Conducting a Question-by-Question Error Analysis on Semantic Search Results
python
RAG
information retrieval
fastbookRAG
In this blog post, I conduct a detailed error analysis of 29 questions (from a set of 193), where none of the 6 semantic search methods retrieved sufficient context to answer them. I examine each question, categorize the errors, and discuss potential improvements and implications for future work.
Author
Vishal Bakshi
Published
October 22, 2024
Background
In this notebook I’ll do a deep dive error analysis of my semantic search results, where I implemented 6 different keyword-based full text searches to retrieve context sufficient to answer questions from the end-of-chapter Questionnaires in fastbook. Here is the summary of results from those experiments:
Chapter
CS_A (Top-1 1p)
CS_B (Top-3 1p)
CS_C (Top-5 1p)
CS_D (Top-1 3p)
CS_E (Top-3 3p)
CS_F (Top-5 3p)
1
40% (12/30)
63.33% (19/30)
63.33% (19/30)
46.67% (14/30)
80% (24/30)
90% (27/30)
2
26.92% (7/26)
61.54% (16/26)
69.23% (18/26)
53.85% (14/26)
80.77% (21/26)
84.62% (22/26)
4
29.03% (9/31)
54.84% (17/31)
64.52% (20/31)
25.81% (8/31)
67.74% (21/31)
80.65% (25/31)
8
17.39% (4/23)
43.48% (10/23)
47.83% (11/23)
43.48% (10/23)
73.91% (17/23)
91.30% (21/23)
9
28.57% (8/28)
46.43% (13/28)
53.57% (15/28)
42.86% (12/28)
57.14% (16/28)
75% (21/28)
10
42.86% (9/21)
47.62% (10/21)
47.62% (10/21)
47.62% (10/21)
52.38% (11/21)
57.14% (12/21)
13
41.18% (14/34)
58.82% (20/34)
61.76% (21/34)
47.06% (16/34)
70.59% (24/34)
79.41% (27/34)
All
32.64% (63/193)
54.40% (105/193)
59.07% (114/193)
43.52% (84/193)
69.43% (134/193)
80.31% (155/193)
The granular question-level results are available in this public gist.
As a reminder, the two metrics I use for evaluation are Score and Answer Rate
The evaluation metric for each question, that I’m simply calling score, is binary: can the retrieved context answer the question (1) or not (0)? The evaluation metric across a set of questions, which I’m calling the Answer Rate, is the mean score for those questions.
While this is a straightforward pair of metrics, they do involve some judgment. After reading the retrieved context, I decide if it’s enough to answer the question.
Here is a summary of tags across the 29 questions where the Answer Rate for all of my semantic search methods was 0% (i.e. none of the methods retrieved the context needed to answer the question):
Tag
Count
unknown failure
12
chunking strategy
9
keyword-based question
4
difficult question
2
unanswerable
2
requires image
1
Here is a summary of how many 0% Answer Rate questions there are for each chapter:
Chapter
# of Questions with 0% Answer Rate
% of Chapter Questions
9
7
25%
10
7
33%
13
5
15%
2
4
15%
1
2
7%
4
2
6%
8
2
9%
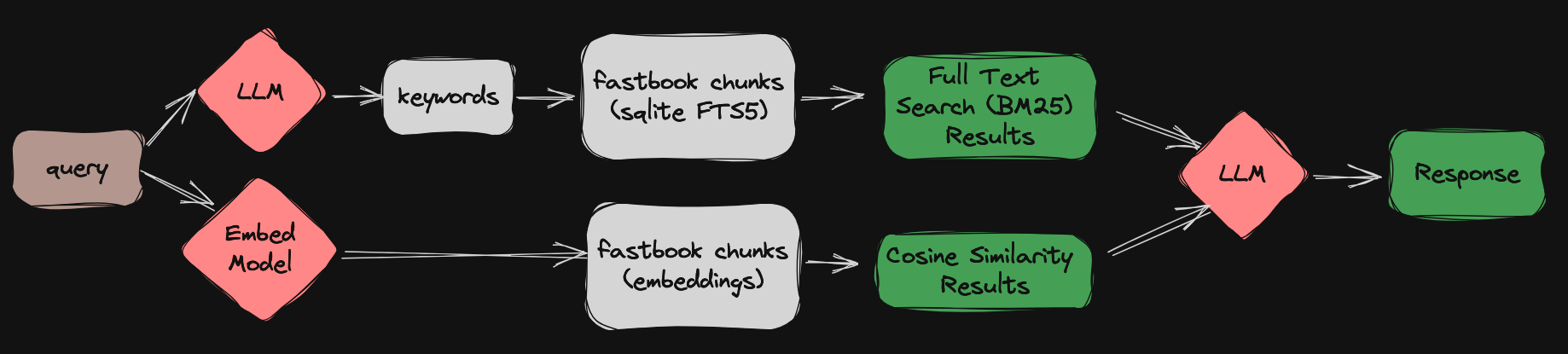
This notebook is a part of series of blog posts for a project I’m calling fastbookRAG where I’m trying to answer questions from the fastbook end-of-chapter Questionnaires using the following pipeline:
fastbookRAG diagram
Error Analysis
For 29 questions, none of the 6 semantic search methods retrieved sufficient context to provide an answer. I’ll be looking at each of those 29 questions, their “gold standard” answer (obtained from the fastai Forums Questionnaire wikis), and the relevant context from the fastbook chapter.
I have three objectives for this error analysis:
Understand what kinds of questions are difficult to answer using semantic search.
Identify ambigious questions that need to be removed from the evaluation set.
Identify unanswerable questions that need to be removed.
The overarching goal of this analysis: look at your data!
For each of the 29 questions, I will write four sections:
Relevant Context: the paragraph(s) from the fastbook text that are sufficient to answer the question.
Analysis: my interpretation/explanation for why a semantic search did not retrieve the context.
Conclusion: what I think is needed to retrieve the sufficient context (or if I think this question should be removed)
Chapter, Question Number: 1 16
Question Text: ""What do you need in order to train a model?""
Answer: ""You will need an architecture for the given problem. You will need data to input to your model. For most use-cases of deep learning, you will need labels for your data to compare your model predictions to. You will need a loss function that will quantitatively measure the performance of your model. And you need a way to update the parameters of the model in order to improve its performance (this is known as an optimizer).""
Relevant Context:
From this picture we can now see some fundamental things about training a deep learning model:
A model cannot be created without data.
A model can only learn to operate on the patterns seen in the input data used to train it.
This learning approach only creates predictions, not recommended actions.
It’s not enough to just have examples of input data; we need labels for that data too (e.g., pictures of dogs and cats aren’t enough to train a model; we need a label for each one, saying which ones are dogs, and which are cats).
Machine learning is a discipline where we define a program not by writing it entirely ourselves, but by learning from data. Deep learning is a specialty within machine learning that uses neural networks with multiple layers. Image classification is a representative example (also known as image recognition). We start with labeled data; that is, a set of images where we have assigned a label to each image indicating what it represents. Our goal is to produce a program, called a model, which, given a new image, will make an accurate prediction regarding what that new image represents.
Every model starts with a choice of architecture, a general template for how that kind of model works internally. The process of training (or fitting) the model is the process of finding a set of parameter values (or weights) that specialize that general architecture into a model that works well for our particular kind of data. In order to define how well a model does on a single prediction, we need to define a loss function, which determines how we score a prediction as good or bad.
Analysis:
Some of the methods did retrieve the first paragraph and bulleted list, however the key paragraph “Every model starts with a choice of architecture…” was not retrieved by any semantic search method.
Conclusion:
I would expect that increasing the chunk size would result in semantic search methods retrieving the relevant context.
Tags: chunking strategy
Question 28
print_data(1)
Chapter, Question Number: 1 28
Question Text: ""Are image models only useful for photos?""
Answer: ""Nope! Image models can be useful for other types of images like sketches, medical data, etc.
However, a lot of information can be represented as images . For example, a sound can be converted into a spectrogram, which is a visual interpretation of the audio. Time series (ex: financial data) can be converted to image by plotting on a graph. Even better, there are various transformations that generate images from time series, and have achieved good results for time series classification. There are many other examples, and by being creative, it may be possible to formulate your problem as an image classification problem, and use pretrained image models to obtain state-of-the-art results!""
Relevant Context:
An image recognizer can, as its name suggests, only recognize images. But a lot of things can be represented as images, which means that an image recogniser can learn to complete many tasks.
Analysis:
I was surprised that semantic search did not find the relevant context for this question. Some methods, like CS_F (Top-5 3-Paragraph Chunks) did at least retrieve a chunk from the correct section in the chapter (“Image Recognizers Can Tackle Non-Image Tasks”) but those chunks didn’t contain relevant context.
Conclusion:
While this question may not be unanswerable by semantic search in general, the methods I used certainly found it impossible to answer. However, I’m not sure why this is the case.
Tags: unknown failure
Chapter 2
Question 1
print_data(2)
Chapter, Question Number: 2 1
Question Text: ""Provide an example of where the bear classification model might work poorly in production, due to structural or style differences in the training data.""
Answer: ""Working with video data instead of images
Handling nighttime images, which may not appear in this dataset
Dealing with low-resolution camera images
Ensuring results are returned fast enough to be useful in practice
Recognizing bears in positions that are rarely seen in photos that people post online (for example from behind, partially covered by bushes, or when a long way away from the camera)""
Relevant Context:
This can result in disaster! For instance, let’s say we really were rolling out a bear detection system that will be attached to video cameras around campsites in national parks, and will warn campers of incoming bears. If we used a model trained with the dataset we downloaded there would be all kinds of problems in practice, such as:
Working with video data instead of images
Handling nighttime images, which may not appear in this dataset
Dealing with low-resolution camera images
Ensuring results are returned fast enough to be useful in practice
Recognizing bears in positions that are rarely seen in photos that people post online (for example from behind, partially covered by bushes, or when a long way away from the camera)
Analysis:
I was expecting semantic search to find similarity between “work poorly in production” and phrases in the relevant context such as “rolling out” and “problems in practice”. The retrieved context focused on other sections in the chapter talking about other ways your ML system could go awry and ways to avoid those situations.
Conclusion:
While this question may not be unanswerable by semantic search in general, the methods I used certainly found it impossible to answer. However, I’m not sure why this is the case.
Tags: unknown failure
Question 4
print_data(3)
Chapter, Question Number: 2 4
Question Text: ""In situations where a model might make mistakes, and those mistakes could be harmful, what is a good alternative to automating a process?""
Answer: ""The predictions of the model could be reviewed by human experts for them to evaluate the results and determine what is the best next step. This is especially true for applying machine learning for medical diagnoses. For example, a machine learning model for identifying strokes in CT scans can alert high priority cases for expedited review, while other cases are still sent to radiologists for review. Or other models can also augment the medical professional’s abilities, reducing risk but still improving efficiency of the workflow. For example, deep learning models can provide useful measurements for radiologists or pathologists.""
Relevant Context:
The ability of deep learning to combine text and images into a single model is, generally, far better than most people intuitively expect. For example, a deep learning model can be trained on input images with output captions written in English, and can learn to generate surprisingly appropriate captions automatically for new images! But again, we have the same warning that we discussed in the previous section: there is no guarantee that these captions will actually be correct.
Because of this serious issue, we generally recommend that deep learning be used not as an entirely automated process, but as part of a process in which the model and a human user interact closely. This can potentially make humans orders of magnitude more productive than they would be with entirely manual methods, and actually result in more accurate processes than using a human alone. For instance, an automatic system can be used to identify potential stroke victims directly from CT scans, and send a high-priority alert to have those scans looked at quickly. There is only a three-hour window to treat strokes, so this fast feedback loop could save lives. At the same time, however, all scans could continue to be sent to radiologists in the usual way, so there would be no reduction in human input. Other deep learning models could automatically measure items seen on the scans, and insert those measurements into reports, warning the radiologists about findings that they may have missed, and telling them about other cases that might be relevant.
Analysis:
The semantic search methods did retrieve context related to the topics of rollout and having a human-in-the-loop, but were not able to retrieve the relevant context needed to answer this question. Some of the retrieved context deviated from the relevant topic, focusing instead on errors in the dataset.
Conclusion:
While this question may not be unanswerable by semantic search in general, the methods I used certainly found it impossible to answer. However, I’m not sure why this is the case.
Tags: unknown failure
Question 17
print_data(4)
Chapter, Question Number: 2 17
Question Text: ""What is the difference between `item_tfms` and `batch_tfms`?""
Answer: ""item_tfms are transformations applied to a single data sample x on the CPU. Resize() is a common transform because the mini-batch of input images to a cnn must have the same dimensions. Assuming the images are RGB with 3 channels, then Resize() as item_tfms will make sure the images have the same width and height.
batch_tfms are applied to batched data samples (aka individual samples that have been collated into a mini-batch) on the GPU. They are faster and more efficient than item_tfms. A good example of these are the ones provided by aug_transforms(). Inside are several batch-level augmentations that help many models.""
Relevant Context:
Our images are all different sizes, and this is a problem for deep learning: we don’t feed the model one image at a time but several of them (what we call a mini-batch). To group them in a big array (usually called a tensor) that is going to go through our model, they all need to be of the same size. So, we need to add a transform which will resize these images to the same size. Item transforms are pieces of code that run on each individual item, whether it be an image, category, or so forth. fastai includes many predefined transforms; we use the Resize transform here:
Data augmentation refers to creating random variations of our input data, such that they appear different, but do not actually change the meaning of the data. Examples of common data augmentation techniques for images are rotation, flipping, perspective warping, brightness changes and contrast changes. For natural photo images such as the ones we are using here, a standard set of augmentations that we have found work pretty well are provided with the aug_transforms function. Because our images are now all the same size, we can apply these augmentations to an entire batch of them using the GPU, which will save a lot of time. To tell fastai we want to use these transforms on a batch, we use the batch_tfms parameter (note that we’re not using RandomResizedCrop in this example, so you can see the differences more clearly; we’re also using double the amount of augmentation compared to the default, for the same reason):
Analysis:
My guess here is that the embedding model doesn’t know how to properly embed the terms item_tfms and batch_tfms because they are parameters to a fastai function. As a result, semantic search doesn’t find the appropriate match and instead all of my semantic search methods just returned random blocks of code from the chapter that contained either item_tfms or batch_tfms.
Conclusion:
This type of jargon-specific question might not be suitable for semantic search.
Tags: keyword-based question
Question 27
print_data(5)
Chapter, Question Number: 2 27
Question Text: ""What are the three steps in the deployment process?""
Answer: ""Manual process – the model is run in parallel and not directly driving any actions, with humans still checking the model outputs.
Limited scope deployment – The model’s scope is limited and carefully supervised. For example, doing a geographically and time-constrained trial of model deployment, that is carefully supervised.
Gradual expansion – The model scope is gradually increased, while good reporting systems are implemented in order to check for any significant changes to the actions taken compared to the manual process (i.e. the models should perform similarly to the humans, unless it is already anticipated to be better).""
Relevant Context:
Where possible, the first step is to use an entirely manual process, with your deep learning model approach running in parallel but not being used directly to drive any actions. The humans involved in the manual process should look at the deep learning outputs and check whether they make sense. For instance, with our bear classifier a park ranger could have a screen displaying video feeds from all the cameras, with any possible bear sightings simply highlighted in red. The park ranger would still be expected to be just as alert as before the model was deployed; the model is simply helping to check for problems at this point.
The second step is to try to limit the scope of the model, and have it carefully supervised by people. For instance, do a small geographically and time-constrained trial of the model-driven approach. Rather than rolling our bear classifier out in every national park throughout the country, we could pick a single observation post, for a one-week period, and have a park ranger check each alert before it goes out.
Then, gradually increase the scope of your rollout. As you do so, ensure that you have really good reporting systems in place, to make sure that you are aware of any significant changes to the actions being taken compared to your manual process. For instance, if the number of bear alerts doubles or halves after rollout of the new system in some location, we should be very concerned. Try to think about all the ways in which your system could go wrong, and then think about what measure or report or picture could reflect that problem, and ensure that your regular reporting includes that information.
Analysis:
All of the semantic search methods retrieved context that was related to deployment, and some even retrieved the HTML image tag for the relevant “Deployment process”, but none of them retrieved the relevant paragraphs. It’s interesting to note that 1-Paragraph chunk methods retrieved the “Deployment process” image tag but non of the 3-Paragraph chunk methods retrieved any chunks from the correct section “## How to avoid disaster”
Conclusion:
While this question may not be unanswerable by semantic search in general, the methods I used certainly found it impossible to answer. However, I’m not sure why this is the case.
Tags: unknown failure
Chapter 4
Question 10
print_data(6)
Chapter, Question Number: 4 10
Question Text: ""What is broadcasting?""
Answer: ""Scientific/numerical Python packages like NumPy and PyTorch will often implement broadcasting that often makes code easier to write. In the case of PyTorch, tensors with smaller rank are expanded to have the same size as the larger rank tensor. In this way, operations can be performed between tensors with different rank.""
Relevant Context:
Take another look at our function mnist_distance, and you’ll see we have there the subtraction (a-b). The magic trick is that PyTorch, when it tries to perform a simple subtraction operation between two tensors of different ranks, will use broadcasting. That is, it will automatically expand the tensor with the smaller rank to have the same size as the one with the larger rank. Broadcasting is an important capability that makes tensor code much easier to write.
After broadcasting so the two argument tensors have the same rank, PyTorch applies its usual logic for two tensors of the same rank: it performs the operation on each corresponding element of the two tensors, and returns the tensor result. For instance:
Analysis:
All of my semantic search approaches retrieved chunks from the correct chapter section (“Computing Metrics Using Broadcasting”) but not the two relevant chunks needed to answer the question. This might be a scenario where including the markdown heading in each chunk’s text distracts the search from finding relevant context.
Conclusion:
I’m going to attribute the lack of retrieval to chunking strategy.
Tags: chunking strategy
Question 12
print_data(7)
Chapter, Question Number: 4 12
Question Text: ""What is SGD?""
Answer: ""SGD, or stochastic gradient descent, is an optimization algorithm. Specifically, SGD is an algorithm that will update the parameters of a model in order to minimize a given loss function that was evaluated on the predictions and target. The key idea behind SGD (and many optimization algorithms, for that matter) is that the gradient of the loss function provides an indication of how that loss function changes in the parameter space, which we can use to determine how best to update the parameters in order to minimize the loss function. This is what SGD does.""
Relevant Context:
To be more specific, here are the steps that we are going to require, to turn this function into a machine learning classifier:
Initialize the weights.
For each image, use these weights to predict whether it appears to be a 3 or a 7.
Based on these predictions, calculate how good the model is (its loss).
Calculate the gradient, which measures for each weight, how changing that weight would change the loss
Step (that is, change) all the weights based on that calculation.
Go back to the step 2, and repeat the process.
Iterate until you decide to stop the training process (for instance, because the model is good enough or you don’t want to wait any longer).
We need to define first what we mean by “best.” We define this precisely by choosing a loss function, which will return a value based on a prediction and a target, where lower values of the function correspond to “better” predictions. It is important for loss functions to return lower values when predictions are more accurate, as the SGD procedure we defined earlier will try to minimize this loss. For continuous data, it’s common to use mean squared error:
As we’ve seen, we need gradients in order to improve our model using SGD, and in order to calculate gradients we need some loss function that represents how good our model is. That is because the gradients are a measure of how that loss function changes with small tweaks to the weights.
Looking good! We’re already about at the same accuracy as our “pixel similarity” approach, and we’ve created a general-purpose foundation we can build on. Our next step will be to create an object that will handle the SGD step for us. In PyTorch, it’s called an optimizer.
Analysis:
There are 4 chunks in the chapter needed to answer the question in a way that matches the gold standard. Each of the 4 chunks are located in a different section of the chapter (“Stochastic Gradient Descent (SGD)”, “An End-to-End SGD Example”, “The MNIST Loss Function”, “Putting It All Together”). Three of the semantic search methods I used retrieved only one of these four chunks.
Conclusion:
I consider this a very difficult question to answer because there are at least 4 chunks needed to answer it and these chunks are spread out across the chapter. I’m attributing this error to chunking strategy.
Tags: chunking strategy
Chapter 8
Question 14
print_data(8)
Chapter, Question Number: 8 14
Question Text: ""What does x[:,0] return?""
Answer: ""The user ids""
Relevant Context:
Note that the input of the model is a tensor of shape batch_size x 2, where the first column (x[:, 0]) contains the user IDs and the second column (x[:, 1]) contains the movie IDs. As explained before, we use the embedding layers to represent our matrices of user and movie latent factors:
Analysis:
Similar to Chapter 2 Question 17, this question is about a specific code syntax, and maybe the embedding model didn’t know how to correctly embed those tokens if it wasn’t trained on PyTorch code?
Conclusion:
This type of jargon-specific question might not be suitable for semantic search.
Tags: keyword-based question
Question 18
print_data(9)
Chapter, Question Number: 8 18
Question Text: ""What is the use of bias in a dot product model?""
Answer: ""A bias will compensate for the fact that some movies are just amazing or pretty bad. It will also compensate for users who often have more positive or negative recommendations in general.""
Relevant Context:
This is a reasonable start, but we can do better. One obvious missing piece is that some users are just more positive or negative in their recommendations than others, and some movies are just plain better or worse than others. But in our dot product representation we do not have any way to encode either of these things. If all you can say about a movie is, for instance, that it is very sci-fi, very action-oriented, and very not old, then you don’t really have any way to say whether most people like it.
That’s because at this point we only have weights; we do not have biases. If we have a single number for each user that we can add to our scores, and ditto for each movie, that will handle this missing piece very nicely. So first of all, let’s adjust our model architecture:
Analysis:
I can’t say for sure, but I feel like there’s something about how the relevant context is worded that caused a lack of similarity between the question and context embeddings. Neither paragraph chunks mention the word “bias” (the second paragraph uses the word “biases”) and the answer is not explicitly stated in a single sentence (i.e. “in a dot product model the bias encodes how some users are more positive or negative in their recommendations or how some movies are just plain better or worse than others”). I don’t have a strong intuition about embeddings yet and perhaps what I am suggesting is more applicable to a keyword-based search.
Conclusion:
While this question may not be unanswerable by semantic search in general, the methods I used certainly found it impossible to answer. However, I’m not sure why this is the case.
Tags: unknown failure
Chapter 9
Question 5
print_data(10)
Chapter, Question Number: 9 5
Question Text: ""How do entity embeddings reduce memory usage and speed up neural networks?""
Answer: ""Especially for large datasets, representing the data as one-hot encoded vectors can be very inefficient (and also sparse). On the other hand, using entity embeddings allows the data to have a much more memory-efficient (dense) representation of the data. This will also lead to speed-ups for the model.""
Relevant Context:
Entity embedding not only reduces memory usage and speeds up neural networks compared with one-hot encoding, but more importantly by mapping similar values close to each other in the embedding space it reveals the intrinsic properties of the categorical variables… [It] is especially useful for datasets with lots of high cardinality features, where other methods tend to overfit… As entity embedding defines a distance measure for categorical variables it can be used for visualizing categorical data and for data clustering.
Analysis:
After re-reading the question, relevant context and the gold standard answer dozens of items, I have come to conclude that this question is unanswerable given the chapter text. The questions asks how entity embeddings reduce memory usage and speed-up neural networks, but the only relevant context I found in the chapter states that “Entity embedding not only reduces memory usage and speeds up neural networks…” and doesn’t explain how, as stated in the gold standard answer.
You could argue that the memory efficiency/inefficiency of embeddings and one-hot encoded vectors has already been addressed in Chapter 8 in the following paragraphs:
If we do that for a few indices at once, we will have a matrix of one-hot-encoded vectors, and that operation will be a matrix multiplication! This would be a perfectly acceptable way to build models using this kind of architecture, except that it would use a lot more memory and time than necessary. We know that there is no real underlying reason to store the one-hot-encoded vector, or to search through it to find the occurrence of the number one—we should just be able to index into an array directly with an integer. Therefore, most deep learning libraries, including PyTorch, include a special layer that does just this; it indexes into a vector using an integer, but has its derivative calculated in such a way that it is identical to what it would have been if it had done a matrix multiplication with a one-hot-encoded vector. This is called an embedding.
jargon: Embedding: Multiplying by a one-hot-encoded matrix, using the computational shortcut that it can be implemented by simply indexing directly. This is quite a fancy word for a very simple concept. The thing that you multiply the one-hot-encoded matrix by (or, using the computational shortcut, index into directly) is called the embedding matrix.
However, I am not searching the entire textbook for each question, I am isolating the search for Chapter 9 questions to the Chapter 9 text.
I’ll also point out that for the keyword-based results, I accepted the retrieved context as sufficient to answer the question, but upon reflection I am changing my opinion on that.
Conclusion:
This question is unanswerable given just the Chapter 9 text.
Tags: unanswerable
Question 9
print_data(11)
Chapter, Question Number: 9 9
Question Text: ""Summarize what a decision tree algorithm does.""
Answer: ""The basic idea of what a decision tree algorithm does is to determine how to group the data based on “questions” that we ask about the data. That is, we keep splitting the data based on the levels or values of the features and generate predictions based on the average target value of the data points in that group. Here is the algorithm:
Loop through each column of the dataset in turn
For each column, loop through each possible level of that column in turn
Try splitting the data into two groups, based on whether they are greater than or less than that value (or if it is a categorical variable, based on whether they are equal to or not equal to that level of that categorical variable)
Find the average sale price for each of those two groups, and see how close that is to the actual sale price of each of the items of equipment in that group. That is, treat this as a very simple “model” where our predictions are simply the average sale price of the item’s group
After looping through all of the columns and possible levels for each, pick the split point which gave the best predictions using our very simple model
We now have two different groups for our data, based on this selected split. Treat each of these as separate datasets, and find the best split for each, by going back to step one for each group
Continue this process recursively, and until you have reached some stopping criterion for each group — for instance, stop splitting a group further when it has only 20 items in it.""
Relevant Context:
Let’s consider how we find the right questions to ask. Of course, we wouldn’t want to have to create all these questions ourselves—that’s what computers are for! The basic steps to train a decision tree can be written down very easily:
Loop through each column of the dataset in turn.
For each column, loop through each possible level of that column in turn.
Try splitting the data into two groups, based on whether they are greater than or less than that value (or if it is a categorical variable, based on whether they are equal to or not equal to that level of that categorical variable).
Find the average sale price for each of those two groups, and see how close that is to the actual sale price of each of the items of equipment in that group. That is, treat this as a very simple “model” where our predictions are simply the average sale price of the item’s group.
After looping through all of the columns and all the possible levels for each, pick the split point that gave the best predictions using that simple model.
We now have two different groups for our data, based on this selected split. Treat each of these as separate datasets, and find the best split for each by going back to step 1 for each group.
Continue this process recursively, until you have reached some stopping criterion for each group—for instance, stop splitting a group further when it has only 20 items in it.
Analysis:
Only one of the semantic search methods retrieved context that was close to the desired context in the chapter:
Decision tree ensembles, as the name suggests, rely on decision trees. So let’s start there! A decision tree asks a series of binary (that is, yes or no) questions about the data. After each question the data at that part of the tree is split between a “yes” and a “no” branch, as shown in <>. After one or more questions, either a prediction can be made on the basis of all previous answers or another question is required.
However, that paragraph doesn’t address everything that’s included in the gold standard answer so I didn’t consider that as a successful retrieval.
Conclusion:
While this question may not be unanswerable by semantic search in general, the methods I used certainly found it impossible to answer. However, I’m not sure why this is the case.
Tags: unknown failure
Question 13
print_data(12)
Chapter, Question Number: 9 13
Question Text: ""How are mse, samples, and values calculated in the decision tree drawn in this chapter?""
Answer: ""By traversing the tree based on answering questions about the data, we reach the nodes that tell us the average value of the data in that group, the mse, and the number of samples in that group.""
Relevant Context:
The top node represents the initial model before any splits have been done, when all the data is in one group. This is the simplest possible model. It is the result of asking zero questions and will always predict the value to be the average value of the whole dataset. In this case, we can see it predicts a value of 10.10 for the logarithm of the sales price. It gives a mean squared error of 0.48. The square root of this is 0.69. (Remember that unless you see m_rmse, or a root mean squared error, then the value you are looking at is before taking the square root, so it is just the average of the square of the differences.) We can also see that there are 404,710 auction records in this group—that is the total size of our training set. The final piece of information shown here is the decision criterion for the best split that was found, which is to split based on the coupler_system column.
Moving down and to the left, this node shows us that there were 360,847 auction records for equipment where coupler_system was less than 0.5. The average value of our dependent variable in this group is 10.21. Moving down and to the right from the initial model takes us to the records where coupler_system was greater than 0.5.
The bottom row contains our leaf nodes: the nodes with no answers coming out of them, because there are no more questions to be answered. At the far right of this row is the node containing records where coupler_system was greater than 0.5. The average value here is 9.21, so we can see the decision tree algorithm did find a single binary decision that separated high-value from low-value auction results. Asking only about coupler_system predicts an average value of 9.21 versus 10.1.
Returning back to the top node after the first decision point, we can see that a second binary decision split has been made, based on asking whether YearMade is less than or equal to 1991.5. For the group where this is true (remember, this is now following two binary decisions, based on coupler_system and YearMade) the average value is 9.97, and there are 155,724 auction records in this group. For the group of auctions where this decision is false, the average value is 10.4, and there are 205,123 records. So again, we can see that the decision tree algorithm has successfully split our more expensive auction records into two more groups which differ in value significantly.
Analysis:
The gold standard answer is not explicitly stated (or even paraphrased) in the relevant context but serves as a summary of it. Especially without the image, I find that this is a difficult question to answer just based on the chapter’s text—you have to synthesize the information presented in both the text and the image and then summarize the overall process of how MSE, samples and values are calculated.
One of the semantic search methods did retrieve the first paragraph of the relevant context (“The top node represents the initial model…”) but I didn’t consider that sufficient to answer the question. Based just on that question (without the image and without the subsequent paragraphs) I would arrive at the conclusion that MSE, samples and values are calculated in the top node, and would not include the relevant context about traversing the tree, or how there are nodes other than the top one in the tree which contain this information.
I’m considering removing this question from the evals because of these reasons, but will keep it for now in case the LLM can deduce the correct answer given the first paragraph of context.
Conclusion:
While this question may not be unanswerable by semantic search in general, the methods I used certainly found it impossible to answer. I attribute this error to this question requiring the image to answer.
Tags: requires image
Question 14
print_data(13)
Chapter, Question Number: 9 14
Question Text: ""How do we deal with outliers, before building a decision tree?""
Answer: ""Finding out of domain data (Outliers)
Sometimes it is hard to even know whether your test set is distributed in the same way as your training data or, if it is different, then what columns reflect that difference. There’s actually a nice easy way to figure this out, which is to use a random forest!
But in this case we don’t use a random forest to predict our actual dependent variable. Instead we try to predict whether a row is in the validation set, or the training set.""
Relevant Context:
Sometimes it is hard to know whether your test set is distributed in the same way as your training data, or, if it is different, what columns reflect that difference. There’s actually an easy way to figure this out, which is to use a random forest!
But in this case we don’t use the random forest to predict our actual dependent variable. Instead, we try to predict whether a row is in the validation set or the training set. To see this in action, let’s combine our training and validation sets together, create a dependent variable that represents which dataset each row comes from, build a random forest using that data, and get its feature importance:
Analysis:
None of the semantic search methods retrieved context from the correct section in the chapter (“Finding Out-of-Domain Data”). I don’t have much intuition or insight into why, but I would think that it has to do with the embeddings of “outliers” being dissimilar to the embeddings of “Out-of-Domain” and “distributed.”
Conclusion:
While this question may not be unanswerable by semantic search in general, the methods I used certainly found it impossible to answer. However, I’m not sure why this is the case.
Tags: unknown failure
Question 15
print_data(14)
Chapter, Question Number: 9 15
Question Text: ""How do we handle categorical variables in a decision tree?""
Answer: ""We convert the categorical variables to integers, where the integers correspond to the discrete levels of the categorical variable. Apart from that, there is nothing special that needs to be done to get it to work with decision trees (unlike neural networks, where we use embedding layers).""
Relevant Context:
Categorify is a TabularProc that replaces a column with a numeric categorical column. FillMissing is a TabularProc that replaces missing values with the median of the column, and creates a new Boolean column that is set to True for any row where the value was missing. These two transforms are needed for nearly every tabular dataset you will use, so this is a good starting point for your data processing:
We can see that the data is still displayed as strings for categories (we only show a few columns here because the full table is too big to fit on a page):
However, the underlying items are all numeric:
The conversion of categorical columns to numbers is done by simply replacing each unique level with a number. The numbers associated with the levels are chosen consecutively as they are seen in a column, so there’s no particular meaning to the numbers in categorical columns after conversion. The exception is if you first convert a column to a Pandas ordered category (as we did for ProductSize earlier), in which case the ordering you chose is used. We can see the mapping by looking at the classes attribute:
Analysis:
The relevant context needed to answer this question contains paragraphs that do not appear consecutively in the chapter and are interweaved with chunks of code. No single sentence (or paragraph) contains the information presented in the gold standard answer tha:
we convert the categorical variables to integers, where the integers correspond to the discrete levels of the categorical variable.
For these reasons, I think semantic search failed to retrieve any paragraph from the correct section (“Using TabularPandas and TabularProc”).
Conclusion:
While this question may not be unanswerable by semantic search in general, the methods I used certainly found it impossible to answer. I attribute this to chunking strategy.
Tags: chunking strategy
Question 18
print_data(15)
Chapter, Question Number: 9 18
Question Text: ""If you increase n_estimators to a very high value, can that lead to overfitting? Why or why not?""
Answer: ""A higher n_estimators mean more decision trees are being used. However, since the trees are independent of each other, using higher n_estimators does not lead to overfitting.""
Relevant Context:
Note that, unlike with random forests, with this approach there is nothing to stop us from overfitting. Using more trees in a random forest does not lead to overfitting, because each tree is independent of the others. But in a boosted ensemble, the more trees you have, the better the training error becomes, and eventually you will see overfitting on the validation set.
One of the most important properties of random forests is that they aren’t very sensitive to the hyperparameter choices, such as max_features. You can set n_estimators to as high a number as you have time to train—the more trees you have, the more accurate the model will be. max_samples can often be left at its default, unless you have over 200,000 data points, in which case setting it to 200,000 will make it train faster with little impact on accuracy. max_features=0.5 and min_samples_leaf=4 both tend to work well, although sklearn’s defaults work well too.
Analysis:
Both paragraphs are needed to answer the question and they are not located next to each other in the chapter. The first paragraph is from the “Boosting” section, and the second paragraph is from the “Creating a Random Forest” section. Four of my semantic search methods retrieved the first paragraph (corresponding to the “does not lead to overfitting” part of the gold standard answer) but none of the methods retrieved the second paragraph which corresponds to the “a higher n_estimators mean more decision trees are being used” part of the answer.
Conclusion:
While this question may not be unanswerable by semantic search in general, the methods I used certainly found it impossible to answer. I’m attributing this error to chunking strategy.
Tags: chunking strategy
Question 23
print_data(16)
Chapter, Question Number: 9 23
Question Text: ""What's the purpose of removing unimportant variables?""
Answer: ""Sometimes, it is better to have a more interpretable model with less features, so removing unimportant variables helps in that regard.""
Relevant Context:
We’ve found that generally the first step to improving a model is simplifying it—78 columns was too many for us to study them all in depth! Furthermore, in practice often a simpler, more interpretable model is easier to roll out and maintain.
It seems likely that we could use just a subset of the columns by removing the variables of low importance and still get good results. Let’s try just keeping those with a feature importance greater than 0.005:
Analysis:
In order to match the content of the gold standard answer, both of these paragraphs are needed.
None of my semantic search methods retrieved these paragraphs. Interesting to note, three of the methods did retrieve the following paragraph from a different section (“Removing Redundant Features”) but the question is about unimportant variables, not redundant ones (though you could argue that redundant variables are unimportant). Regardless, just this one paragraph is not sufficient to match the content in the gold standard answer (it doesn’t mention anything about importance):
One thing that makes this harder to interpret is that there seem to be some variables with very similar meanings: for example, ProductGroup and ProductGroupDesc. Let’s try to remove any redundent features.
Conclusion:
While this question may not be unanswerable by semantic search in general, the methods I used certainly found it impossible to answer. However, I’m not sure why this is the case.
Tags: unknown failure
Chapter 10
Question 7
print_data(17)
Chapter, Question Number: 10 7
Question Text: ""How do the 50,000 unlabeled movie reviews help us create a better text classifier for the IMDb dataset?""
Answer: ""By learning how to predict the next word of a movie review, the model better understands the language style and structure of the text classification dataset and can, therefore, perform better when fine-tuned as a classifier.""
Relevant Context:
One reason, of course, is that it is helpful to understand the foundations of the models that you are using. But there is another very practical reason, which is that you get even better results if you fine-tune the (sequence-based) language model prior to fine-tuning the classification model. For instance, for the IMDb sentiment analysis task, the dataset includes 50,000 additional movie reviews that do not have any positive or negative labels attached. Since there are 25,000 labeled reviews in the training set and 25,000 in the validation set, that makes 100,000 movie reviews altogether. We can use all of these reviews to fine-tune the pretrained language model, which was trained only on Wikipedia articles; this will result in a language model that is particularly good at predicting the next word of a movie review.
Analysis:
This question is asking about a specific paragraph in the chapter which explicitly states the “50,000 additional movie reviews.” None of my semantic search methods retrieved this paragraph.
Conclusion:
While this question may not be unanswerable by semantic search in general, the methods I used certainly found it impossible to answer. My guess for why is that this question requires the keyword “50,000” to be in the answer.
Tags: keyword-based question
Question 8
print_data(18)
Chapter, Question Number: 10 8
Question Text: ""What are the three steps to prepare your data for a language model?""
Answer: ""Tokenization
Numericalization
Language model DataLoader""
Relevant Context:
Each of the steps necessary to create a language model has jargon associated with it from the world of natural language processing, and fastai and PyTorch classes available to help. The steps are:
Tokenization:: Convert the text into a list of words (or characters, or substrings, depending on the granularity of your model) Numericalization:: Make a list of all of the unique words that appear (the vocab), and convert each word into a number, by looking up its index in the vocab
Language model data loader creation:: fastai provides an LMDataLoader class which automatically handles creating a dependent variable that is offset from the independent variable by one token. It also handles some important details, such as how to shuffle the training data in such a way that the dependent and independent variables maintain their structure as required
Language model creation:: We need a special kind of model that does something we haven’t seen before: handles input lists which could be arbitrarily big or small. There are a number of ways to do this; in this chapter we will be using a recurrent neural network (RNN). We will get to the details of these RNNs in the <>, but for now, you can think of it as just another deep neural network.
Analysis:
All of my semantic search methods retrieved the first paragraph introducing the three steps (“Each of the steps necessary…The steps are:” but did not retrieve the very next paragraph which contained information about the three steps.
Conclusion:
I attribute this error to chunking strategy.
Tags: chunking strategy
Question 9
print_data(19)
Chapter, Question Number: 10 9
Question Text: ""What is ""tokenization""? Why do we need it?""
Answer: ""Tokenization is the process of converting text into a list of words. It is not as simple as splitting on the spaces. Therefore, we need a tokenizer that deals with complicated cases like punctuation, hypenated words, etc.""
Relevant Context:
Tokenization:: Convert the text into a list of words (or characters, or substrings, depending on the granularity of your model)
Analysis:
While all of my sementic search methods retrieved context related to tokenization, none of them retrieved the relevant context that defined the term.
Conclusion:
While this question may not be unanswerable by semantic search in general, the methods I used certainly found it impossible to answer. However, I’m not sure why this is the case.
Tags: unknown failure
Question 12
print_data(20)
Chapter, Question Number: 10 12
Question Text: ""List four rules that fastai applies to text during tokenization.""
Answer: ""Here are all the rules:
fix_html :: replace special HTML characters by a readable version (IMDb reviews have quite a few of them for instance) ;
replace_rep :: replace any character repeated three times or more by a special token for repetition (xxrep), the number of times it’s repeated, then the character ;
replace_wrep :: replace any word repeated three times or more by a special token for word repetition (xxwrep), the number of times it’s repeated, then the word ;
spec_add_spaces :: add spaces around / and # ;
rm_useless_spaces :: remove all repetitions of the space character ;
replace_all_caps :: lowercase a word written in all caps and adds a special token for all caps (xxcap) in front of it ;
replace_maj :: lowercase a capitalized word and adds a special token for capitalized (xxmaj) in front of it ;
lowercase :: lowercase all text and adds a special token at the beginning (xxbos) and/or the end (xxeos).""
Relevant Context:
Here is a brief summary of what each does:
fix_html:: Replaces special HTML characters with a readable version (IMDb reviews have quite a few of these)
replace_rep:: Replaces any character repeated three times or more with a special token for repetition (xxrep), the number of times it’s repeated, then the character
replace_wrep:: Replaces any word repeated three times or more with a special token for word repetition (xxwrep), the number of times it’s repeated, then the word
spec_add_spaces:: Adds spaces around / and #
rm_useless_spaces:: Removes all repetitions of the space character
replace_all_caps:: Lowercases a word written in all caps and adds a special token for all caps (xxup) in front of it
replace_maj:: Lowercases a capitalized word and adds a special token for capitalized (xxmaj) in front of it
lowercase:: Lowercases all text and adds a special token at the beginning (xxbos) and/or the end (xxeos)
Analysis:
None of my semantic search methods retrieved the relevant context, although three of them retrieved context related to this topic.
Conclusion:
While this question may not be unanswerable by semantic search in general, the methods I used certainly found it impossible to answer. However, I’m not sure why this is the case.
Tags: unknown failure
Question 13
print_data(21)
Chapter, Question Number: 10 13
Question Text: ""Why are repeated characters replaced with a token showing the number of repetitions and the character that's repeated?""
Answer: ""We can expect that repeated characters could have special or different meaning than just a single character. By replacing them with a special token showing the number of repetitions, the model’s embedding matrix can encode information about general concepts such as repeated characters rather than requiring a separate token for every number of repetitions of every character.""
Relevant Context:
For instance, the rules will replace a sequence of four exclamation points with a special repeated character token, followed by the number four, and then a single exclamation point. In this way, the model’s embedding matrix can encode information about general concepts such as repeated punctuation rather than requiring a separate token for every number of repetitions of every punctuation mark. Similarly, a capitalized word will be replaced with a special capitalization token, followed by the lowercase version of the word. This way, the embedding matrix only needs the lowercase versions of the words, saving compute and memory resources, but can still learn the concept of capitalization.
Analysis:
None of my semantic search methods retrieved the relevant context. Three approaches did get close, as they retrieved the following chunk from the same section in the chapter:
Here is a brief summary of what each does:
fix_html:: Replaces special HTML characters with a readable version (IMDb reviews have quite a few of these)
replace_rep:: Replaces any character repeated three times or more with a special token for repetition (xxrep), the number of times it’s repeated, then the character
replace_wrep:: Replaces any word repeated three times or more with a special token for word repetition (xxwrep), the number of times it’s repeated, then the word
spec_add_spaces:: Adds spaces around / and #
rm_useless_spaces:: Removes all repetitions of the space character
replace_all_caps:: Lowercases a word written in all caps and adds a special token for all caps (xxup) in front of it
replace_maj:: Lowercases a capitalized word and adds a special token for capitalized (xxmaj) in front of it
lowercase:: Lowercases all text and adds a special token at the beginning (xxbos) and/or the end (xxeos)
Conclusion:
While this question may not be unanswerable by semantic search in general, the methods I used certainly found it impossible to answer. However, I’m not sure why this is the case.
Tags: unknown failure
Question 15
print_data(22)
Chapter, Question Number: 10 15
Question Text: ""Why might there be words that are replaced with the ""unknown word"" token?""
Answer: ""If all the words in the dataset have a token associated with them, then the embedding matrix will be very large, increase memory usage, and slow down training. Therefore, only words with more than min_freq occurrence are assigned a token and finally a number, while others are replaced with the “unknown word” token.""
Relevant Context:
Our special rules tokens appear first, and then every word appears once, in frequency order. The defaults to Numericalize are min_freq=3,max_vocab=60000. max_vocab=60000 results in fastai replacing all words other than the most common 60,000 with a special unknown word token, xxunk. This is useful to avoid having an overly large embedding matrix, since that can slow down training and use up too much memory, and can also mean that there isn’t enough data to train useful representations for rare words. However, this last issue is better handled by setting min_freq; the default min_freq=3 means that any word appearing less than three times is replaced with xxunk.
Analysis:
The closest any of the methods got to retrieving the relevant context was by retrieving the following chunk that comes from the same section in the chapter:
Here are some of the main special tokens you’ll see:
xxbos:: Indicates the beginning of a text (here, a review)
xxmaj:: Indicates the next word begins with a capital (since we lowercased everything)
xxunk:: Indicates the word is unknown
Conclusion:
While this question may not be unanswerable by semantic search in general, the methods I used certainly found it impossible to answer. However, I’m not sure why this is the case.
Tags: unknown failure
Question 18
print_data(23)
Chapter, Question Number: 10 18
Question Text: ""What does an embedding matrix for NLP contain? What is its shape?""
Answer: ""It contains vector representations of all tokens in the vocabulary. The embedding matrix has the size (vocab_size x embedding_size), where vocab_size is the length of the vocabulary, and embedding_size is an arbitrary number defining the number of latent factors of the tokens.""
Relevant Context:
Make a list of all possible levels of that categorical variable (we’ll call this list the vocab).
Replace each level with its index in the vocab.
Create an embedding matrix for this containing a row for each level (i.e., for each item of the vocab).
Use this embedding matrix as the first layer of a neural network. (A dedicated embedding matrix can take as inputs the raw vocab indexes created in step 2; this is equivalent to but faster and more efficient than a matrix that takes as input one-hot-encoded vectors representing the indexes.)
Our vocab will consist of a mix of common words that are already in the vocabulary of our pretrained model and new words specific to our corpus (cinematographic terms or actors names, for instance). Our embedding matrix will be built accordingly: for words that are in the vocabulary of our pretrained model, we will take the corresponding row in the embedding matrix of the pretrained model; but for new words we won’t have anything, so we will just initialize the corresponding row with a random vector.
Analysis:
The relevant context from the chapter is sufficient to answer the question in a way that matches the gold standard. Previous knowledge of embeddings (outside of this chapter) is required to know that there is such a thing as embedding_size.
Conclusion:
To be consistent, I’ll remove this question from my evals since it cannot be fully answered by the text in the relevant chapter. That being said, I will be evaluating an LLM on this and other “unanswerable” questions as a capable LLM will likely be able to answer some of them.
Tags: unanswerable
Chapter 13
Question 4
print_data(24)
Chapter, Question Number: 13 4
Question Text: ""What is the value of a convolutional kernel apply to a 3×3 matrix of zeros?""
Answer: ""A zero matrix.""
Relevant Context:
Now we’re going to take the top 3×3-pixel square of our image, and multiply each of those values by each item in our kernel. Then we’ll add them up, like so:
Not very interesting so far—all the pixels in the top-left corner are white. But let’s pick a couple of more interesting spots:
Analysis:
This is a challenging question to answer as it requires context that’s a mix of plain text and code. This relevant context is equal to 4 separate paragraphs which is larger than the chunk size I’m using.
Conclusion:
While this question may not be unanswerable by semantic search in general, the methods I used certainly found it impossible to answer. Perhaps a different chunking strategy would help.
Tags: difficult question, chunking strategy
Question 5
print_data(25)
Chapter, Question Number: 13 5
Question Text: ""What is ""padding""?""
Answer: ""Padding is the additional pixels that are added around the outside of the image, allows the kernel to be applied to the edge of the image for a convolution.""
Relevant Context:
It would be nice to not lose those two pixels on each axis. The way we do that is to add padding, which is simply additional pixels added around the outside of our image. Most commonly, pixels of zeros are added.
Analysis:
All of my semantic search methods retrieved context from the section titled “Strides and Padding” instead of the section where the definition was found, “Convolutions in PyTorch”.
Conclusion:
Including the header in the chunk text might have distracted semantic search from the retrieving relevant context.
Tags: chunking strategy
Question 20
print_data(26)
Chapter, Question Number: 13 20
Question Text: ""How is a color image represented as a tensor?""
Answer: ""It is a rank-3 tensor of shape (3, height, width)""
Relevant Context:
One batch contains 64 images, each of 1 channel, with 28×28 pixels. F.conv2d can handle multichannel (i.e., color) images too. A channel is a single basic color in an image—for regular full-color images there are three channels, red, green, and blue. PyTorch represents an image as a rank-3 tensor, with dimensions [channels, rows, columns].
Analysis:
All of my semantic search methods retrieved irrelevant context from the section titled “Color Image” but not from the section containing the relevant context, “Convolutions in PyTorch”.
Conclusion:
Including the header in the chunk text might have distracted semantic search from the retrieving relevant context.
Tags: chunking strategy
Question 22
print_data(27)
Chapter, Question Number: 13 22
Question Text: ""What method can we use to see that data in DataLoaders?""
Answer: ""show_batch""
Relevant Context:
Remember, it’s always a good idea to look at your data before you use it:
dls.show_batch(max_n=9, figsize=(4,4))
Analysis:
The relevant context shown was the only occurence of show_batch in the chapter and all of my semantic search methods failed to retrieve it.
Conclusion:
While this question may not be unanswerable by semantic search in general, the methods I used certainly found it impossible to answer. I attribute this error to this question requiring the keyword “show_batch” in the answer.
Tags: keyword-based question
Question 24
print_data(28)
Chapter, Question Number: 13 24
Question Text: ""Why do we use a larger kernel in the first conv with MNIST (with simple_cnn)?""
Answer: ""With the first layer, if the kernel size is 3x3, with four output filters, then nine pixels are being used to produce 8 output numbers so there is not much learning since input and output size are almost the same. Neural networks will only create useful features if they’re forced to do so—that is, if the number of outputs from an operation is significantly smaller than the number of inputs. To fix this, we can use a larger kernel in the first layer.""
Relevant Context:
As we discussed, we generally want to double the number of filters each time we have a stride-2 layer. One way to increase the number of filters throughout our network is to double the number of activations in the first layer–then every layer after that will end up twice as big as in the previous version as well.
But there is a subtle problem with this. Consider the kernel that is being applied to each pixel. By default, we use a 3×3-pixel kernel. That means that there are a total of 3×3 = 9 pixels that the kernel is being applied to at each location. Previously, our first layer had four output filters. That meant that there were four values being computed from nine pixels at each location. Think about what happens if we double this output to eight filters. Then when we apply our kernel we will be using nine pixels to calculate eight numbers. That means it isn’t really learning much at all: the output size is almost the same as the input size. Neural networks will only create useful features if they’re forced to do so—that is, if the number of outputs from an operation is significantly smaller than the number of inputs.
To fix this, we can use a larger kernel in the first layer. If we use a kernel of 5×5 pixels then there are 25 pixels being used at each kernel application. Creating eight filters from this will mean the neural net will have to find some useful features:
Analysis:
This is a complex topic and the relevant context needed to answer this question is relatively large. To match the gold standard answer, the three paragraphs must be summarized as the answer is not explicitly or simply stated.
Conclusion:
While this question may not be unanswerable by semantic search in general, the methods I used certainly found it impossible to answer.
Tags: difficult question
Final Thoughts
Here is a summary of tags across the 29 questions where the Answer Rate for all of my semantic search methods was 0% (i.e. none of the methods retrieved the context needed to answer the question):
Tag
Count
unknown failure
12
chunking strategy
9
keyword-based question
4
difficult question
2
unanswerable
2
requires image
1
The most common error was due to unknown failure (12) where I didn’t have a guess for why semantic search failed. I attribute this to my lack of experience using embeddings.
The next most common error type was chunking strategy (9). These were situations where the relevant context needed to match the gold standard answer was longer than 3 paragraphs or spread out across multiple sections in the chapter.
There were 4 keyword-based questions where the question and relevant context contained a specific keyword (like show_batch or “50,000”). I felt these were better suited for a keyword-based search.
The relevant context for the 2 difficult questions did not explicitly state/paraphrase the gold standard answer and required inferring/summarization. With the right prompting, a capable LLM could handle this correctly.
The 2 unanswerable questions were those where the corresponding chapter text did not contain the answer, and required external knowledge (including other chapters of the book).
Finally, 1 question required an image to achieve the gold standard answer.
I’m curious to see for which of these questions keyword-based search yielded better results (and vice versa). I’ll be analyzing that next.
Here is a summary of how many 0% Answer Rate questions there are for each chapter. Semantic search struggled considerably in retrieving relevant context for Chapter 9 and 10 questions.