Training Textual Inversion Embeddings on Some Samurai Jack Drawings
Background
In Lesson 9 of the fastai course (Part 2) we are introduced to the concept of textual inversion, where you train an embedding on a new set of images the model hasn’t seen before, and then use that embedding during inference to have the model adapt its style (or object) in the generated image. To get some experience with training and inference, I decided to train a textual inversion embeddings on six pencil/pen drawings I made of one of my favorite childhood cartoons: Samurai Jack.
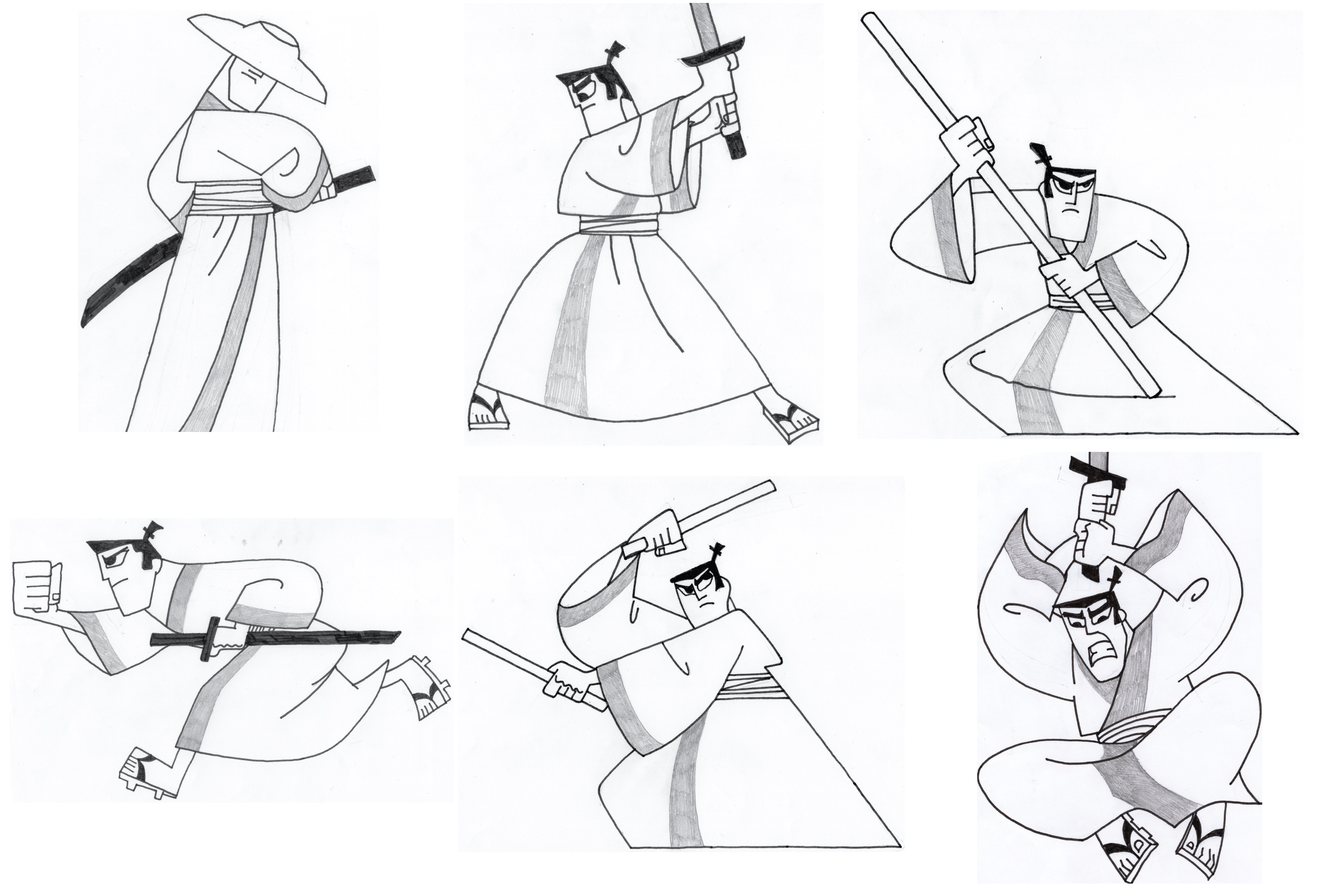
I have uploaded the trained embeddings to Huggingface: sd-concepts-library/samurai-jack. I have created this minimal Colab demo for inference.
Version 1: Initial Training
I used the Huggingface-provided notebook to train my textual inversion embeddings.
I used the default hyperparameters for the first version of the embeddings I trained, which took about 45 minutes to train with a Free-A4000 on Paperspace:
hyperparameters = {
"learning_rate": 5e-04,
"scale_lr": True,
"max_train_steps": 2000,
"save_steps": 250,
"train_batch_size": 2,
"gradient_accumulation_steps": 1,
"gradient_checkpointing": True,
"mixed_precision": "fp16",
"seed": 42,
"output_dir": "sd-concept-output"
}Here are some images I generated using the trained embeddings with the prompts displayed in the caption:
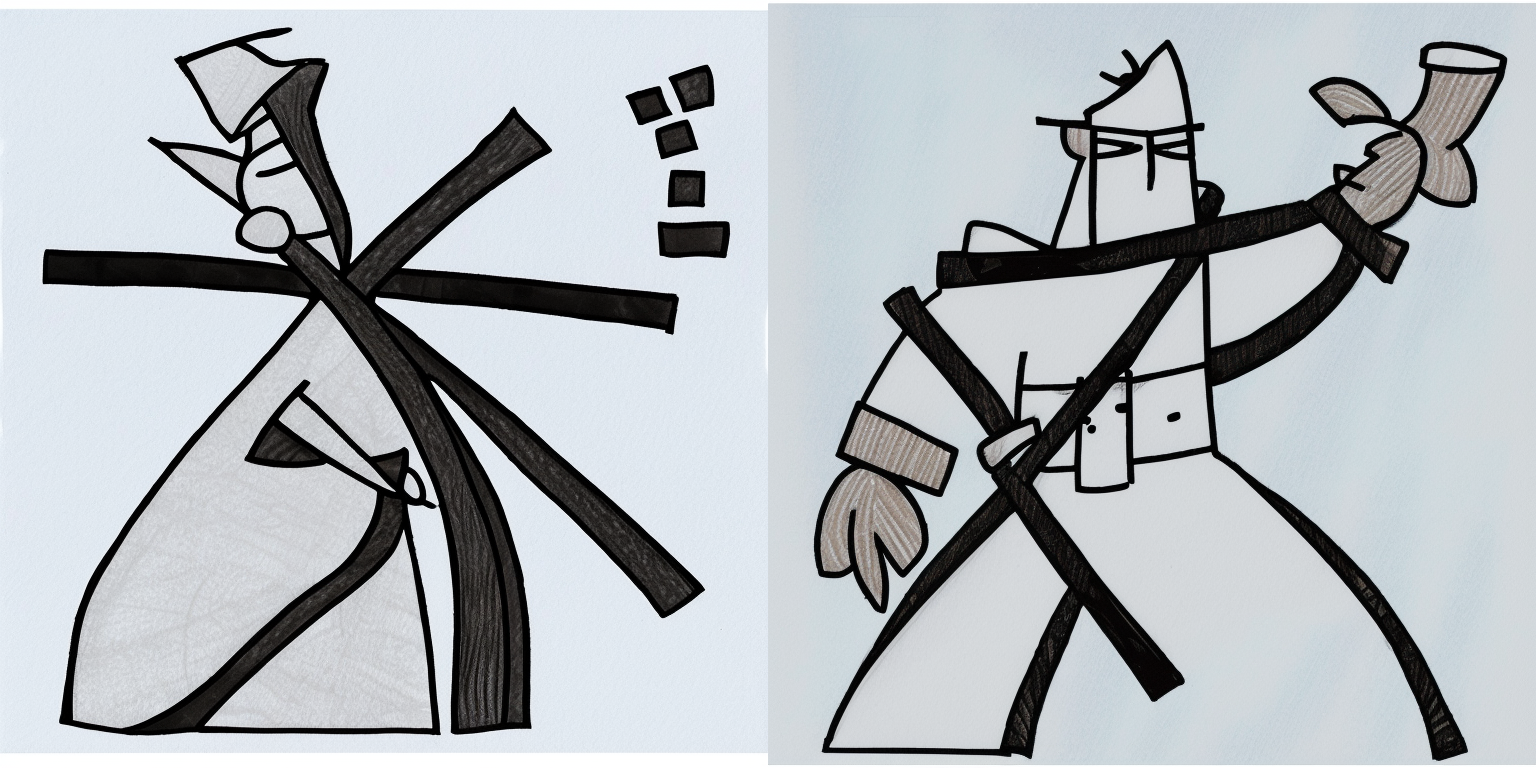
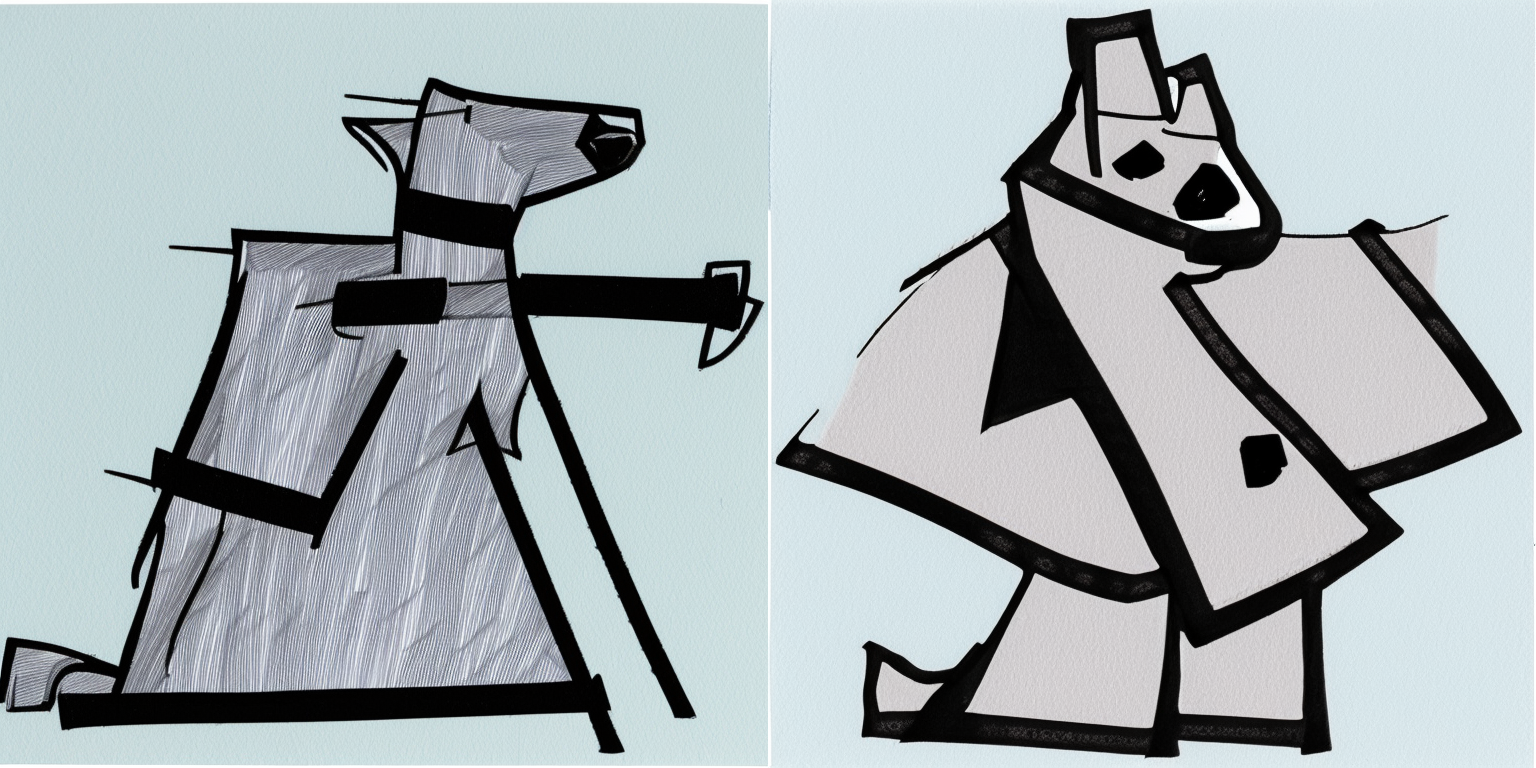
30 Inference Steps
The prompt corresponding to the image is listed below it.





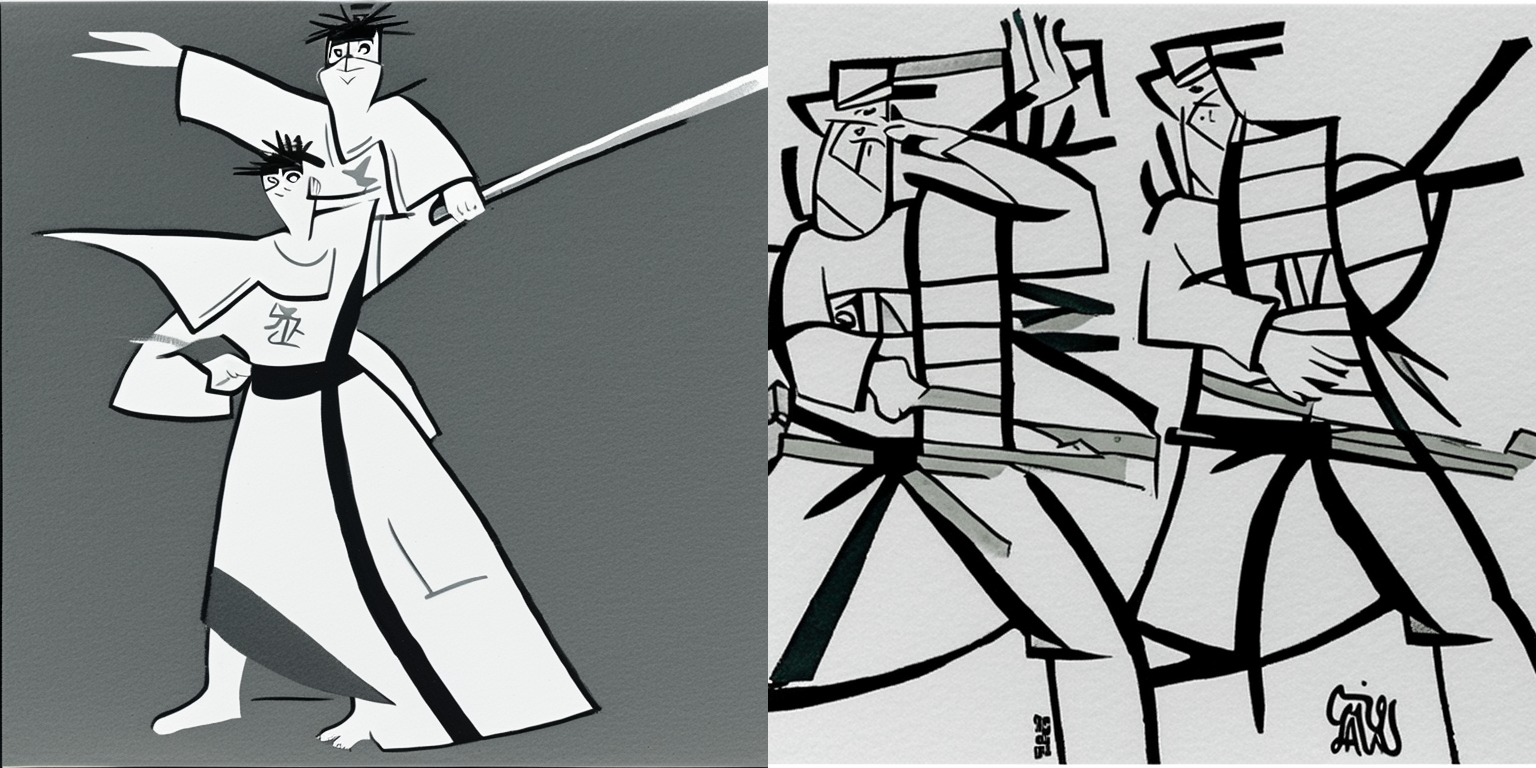

50 Inference Steps
The prompt corresponding to the image is listed below it.







Reflecting on Version 1
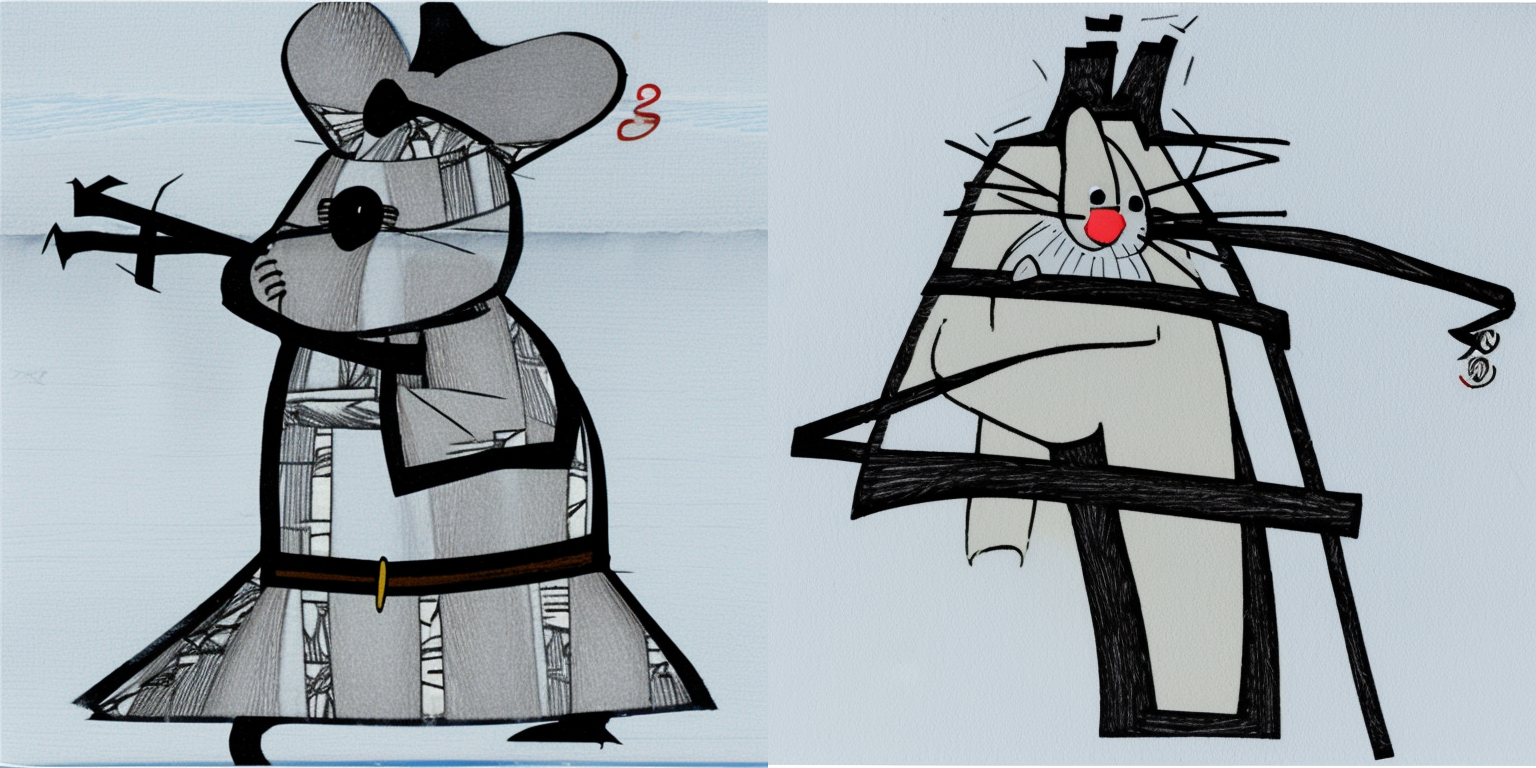
The trained embeddings (with the associated token \<samurai-jack\>) have clearly learned features related to my original drawings. The generated images have similar clothing and weapons. However, at both 30 and 50 inference steps, the style of the generated images doesn’t really resemble the style I drew the source drawings with (pencil/pen sketch). Additionally, the generated images have color, whereas my drawings were grayscale. I do like the generated images for the cat and mouse prompts. Finally, there’s something stereotypical about the generated images which bothers me—it’s almost like the model has detected that the trained embeddings represent japanese art and it has drawn upon whatever training data aligns with that.
Version 2: Longer Training
I provided my code and 5 generated images to Claude, asking it for feedback on what hyperparameters I could try to improve my embeddings. It suggested to increase the number of training steps, batch size and gradient accumulation steps, and lower the learning rate to yield a training that learned more details from my input images. While I couldn’t increase the batch size without getting an OOM error, I applied the rest of its suggestions in my training script:
hyperparameters = {
"learning_rate": 1e-04,
"scale_lr": True,
"max_train_steps": 4000,
"save_steps": 2000,
"train_batch_size": 2,
"gradient_accumulation_steps": 4,
"gradient_checkpointing": True,
"mixed_precision": "fp16",
"seed": 42,
"output_dir": "sd-concept-output-2"
}The resulting training took about 6 hours to run (with seconds to spare before Paperspace’s auto-shutdown!).
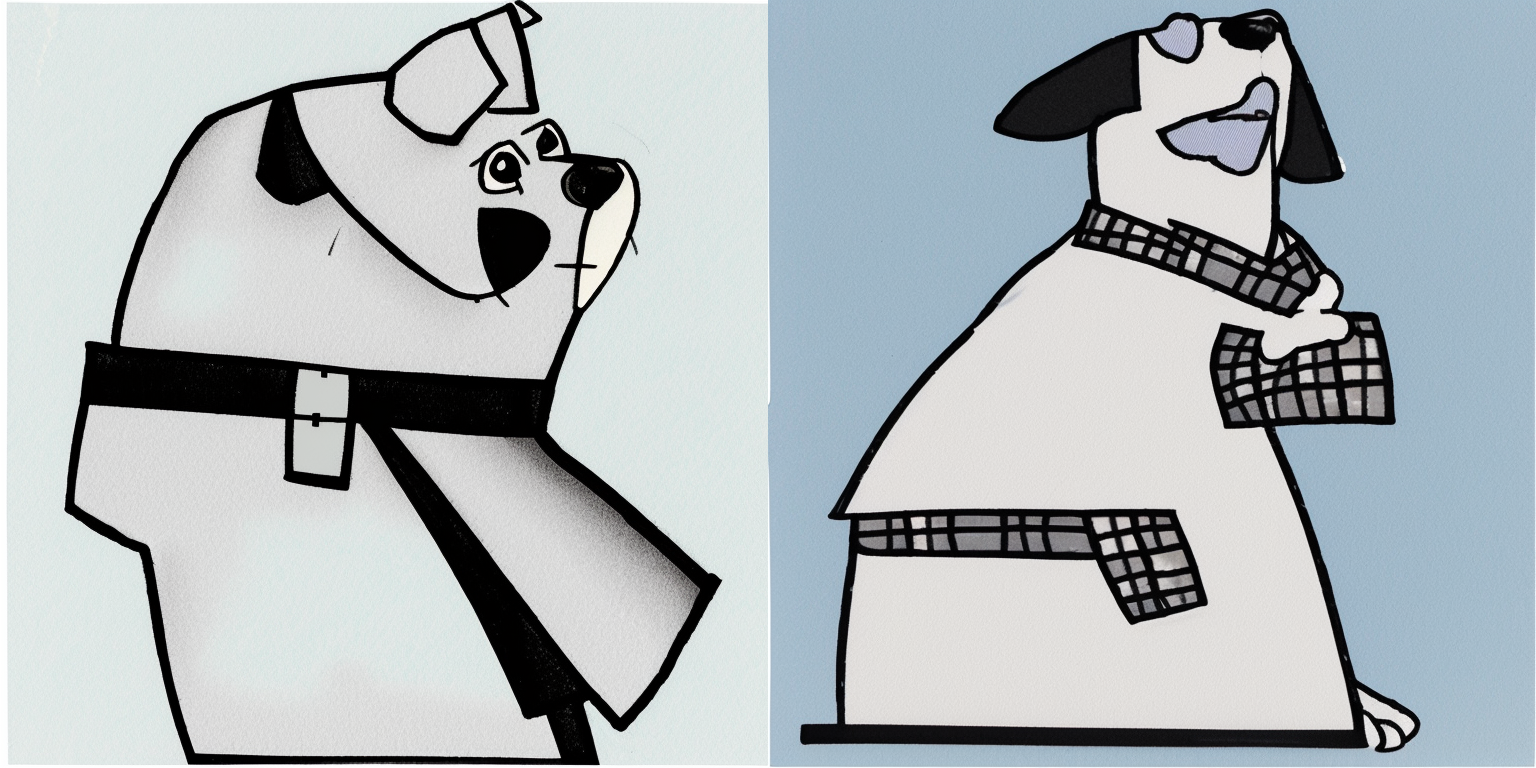
Here are some images I generated using the trained embeddings with the prompts displayed in the caption. Note that I only used 50 inference steps as I like the resulting generations more than the 30-step ones.
50 Inference Steps
The prompt corresponding to the image is listed below it.

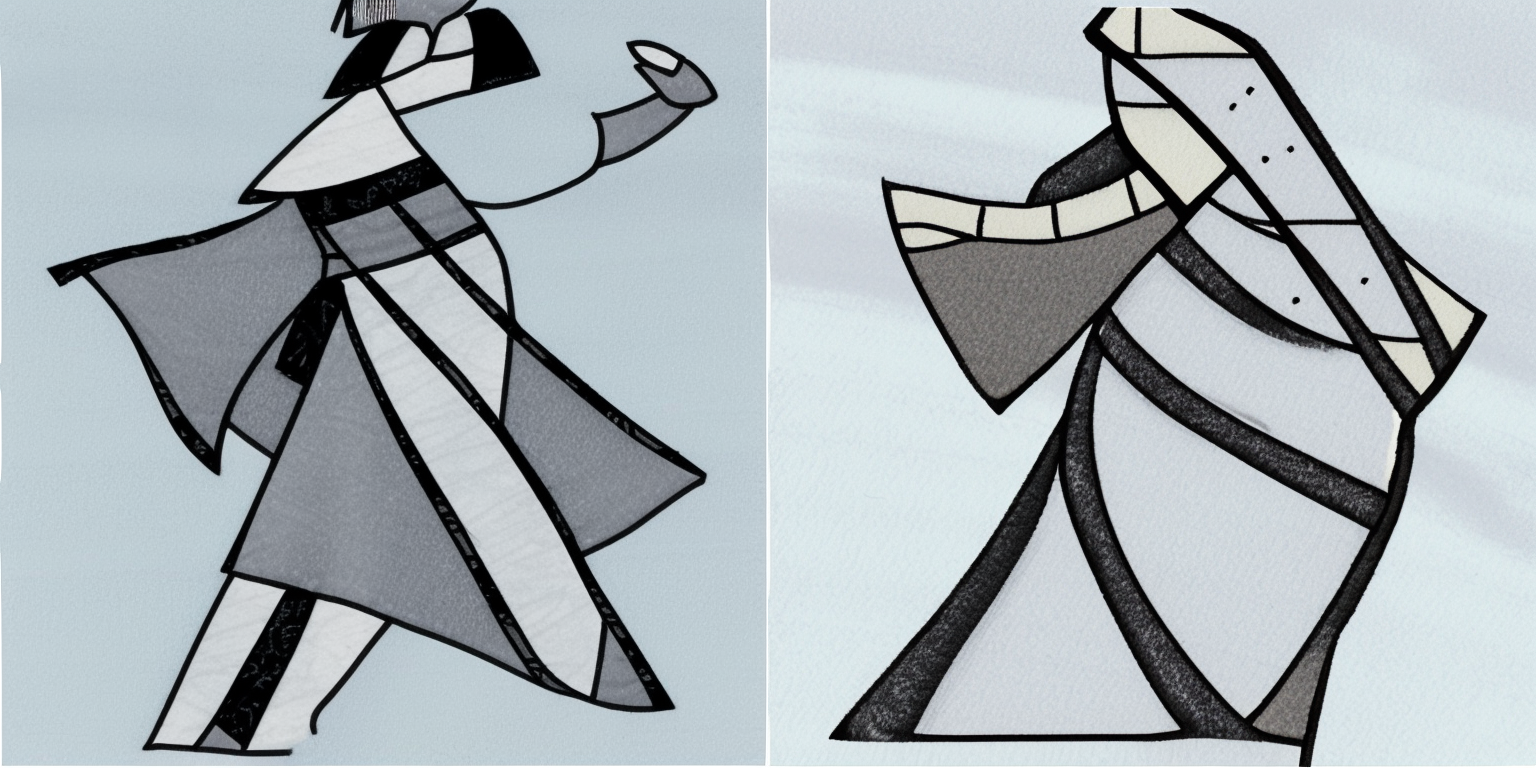
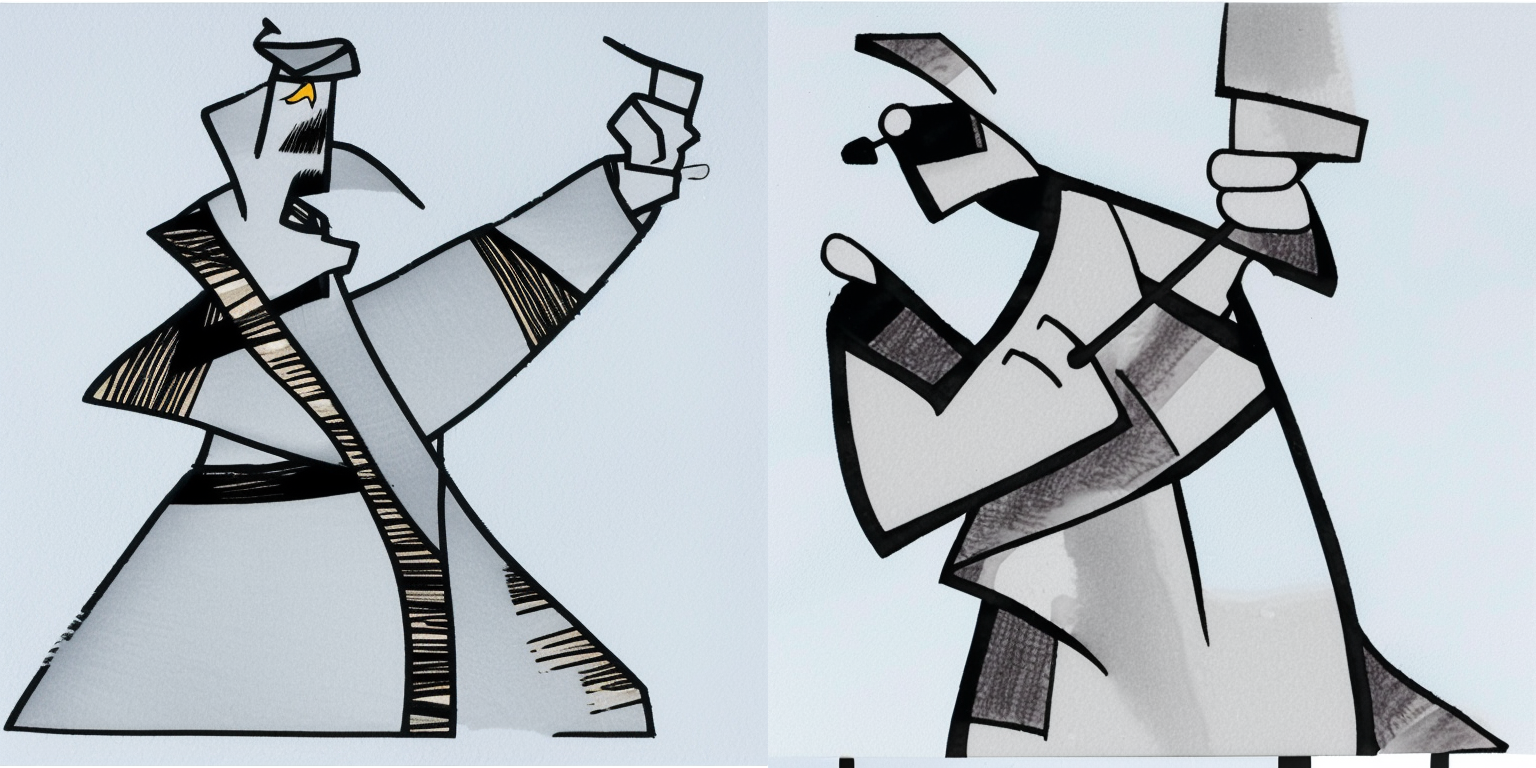


Reflecting on Version 2
While the image generations using this embeddings are more abstract, I find them better quality and more similar to the original style of my drawings. The following prompts generated more pencil/pen-sketch styled generations:
- “a man in the style of <samurai-jack>”
- “a woman in the style of <samurai-jack>”
- “a person in the style of <samurai-jack>”
- “in the style of <samurai-jack>”
While the generated image for the prompt "\<samurai-jack\>" looks nothing like my original drawings, I do find them very beautiful.
There were still some “stereotypical” features in some of the generated outputs. For example, the following images contained a red spot (I’m not an art historian but I recall seeing similar red spots/marks/seals in japanese paintings)

These red spots were more abstract in some of the generations:
Additionally, some of the generations contained unsolicited language-like characters:


Final Thoughts
There is much I haven’t explored in this experiment, for example, using my input drawings to train an “object” to see how that fares during inference, and of course, trying different hyperparameters. That being said, I’m happy that what I attempted at least worked! I found many of the generated images pleasant to look at, as the pencil+pen-sketch style was captured quite well by my version 2 embedddings.
I’ll end this post with some of the other prompt/generation pairs that I found interesting/beautiful. The prompt corresponding to the image is listed below it: