot product but instead concatenating the embedding matrices, so the number of factors can be different.""
Keywords: "neural, networks, collaborative, filtering, factors, movies, users"
Relevant Context:
Since we’ll be concatenating the embeddings, rather than taking their dot product, the two embedding matrices can have different sizes (i.e., different numbers of latent factors). fastai has a function get_emb_sz that returns recommended sizes for embedding matrices for your data, based on a heuristic that fast.ai has found tends to work well in practice:
Analysis: If “different” was one of the keywords, the relevant context would likely have been retrieved by one of the methods as it appears only twice in the document, both times in this paragraph.
Conclusion: Keep the question in the evaluation set. . I expect semantic search to retrieve this context.
Tags: insufficient keywords, semantic search
Question 30
print_data(22)
Chapter, Question Number: 8 30
Question Text: ""Why is there an nn.Sequential in the CollabNN model?""
Answer: ""This allows us to couple multiple nn.Module layers together to be used. In this case, the two linear layers are coupled together and the embeddings can be directly passed into the linear layers.""
Keywords: "sequential, collabnn, model, neural, networks"
Analysis: The explanatory text does not reference nn.Sequential. It’s likely that an LLM would know what that is and does.
Conclusion: Remove question from evaluation set.
Tags: unanswerable
Chapter 9 (5 questions)
Question 2
print_data(23)
Chapter, Question Number: 9 2
Question Text: ""What is a categorical variable?""
Answer: ""This refers to variables that can take on discrete levels that correspond to different categories.""
Keywords: "categorical, variable, variables, statistics, data"
Relevant Context:
In tabular data some columns may contain numerical data, like “age,” while others contain string values, like “sex.” The numerical data can be directly fed to the model (with some optional preprocessing), but the other columns need to be converted to numbers. Since the values in those correspond to different categories, we often call this type of variables categorical variables. The first type are called continuous variables.
jargon: Continuous and Categorical Variables: Continuous variables are numerical data, such as “age,” that can be directly fed to the model, since you can add and multiply them directly. Categorical variables contain a number of discrete levels, such as “movie ID,” for which addition and multiplication don’t have meaning (even if they’re stored as numbers).
Analysis: There are 50+ occurences of the word “categorical” and 30+ occurences of the word “variable” in this chapter. I think it’s just too common a keyword to give the desired result.
Conclusion: Keep the question in the evaluation set. Semantic search might perform better.
Tags: insufficient keywords, semantic search
Question 13
print_data(24)
Chapter, Question Number: 9 13
Question Text: ""How are mse, samples, and values calculated in the decision tree drawn in this chapter?""
Answer: ""By traversing the tree based on answering questions about the data, we reach the nodes that tell us the average value of the data in that group, the mse, and the number of samples in that group.""
Keywords: "mse, samples, values, decision, tree, calculated, calculation"
Relevant Context:
The top node represents the initial model before any splits have been done, when all the data is in one group. This is the simplest possible model. It is the result of asking zero questions and will always predict the value to be the average value of the whole dataset. In this case, we can see it predicts a value of 10.10 for the logarithm of the sales price. It gives a mean squared error of 0.48. The square root of this is 0.69. (Remember that unless you see m_rmse, or a root mean squared error, then the value you are looking at is before taking the square root, so it is just the average of the square of the differences.) We can also see that there are 404,710 auction records in this group—that is the total size of our training set. The final piece of information shown here is the decision criterion for the best split that was found, which is to split based on the coupler_system column.
Moving down and to the left, this node shows us that there were 360,847 auction records for equipment where coupler_system was less than 0.5. The average value of our dependent variable in this group is 10.21. Moving down and to the right from the initial model takes us to the records where coupler_system was greater than 0.5.
The bottom row contains our leaf nodes: the nodes with no answers coming out of them, because there are no more questions to be answered. At the far right of this row is the node containing records where coupler_system was greater than 0.5. The average value here is 9.21, so we can see the decision tree algorithm did find a single binary decision that separated high-value from low-value auction results. Asking only about coupler_system predicts an average value of 9.21 versus 10.1.
Returning back to the top node after the first decision point, we can see that a second binary decision split has been made, based on asking whether YearMade is less than or equal to 1991.5. For the group where this is true (remember, this is now following two binary decisions, based on coupler_system and YearMade) the average value is 9.97, and there are 155,724 auction records in this group. For the group of auctions where this decision is false, the average value is 10.4, and there are 205,123 records. So again, we can see that the decision tree algorithm has successfully split our more expensive auction records into two more groups which differ in value significantly.
Analysis: This is one of the harder questions to answer with full text search because it’s not explicitly written out in the text. You have to infer the answer from at a minimum the first two paragraphs.
Conclusion: Keep the question in the evaluation set. While it’s a difficult question to answer given the context, there’s no reason to remove it from the evaluation text.
Tags: insufficient keywords, difficult question
Question 14
print_data(25)
Chapter, Question Number: 9 14
Question Text: ""How do we deal with outliers, before building a decision tree?""
Answer: ""Finding out of domain data (Outliers)
Sometimes it is hard to even know whether your test set is distributed in the same way as your training data or, if it is different, then what columns reflect that difference. There's actually a nice easy way to figure this out, which is to use a random forest!
But in this case we don't use a random forest to predict our actual dependent variable. Instead we try to predict whether a row is in the validation set, or the training set.""
Keywords: "outliers, outlier, decision, tree, trees"
Relevant Context:
Sometimes it is hard to know whether your test set is distributed in the same way as your training data, or, if it is different, what columns reflect that difference. There’s actually an easy way to figure this out, which is to use a random forest!
But in this case we don’t use the random forest to predict our actual dependent variable. Instead, we try to predict whether a row is in the validation set or the training set. To see this in action, let’s combine our training and validation sets together, create a dependent variable that represents which dataset each row comes from, build a random forest using that data, and get its feature importance:
Analysis: This is a tough one for full text search because the keyword in the question text, “outlier”, is not used in the relevant context.
Conclusion: Keep the question in the evaluation set. I would expect semantic search to retrieve the relevant context.
Tags: insufficient keywords, semantic search
Question 22
print_data(26)
Chapter, Question Number: 9 22
Question Text: ""Explain why random forests are well suited to answering each of the following question:
How confident are we in our predictions using a particular row of data?
For predicting with a particular row of data, what were the most important factors, and how did they influence that prediction?
Which columns are the strongest predictors?
How do predictions vary as we vary these columns?""
Answer: ""Look at standard deviation between the estimators
Using the treeinterpreter package to check how the prediction changes as it goes through the tree, adding up the contributions from each split/feature. Use waterfall plot to visualize.
Look at feature importance
Look at partial dependence plots""
Keywords: "random forests, predictions, confidence, factors, influence, columns, predictors, variation"
Analysis: The five questions asked are answered across 10+ paragraphs so I have not listed them here. I’m not sure if I should remove this question because it’s five questions in one, or break them apart into five questions. I’m leaning toward removing it since I don’t want to alter the question text.
Conclusion: Remove the question from the evaluation set.
Tags: unanswerable
Question 29
print_data(27)
Chapter, Question Number: 9 29
Question Text: ""How could we use embeddings with a random forest? Would we expect this to help?""
Answer: ""Entity embeddings contains richer representations of the categorical features and definitely can improve the performance of other models like random forests. Instead of passing in the raw categorical columns, the entity embeddings can be passed into the random forest model.""
Keywords: "embeddings, random forest, forests, machine learning, algorithms"
Relevant Context:
The abstract of the entity embedding paper we mentioned at the start of this chapter states: “the embeddings obtained from the trained neural network boost the performance of all tested machine learning methods considerably when used as the input features instead”. It includes the very interesting table in <>.
This is showing the mean average percent error (MAPE) compared among four different modeling techniques, three of which we have already seen, along with k-nearest neighbors (KNN), which is a very simple baseline method. The first numeric column contains the results of using the methods on the data provided in the competition; the second column shows what happens if you first train a neural network with categorical embeddings, and then use those categorical embeddings instead of the raw categorical columns in the model. As you see, in every case, the models are dramatically improved by using the embeddings instead of the raw categories.
This is a really important result, because it shows that you can get much of the performance improvement of a neural network without actually having to use a neural network at inference time. You could just use an embedding, which is literally just an array lookup, along with a small decision tree ensemble.
Analysis: Perhaps the full text search methods would have retrieved the relevant context (or at least parts of it) if the context said “random forest” instead of “decision tree ensemble”.
Conclusion: Keep the question in the evaluation set. I expect semantic search to retrieve the relevant context.
Tags: insufficient keywords, semantic search
Chapter 10 (5 questions)
Question 8
print_data(28)
Chapter, Question Number: 10 8
Question Text: ""What are the three steps to prepare your data for a language model?""
Answer: ""Tokenization
Numericalization
Language model DataLoader""
Keywords: "steps, prepare, data, language, model, models"
Relevant Context:
Each of the steps necessary to create a language model has jargon associated with it from the world of natural language processing, and fastai and PyTorch classes available to help. The steps are:
Tokenization:: Convert the text into a list of words (or characters, or substrings, depending on the granularity of your model)
Numericalization:: Make a list of all of the unique words that appear (the vocab), and convert each word into a number, by looking up its index in the vocab
Language model data loader creation:: fastai provides an LMDataLoader class which automatically handles creating a dependent variable that is offset from the independent variable by one token. It also handles some important details, such as how to shuffle the training data in such a way that the dependent and independent variables maintain their structure as required
Language model creation:: We need a special kind of model that does something we haven’t seen before: handles input lists which could be arbitrarily big or small. There are a number of ways to do this; in this chapter we will be using a recurrent neural network (RNN). We will get to the details of these RNNs in the <>, but for now, you can think of it as just another deep neural network.
Analysis: The issue here is that while the question says “steps to prepare your data” the relevant context has the phrasing “steps necessary to create a language model”. There are 11 other occurences of the word “steps” in the chapter, and 0 occurences of the word “prepare.”
Conclusion: Keep the question in the evaluation set. Semantic search might perform better.
Tags: insufficient keywords, semantic search
Question 12
print_data(29)
Chapter, Question Number: 10 12
Question Text: ""List four rules that fastai applies to text during tokenization.""
Answer: ""Here are all the rules:
fix_html :: replace special HTML characters by a readable version (IMDb reviews have quite a few of them for instance) ;
replace_rep :: replace any character repeated three times or more by a special token for repetition (xxrep), the number of times it's repeated, then the character ;
replace_wrep :: replace any word repeated three times or more by a special token for word repetition (xxwrep), the number of times it's repeated, then the word ;
spec_add_spaces :: add spaces around / and # ;
rm_useless_spaces :: remove all repetitions of the space character ;
replace_all_caps :: lowercase a word written in all caps and adds a special token for all caps (xxcap) in front of it ;
replace_maj :: lowercase a capitalized word and adds a special token for capitalized (xxmaj) in front of it ;
lowercase :: lowercase all text and adds a special token at the beginning (xxbos) and/or the end (xxeos).""
Keywords: "rules, fastai, text, tokenization, tokens"
Retrieved Context:
These special tokens don’t come from spaCy directly. They are there because fastai adds them by default, by applying a number of rules when processing text. These rules are designed to make it easier for a model to recognize the important parts of a sentence. In a sense, we are translating the original English language sequence into a simplified tokenized language—a language that is designed to be easy for a model to learn.
For instance, the rules will replace a sequence of four exclamation points with a special repeated character token, followed by the number four, and then a single exclamation point. In this way, the model’s embedding matrix can encode information about general concepts such as repeated punctuation rather than requiring a separate token for every number of repetitions of every punctuation mark. Similarly, a capitalized word will be replaced with a special capitalization token, followed by the lowercase version of the word. This way, the embedding matrix only needs the lowercase versions of the words, saving compute and memory resources, but can still learn the concept of capitalization.
Here is a brief summary of what each does:
fix_html:: Replaces special HTML characters with a readable version (IMDb reviews have quite a few of these)
replace_rep:: Replaces any character repeated three times or more with a special token for repetition (xxrep), the number of times it’s repeated, then the character
replace_wrep:: Replaces any word repeated three times or more with a special token for word repetition (xxwrep), the number of times it’s repeated, then the word
spec_add_spaces:: Adds spaces around / and #
rm_useless_spaces:: Removes all repetitions of the space character
replace_all_caps:: Lowercases a word written in all caps and adds a special token for all caps (xxup) in front of it
replace_maj:: Lowercases a capitalized word and adds a special token for capitalized (xxmaj) in front of it
lowercase:: Lowercases all text and adds a special token at the beginning (xxbos) and/or the end (xxeos)
Analysis: The two most important keywords, “four” and “rules”, are not present in the key bulleted list of relevant context that lists all of the fastai rules.
Conclusion: Perhaps a different chunking strategy would have yielded better retrieval using the keyword-based search.
Tags: chunking strategy
Question 17
print_data(30)
Chapter, Question Number: 10 17
Question Text: ""Why do we need padding for text classification? Why don't we need it for language modeling?""
Answer: ""Since the documents have variable sizes, padding is needed to collate the batch. Other approaches. like cropping or squishing, either to negatively affect training or do not make sense in this context. Therefore, padding is used. It is not required for language modeling since the documents are all concatenated.""
Keywords: "padding, text, classification, language, modeling, need"
Relevant Context:
We will expand the shortest texts to make them all the same size. To do this, we use a special padding token that will be ignored by our model. Additionally, to avoid memory issues and improve performance, we will batch together texts that are roughly the same lengths (with some shuffling for the training set). We do this by (approximately, for the training set) sorting the documents by length prior to each epoch. The result of this is that the documents collated into a single batch will tend to be of similar lengths. We won’t pad every batch to the same size, but will instead use the size of the largest document in each batch as the target size. (It is possible to do something similar with images, which is especially useful for irregularly sized rectangular images, but at the time of writing no library provides good support for this yet, and there aren’t any papers covering it. It’s something we’re planning to add to fastai soon, however, so keep an eye on the book’s website; we’ll add information about this as soon as we have it working well.)
The sorting and padding are automatically done by the data block API for us when using a TextBlock, with is_lm=False. (We don’t have this same issue for language model data, since we concatenate all the documents together first, and then split them into equally sized sections.)
Analysis: There are four occurences of the word “padding” in the chapter, it occurs once in each of the relevant paragraphs. There are 80+ occurences of the keywords “text” and 70+ occurences of “language” in the chapter.
Conclusion: Keep the question in the evaluation set. Semantic search might perform better.
Tags: distracting keywords, semantic search
Question 20
print_data(31)
Chapter, Question Number: 10 20
Question Text: ""Why do we have to pass the vocabulary of the language model to the classifier data block?""
Answer: ""This is to ensure the same correspondence of tokens to index so the model can appropriately use the embeddings learned during LM fine-tuning.""
Keywords: "vocabulary, language, model, classifier, data, block"
Relevant Context:
The reason that we pass the vocab of the language model is to make sure we use the same correspondence of token to index. Otherwise the embeddings we learned in our fine-tuned language model won’t make any sense to this model, and the fine-tuning step won’t be of any use.
Analysis: Only two of the keywords (“language” and “model”) are in the relevant context. Those two words also have very high occurences in the chapter (70 and 120, respectively). The main keyword, “vocabulary” is not in the relevant context (a different form of it is, “vocab”).
Conclusion: Keep the question in the evaluation set. Semantic search might work better (finding similarity between “vocab” and “vocabulary”).
Chapter, Question Number: 10 22
Question Text: ""Why is text generation always likely to be ahead of automatic identification of machine-generated texts?""
Answer: ""The classification models could be used to improve text generation algorithms (evading the classifier) so the text generation algorithms will always be ahead.""
Keywords: "text, generation, automatic, identification, machine-generated, texts"
Relevant Context:
Many people assume or hope that algorithms will come to our defense here—that we will develop classification algorithms that can automatically recognise autogenerated content. The problem, however, is that this will always be an arms race, in which better classification (or discriminator) algorithms can be used to create better generation algorithms.
Analysis: None of the keywords are present in the relevant context. (“automatically” is, but not “automatic”).
Conclusion: Keep the question in the evaluation set. I expect semantic search to perform better.
Tags: insufficient keywords, semantic search
Chapter 13 (6 questions)
Question 4
print_data(33)
Chapter, Question Number: 13 4
Question Text: ""What is the value of a convolutional kernel apply to a 3×3 matrix of zeros?""
Answer: ""A zero matrix.""
Keywords: "convolutional, kernel, matrix, zeros, value"
Relevant Context:
Now we’re going to take the top 3×3-pixel square of our image, and multiply each of those values by each item in our kernel. Then we’ll add them up, like so:
Not very interesting so far—all the pixels in the top-left corner are white.
Analysis: This is a tough context to retrieve for full text search because it relies on interpreting multiple lines of code.
Conclusion: Keep the question in the evaluation set. Semantic search might perform better.
Tags: insufficient keywords, semantic search
Question 5
print_data(34)
Chapter, Question Number: 13 5
Question Text: ""What is ""padding""?""
Answer: ""Padding is the additional pixels that are added around the outside of the image, allows the kernel to be applied to the edge of the image for a convolution.""
Keywords: "padding, paddings, cushion, cushions, fill, filler"
Relevant Context:
It would be nice to not lose those two pixels on each axis. The way we do that is to add padding, which is simply additional pixels added around the outside of our image. Most commonly, pixels of zeros are added.
Analysis: I was surprised that none of the full text search methods retrieved this relevant context, since it’s usually good with terms/definitions. There are 15 other occurences of “padding” in the chapter.
Conclusion: Keep the question in the evaluation set. Semantic search might perform better.
Tags: insufficient keywords, semantic search
Question 15
print_data(35)
Chapter, Question Number: 13 15
Question Text: ""Why does the third layer of the MNIST CNN have 7*7*(1168-16) multiplications?""
Answer: ""There are 1168 parameters for that layer, and ignoring the 16 parameters (=number of filters) of the bias, the (1168-16) parameters is applied to the 7x7 grid.""
Keywords: "MNIST, CNN, layer, layers, multiplication, multiplications"
Relevant Context:
There is one bias for each channel. (Sometimes channels are called features or filters when they are not input channels.) The output shape is 64x4x14x14, and this will therefore become the input shape to the next layer. The next layer, according to summary, has 296 parameters. Let’s ignore the batch axis to keep things simple. So for each of 1414=196 locations we are multiplying 296-8=288 weights (ignoring the bias for simplicity), so that’s 196288=56_448 multiplications at this layer. The next layer will have 77(1168-16)=56_448 multiplications.
Analysis: I’m not sure an LLM would be able to deduce why the multiplication 77(1168-16) is needed. This might be too difficult a question to answer.
Conclusion: Keep the question in the evaluation set. Even though it’s difficult to answer.
Tags: difficult question
Question 22
print_data(36)
Chapter, Question Number: 13 22
Question Text: ""What method can we use to see that data in DataLoaders?""
Answer: ""show_batch""
Keywords: "method, data, dataloaders, dataloader, view, visualize"
Relevant Context:
Remember, it’s always a good idea to look at your data before you use it:
dls.show_batch(max_n=9, figsize=(4,4))
Analysis: The keyword “view” does not appear in the relevant context, though it does appear in 6 other places in the chapter.
Conclusion: Keep the question in the evaluation set. I expect semantic search to perform better.
Tags: insufficient keywords, semantic search
Question 24
print_data(37)
Chapter, Question Number: 13 24
Question Text: ""Why do we use a larger kernel in the first conv with MNIST (with simple_cnn)?""
Answer: ""With the first layer, if the kernel size is 3x3, with four output filters, then nine pixels are being used to produce 8 output numbers so there is not much learning since input and output size are almost the same. Neural networks will only create useful features if they're forced to do so—that is, if the number of outputs from an operation is significantly smaller than the number of inputs. To fix this, we can use a larger kernel in the first layer.""
Keywords: "kernel, conv, MNIST, simple_cnn, larger"
Relevant Context:
But there is a subtle problem with this. Consider the kernel that is being applied to each pixel. By default, we use a 3×3-pixel kernel. That means that there are a total of 3x3 = 9 pixels that the kernel is being applied to at each location. Previously, our first layer had four output filters. That meant that there were four values being computed from nine pixels at each location. Think about what happens if we double this output to eight filters. Then when we apply our kernel we will be using nine pixels to calculate eight numbers. That means it isn’t really learning much at all: the output size is almost the same as the input size. Neural networks will only create useful features if they’re forced to do so—that is, if the number of outputs from an operation is significantly smaller than the number of inputs.
To fix this, we can use a larger kernel in the first layer. If we use a kernel of 5x5 pixels then there are 25 pixels being used at each kernel application. Creating eight filters from this will mean the neural net will have to find some useful features:
Analysis: The most important keyword, “first” was not generated by Claude for this question. Two of the other keywords, “conv” and “kernel”, have almost 200 occurences in the chapter.
Conclusion: Keep the question in the evaluation set. I expect semantic search to perform better.
Chapter, Question Number: 13 27
Question Text: ""What are the three statistics plotted by plot_layer_stats? What does the x-axis represent?""
Answer: ""The mean and standard deviation of the activations, as well as the percentage of activation near zero. The x-axis represents the progress of training (batch number).""
Keywords: "plot_layer_stats, statistics, x-axis, plotted, layers"
Relevant Context:
ActivationStats includes some handy utilities for plotting the activations during training. plot_layer_stats(idx) plots the mean and standard deviation of the activations of layer number idx, along with the percentage of activations near zero. Here’s the first layer’s plot:
Analysis: Many of the full text search methods retrieved this paragraph. However, that only answers the first part of the question. An answer to the second part of the question, “What does the x-axis represent?” is not explicitly provided in the chapter text. You would have to infer it from the image (which is not included in the database).
Conclusion: Remove the question from the evaluation set.
Tags: unanswerable, requires image
Final Thoughts
Here is a summary of the tags I assigned to each question:
Tag
Count
Percentage of 39
Percentage of 202
insufficient keywords
25
64%
12%
semantic search
23
59%
11%
unanswerable
9
21%
4%
distracting keywords
8
10%
4%
difficult questions
5
13%
2%
chunking strategy
3
8%
1%
requires image
2
5%
1%
If my intuition is correct, and 23 of the questions that were not answered by any full text search method will be answered by semantic search, I might see a 11% increase in overall performance (from 76.7% to ~88%).
There are 9 unanswerable questions, which is 4% of the overall evaluation set. This would improve the overall Answer Rate from 76.7% to ~81% (which is not bad for a baseline full text search!)
Pursuing a different chunking strategy will only improve performance by 1%. However, if the rate of questions that might be improved by a better chunking strategy is 8% (for these 39 questions) and that rate is applicable to the rest of the 163 questions, I could potentially improve the overall Answer Rate by 8%.
Of course, this is all speculation at this point and will be determined after I evaluate the semantic search baselines.
Here are the number of unanswered questions per chapter:
Chapter
# of Questions
1
2
2
4
4
7
8
10
9
5
10
5
13
6
Total
39
Here are the tags broken down by chapter:
Chapter
Tag
Count
1
semantic search
2
1
insufficient keywords
2
1
distracting keywords
1
2
insufficient keywords
3
2
distracting keywords
3
2
semantic search
2
2
difficult question
1
4
insufficient keywords
5
4
semantic search
4
4
chunking strategy
2
4
unanswerable
1
4
difficult question
1
4
distracting keywords
1
8
unanswerable
6
8
semantic search
4
8
insufficient keywords
4
8
requires image
1
9
insufficient keywords
4
9
semantic search
3
9
unanswerable
1
9
difficult question
1
10
semantic search
4
10
insufficient keywords
3
10
distracting keywords
2
10
chunking strategy
1
13
semantic search
4
13
insufficient keywords
4
13
unanswerable
1
13
distracting keywords
1
13
difficult question
1
13
requires image
1
I want to highlight that 6 of the 29 Chapter 8 questions are “unanswerable”, so removing those from the evaluation set will greatly increase the Answer Rate for that chapter.
Here are the updated full text search baseline results with the “unanswerable” questions removed from consideration.
Chapter
BM25_A (Top-1 1p)
BM25_B (Top-3 1p)
BM25_C (Top-5 1p)
BM25_D (Top-1 3p)
BM25_E (Top-3 3p)
BM25_F (Top-5 3p)
1
40% (12/30)
56.7% (17/30)
60% (18/30)
63.3% (19/30)
83.3% (25/30)
90% (27/30)
2
38.5% (10/26)
65.4% (17/26)
69.2% (18/26)
46.2% (12.26)
80.8% (21/26)
80.8% (21/26)
4
25.8% (8/31)
71% (22/31)
74.2% (23/31)
32.3% (10/31)
74.2% (23/31)
77.4% (24/31)
8
17.4% (4/23)
43.5% (10/23)
56.5% (13/23)
39.1% (9/23)
69.6% (16/23)
82.6% (19/23)
9
13.8% (4/28)
48.3% (14/28)
58.6% (17/28)
34.5% (10/28)
72.4% (21/28)
79.3% (23/28)
10
47.6% (12/21)
42.9% (9/21)
61.9% (13/21)
38% (8/21)
57.1% (12/21)
61.9% (13/21)
13
38.2% (13/34)
55.9% (19/34)
61.8% (21/34)
44.1% (15/34)
70.6% (24/34)
82.4% (28/34)
All
31.6% (61/193)
56% (108/193)
63.7% (123/193)
43% (83/193)
73.6% (142/193)
80.3% (155/193)
With the “unanswerable” questions removed, the overall performance of each method increases, with the best-performing BM25_D (Top-1 3-paragraph chunks) reaching an 80.3% Answer Rate!
I have a much better understanding of the errors made by all of the full text search methods, and this will undoubtedly improve my intuition when applying semantic search to this task.
I hope you enjoyed this blog post! Follow me on Twitter @vishal_learner.