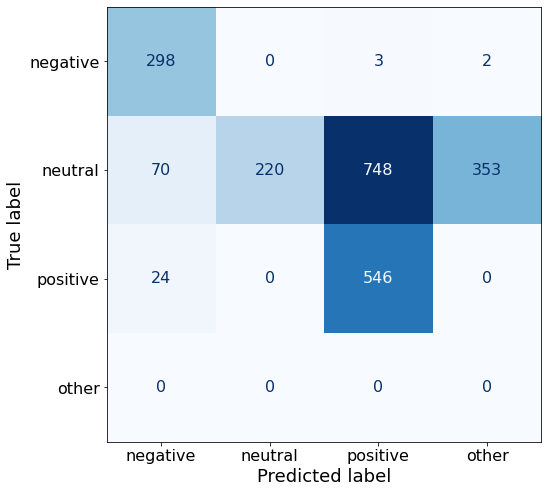
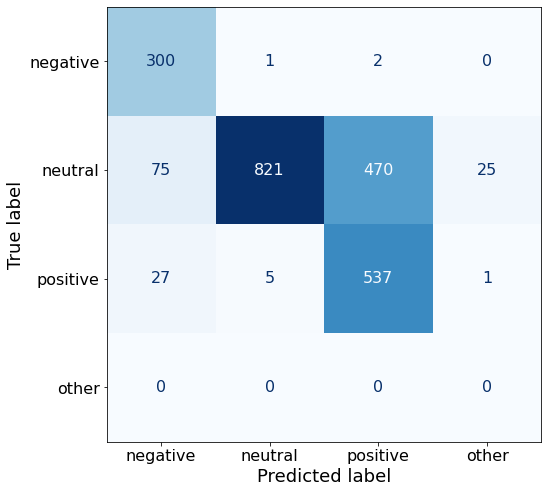
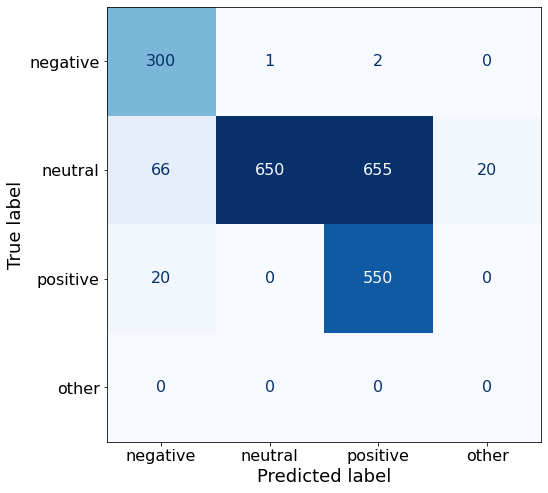
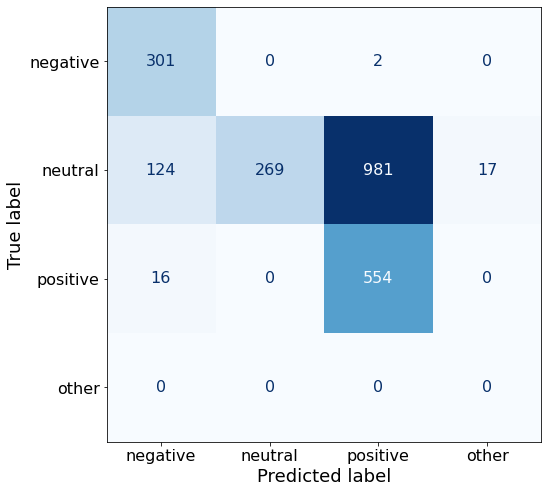
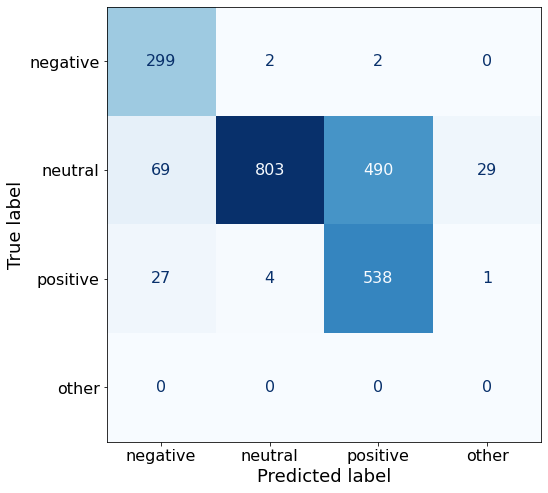
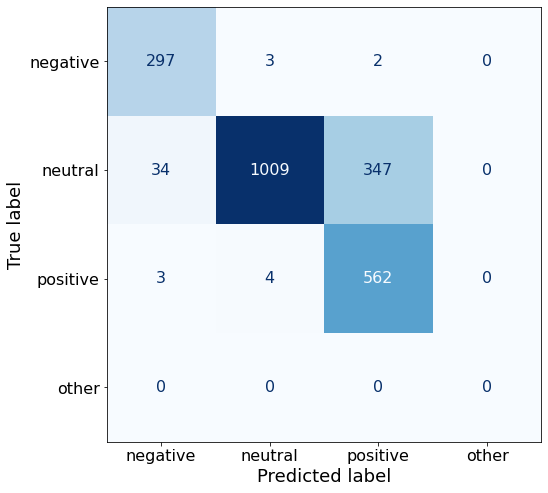
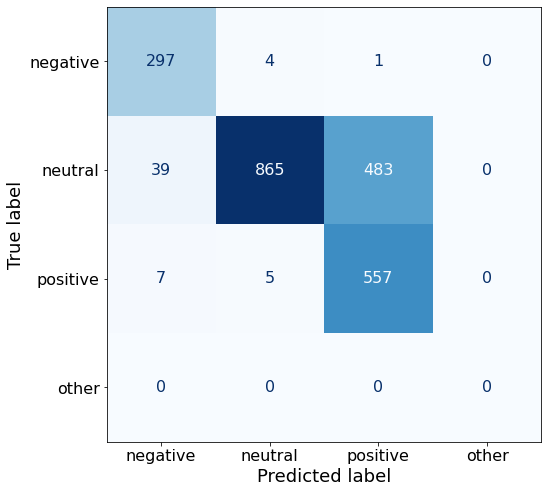
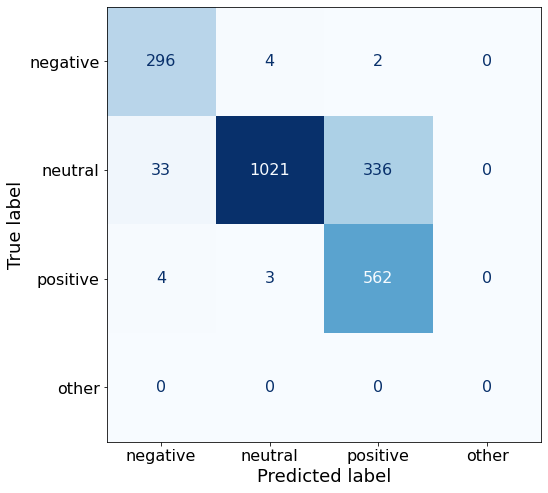
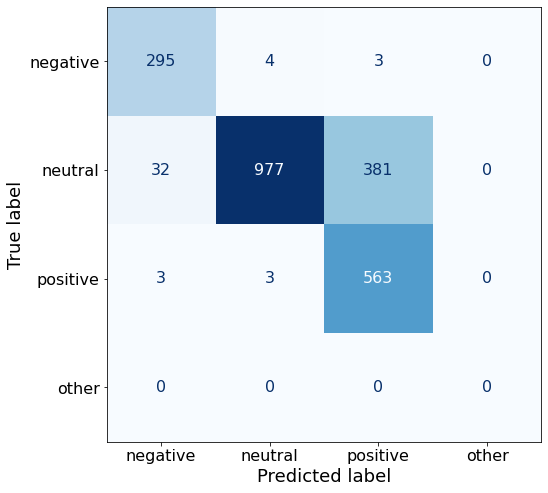
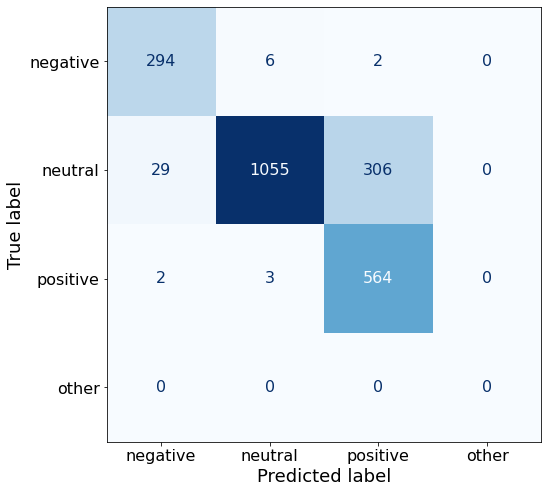
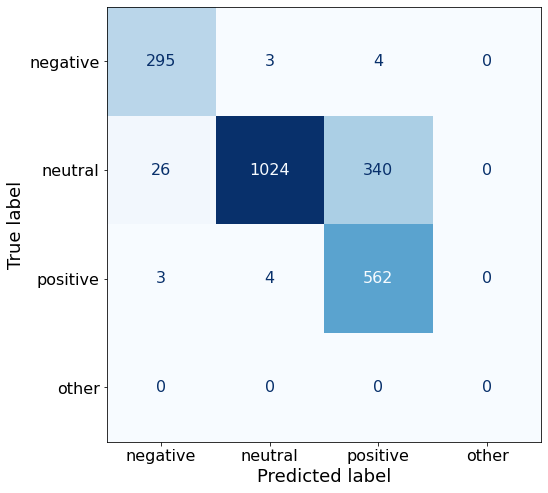
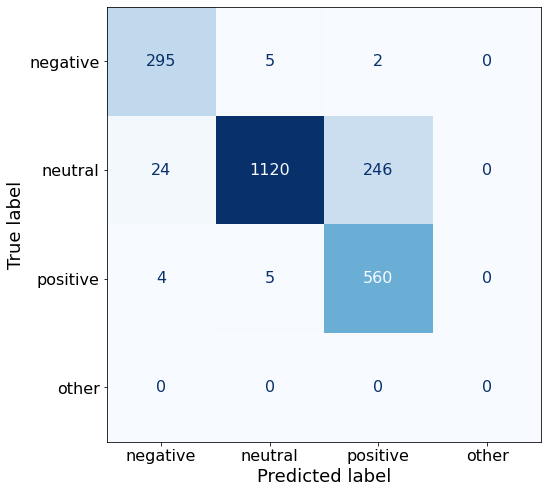
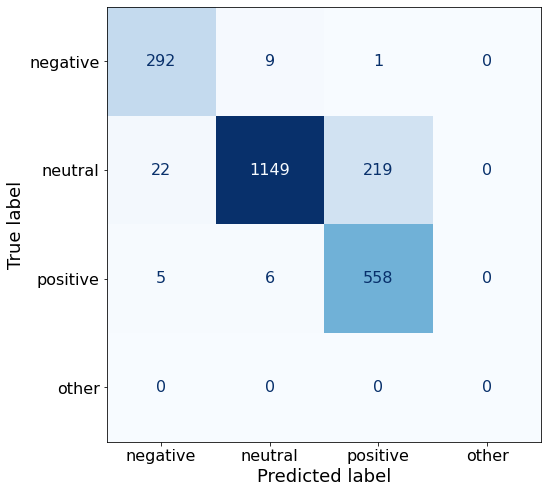
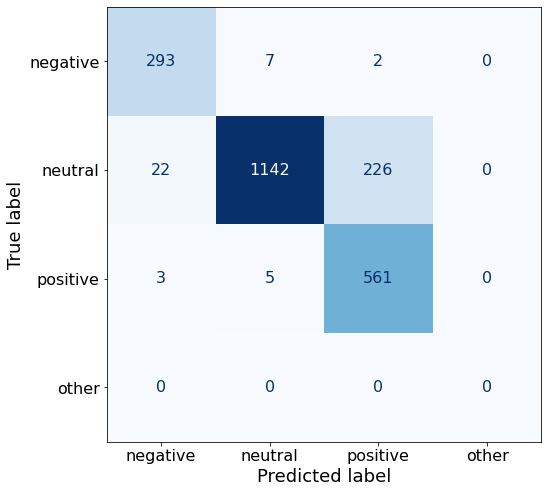
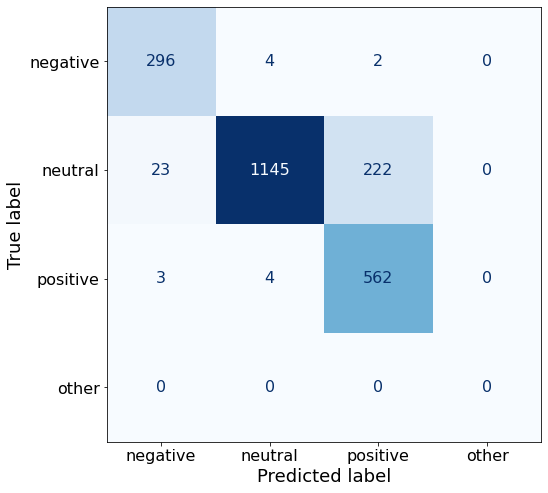
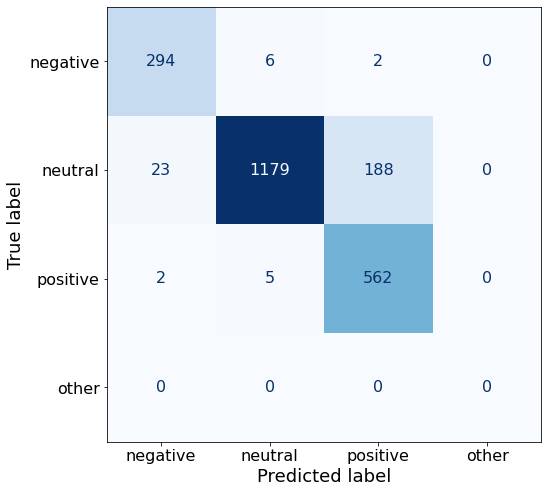
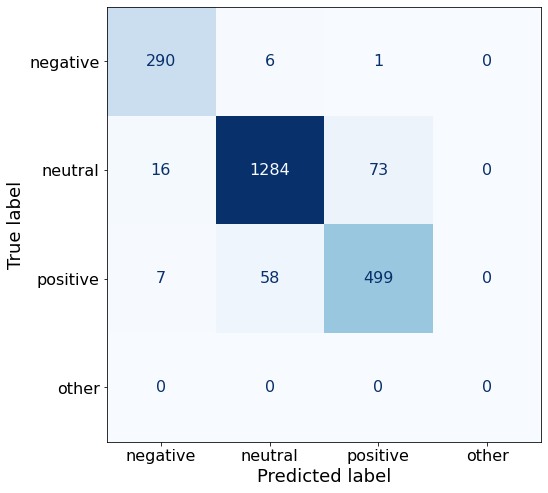
[{'role': 'system', 'content': "You are an expert in financial sentiment analysis. Your task is to accurately classify the sentiment of financial statements as negative, positive, or neutral. Consider the overall impact and implications of the statement when making your classification. If the amount of money, market share, or key performance indicators are not explicitly increasing or decreasing, respond with neutral. Consider terms like 'growth', 'decline', 'improvement', or 'deterioration' as indicators of change."}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: For the last quarter of 2010 , Componenta 's net sales doubled to EUR131m from EUR76m for the same period a year earlier , while it moved to a zero pre-tax profit from a pre-tax loss of EUR7m .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'positive'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: In the third quarter of 2010 , net sales increased by 5.2 % to EUR 205.5 mn , and operating profit by 34.9 % to EUR 23.5 mn .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'positive'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: Operating profit rose to EUR 13.1 mn from EUR 8.7 mn in the corresponding period in 2007 representing 7.7 % of net sales .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'positive'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: Operating profit totalled EUR 21.1 mn , up from EUR 18.6 mn in 2007 , representing 9.7 % of net sales .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'positive'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: Finnish Talentum reports its operating profit increased to EUR 20.5 mn in 2005 from EUR 9.3 mn in 2004 , and net sales totaled EUR 103.3 mn , up from EUR 96.4 mn .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'positive'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: Clothing retail chain Sepp+ñl+ñ 's sales increased by 8 % to EUR 155.2 mn , and operating profit rose to EUR 31.1 mn from EUR 17.1 mn in 2004 .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'positive'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: Jan. 6 -- Ford is struggling in the face of slowing truck and SUV sales and a surfeit of up-to-date , gotta-have cars .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'negative'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: Pharmaceuticals group Orion Corp reported a fall in its third-quarter earnings that were hit by larger expenditures on R&D and marketing .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'negative'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: However , the growth margin slowed down due to the financial crisis .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'negative'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: 2009 3 February 2010 - Finland-based steel maker Rautaruukki Oyj ( HEL : RTRKS ) , or Ruukki , said today it slipped to a larger-than-expected pretax loss of EUR46m in the fourth quarter of 2009 from a year-earlier profit of EUR45m .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'negative'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: ( ADPnews ) - Feb 3 , 2010 - Finland-based steel maker Rautaruukki Oyj ( HEL : RTRKS ) , or Ruukki , said today it slipped to a larger-than-expected pretax loss of EUR 46 million ( USD 64.5 m ) in the fourth quarter of 2009 from a\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'negative'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: Result before taxes decreased to nearly EUR 14.5 mn , compared to nearly EUR 20mn in the previous accounting period .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'negative'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'neutral'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: At the request of Finnish media company Alma Media 's newspapers , research manager Jari Kaivo-oja at the Finland Futures Research Centre at the Turku School of Economics has drawn up a future scenario for Finland 's national economy by using a model developed by the University of Denver .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'neutral'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: STOCK EXCHANGE ANNOUNCEMENT 20 July 2006 1 ( 1 ) BASWARE SHARE SUBSCRIPTIONS WITH WARRANTS AND INCREASE IN SHARE CAPITAL A total of 119 850 shares have been subscribed with BasWare Warrant Program .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'neutral'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: A maximum of 666,104 new shares can further be subscribed for by exercising B options under the 2004 stock option plan .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'neutral'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: Tiimari operates 194 stores in six countries -- including its core Finnish market -- and generated a turnover of 76.5 mln eur in 2005 .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'neutral'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: Finnish Talvivaara Mining Co HEL : TLV1V said Thursday it had picked BofA Merrill Lynch and JPMorgan NYSE : JPM as joint bookrunners of its planned issue of convertible notes worth up to EUR250m USD332m .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'neutral'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: The mall is part of the Baltic Pearl development project in the city of St Petersburg , where Baltic Pearl CJSC , a subsidiary of Shanghai Foreign Joint Investment Company , is developing homes for 35,000 people .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'neutral'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: Vacon controls a further 5 % of the company via investment fund Power Fund I. EUR 1.0 = USD 1.397\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'neutral'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: 4 ) Complete name of the shareholder : Otto Henrik Bernhard Nyberg 5 ) Further information : The amount of shares now transferred corresponds to 5.68 % of the total number of shares in Aspo Plc. .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'neutral'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: It has some 30 offices worldwide and more than 90 pct of its net sales are generated outside Finland .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'neutral'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: The contract value amounts to about EUR11m , the company added .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'neutral'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: The business to be divested generates consolidated net sales of EUR 60 million annually and currently has some 640 employees .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'neutral'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: The company generates net sales of about 600 mln euro $ 775.5 mln annually and employs 6,000 .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'neutral'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: The contract covers the manufacturing , surface-treatment and installation of the steel structures .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'neutral'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: The order also includes start-up and commissioning services .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'neutral'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: The phones are targeted at first time users in growth markets .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'neutral'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: Tielinja generated net sales of 7.5 mln euro $ 9.6 mln in 2005 .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'neutral'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: Tikkurila Powder Coatings has some 50 employees at its four paint plants , which generated revenues of EUR2 .4 m USD3 .3 m in 2010 .\nRespond with a single word: negative, positive, or neutral"}, {'role': 'assistant', 'content': 'neutral'}, {'role': 'user', 'content': "Your task is to analyze the sentiment (from an investor's perspective) of the text below.\nRespond with a single word: negative, positive, or neutral\nTEXT: Consolidated net sales increased 16 % to reach EUR74 .8 m , while operating profit amounted to EUR0 .9 m compared to a loss of EUR0 .7 m in the prior year period .\nRespond with a single word: negative, positive, or neutral"}]