Show pip installs
!pip install transformers -Uqq
!pip install accelerate -qq
!pip install torch==2.2.2 -qq
!pip install datasets~=2.16.1 -qq
!pip install scikit-learn==1.2 -qqfinancial_phrasebank dataset with 79.5% accuracy.
pip installs!pip install transformers -Uqq
!pip install accelerate -qq
!pip install torch==2.2.2 -qq
!pip install datasets~=2.16.1 -qq
!pip install scikit-learn==1.2 -qqfrom datasets import load_dataset, Dataset
import pandas as pd, numpy as np
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
from pandas.api.types import CategoricalDtype
import random
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2-0.5B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")# load dataset
dataset = load_dataset(
"financial_phrasebank", "sentences_allagree",
split="train" # note that the dataset does not have a default test split
)
# create a new column with the numeric label verbalised as label_text (e.g. "positive" instead of "0")
label_map = {i: label_text for i, label_text in enumerate(dataset.features["label"].names)}
def add_label_text(example):
example["label_text"] = label_map[example["label"]]
return example
dataset = dataset.map(add_label_text)
print(dataset)generate_response functiondef generate_response(prompt):
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=2
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return responseadd_prompt and generate_responses functionsdef add_prompt(item, prompt):
item['prompt'] = prompt.format(text=item['sentence'])
return item
def generate_responses(dataset, prompt):
responses = []
dataset = dataset.map(add_prompt, fn_kwargs={"prompt": prompt})
print(dataset[0]['prompt'])
for row in dataset:
messages = [
{"role": "user", "content": row['prompt']}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=2
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0].strip().lower()
responses.append(response)
# calculate accuracy
df = dataset.to_pandas()
df['responses'] = pd.Series(responses)
#df['responses'] = df['responses'].apply(lambda x: x if x in ['negative', 'positive', 'neutral'] else "other")
df['lm_match'] = df['label_text'] == df['responses']
acc = df.lm_match.mean()
return df, accmake_cm functiondef make_cm(df):
"""Create confusion matrix for true vs predicted sentiment classes"""
cm = confusion_matrix(y_true=df['label_text'], y_pred=df['responses'], labels=['negative', 'neutral', 'positive', 'other'])
disp = ConfusionMatrixDisplay(cm, display_labels=['negative', 'neutral', 'positive', 'other'])
# I chose 8x8 so it fits on one screen but still is large
fig, ax = plt.subplots(figsize=(8,8))
disp.plot(ax=ax,text_kw={'fontsize': 16}, cmap='Blues', colorbar=False);
# change label font size without changing label text
ax.xaxis.label.set_fontsize(18)
ax.yaxis.label.set_fontsize(18)
# make tick labels larger
ax.tick_params(axis='y', labelsize=16)
ax.tick_params(axis='x', labelsize=16)ds_subset functiondef ds_subset(dataset, exclude_idxs, columns=[0, 1, 2]):
idxs = list(range(len(dataset)))
idxs = [x for x in idxs if x not in exclude_idxs]
ddf = dataset.to_pandas()
new_ds = Dataset.from_pandas(ddf.iloc[idxs, columns])
return new_dsfew_shot_responsesfunctiondef few_shot_responses(dataset, prompt, examples):
responses = []
dataset = dataset.map(add_prompt, fn_kwargs={"prompt": prompt})
print(dataset[0]['prompt'])
few_shot_examples = []
for example in examples:
few_shot_examples.append({"role": "user", "content": prompt.format(text=example[0])})
few_shot_examples.append({"role": "assistant", "content": example[1]})
for row in dataset:
messages = few_shot_examples + [{"role": "user", "content": row['prompt']}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=2
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0].strip().lower()
responses.append(response)
df = dataset.to_pandas()
df['responses'] = pd.Series(responses)
return dfget_acc functiondef get_acc(df):
df['responses'] = df['responses'].apply(lambda x: x if x in ['negative', 'positive', 'neutral'] else "other")
df['lm_match'] = df['label_text'] == df['responses']
acc = df.lm_match.mean()
return accget_ds functiondef get_ds(n):
exclude_idxs = [random.randint(0, 2263) for _ in range(n)]
prompt_ds = ds_subset(dataset, exclude_idxs=exclude_idxs)
examples = []
for idx in exclude_idxs:
examples.append((dataset[idx]['sentence'], dataset[idx]['label_text']))
print(prompt_ds, [el[1] for el in examples[:10]])
return prompt_ds, examplesIn this notebook I’ll use Qwen2-0.5B-Instruct to classify sentiment in the financial_phrasebank dataset. In previous notebooks I have performed sentiment classification with Qwen2-1.5B-Instruct, phi-2, phi-3, phi-3.5, and the Claude series.
This notebook is part of a series of blog posts for a project I’m working called TinySentiment where I’m experimenting with tiny models to improve their ability to classify sentiment in the financial_phrasebank dataset. I was inspired to do so after reading this blog post and this corresponding notebook by Moritz Laurer as part of a fastai study group last year.
Here are the results from my experiments so far (**the best-performing prompt from this notebook):
| Model | Prompting Strategy | Overall Accuracy | negative |
neutral |
positive |
|---|---|---|---|---|---|
| claude-3-5-sonnet-20240620 | 3-Shot | 94.78% | 98% (297/303) | 94% (1302/1391) | 95% (544/570) |
| claude-3-opus-20240229 | 0-Shot | 94.13% | 98% (297/303) | 96% (1333/1391) | 88% (501/570) |
| phi-3.5 | 20-Shot | 93.94% | 96% (286/299) | 98% (1355/1379) | 83% (467/566) |
| phi-3 | 30-Shot w/System Prompt | 92.79% | 98% (290/297) | 94% (1284/1373) | 88% (499/564) |
| claude-3-haiku-20240307 | 3-Shot | 92.39% | 90% (272/303) | 91% (1267/1391) | 96% (550/570) |
| phi-2 | 6-Shot | 91.94% | 88% (267/302) | 94% (1299/1387) | 90% (510/569) |
| Qwen2-1.5B | 27-Shot | 86.10% | 90% (264/294) | 96% (1320/1382) | 61% (342/561) |
| **Qwen2-0.5B | 17-Shot | 79.48% | 69% (206/300) | 86% (1180/1380) | 71% (400/567) |
Here are the results from this notebook:
| Prompt | Strategy | Accuracy | Negative | Neutral | Positive |
|---|---|---|---|---|---|
| A | 0-Shot | 62.41% | 91% (276/303) | 53% (735/1391) | 71% (402/570) |
| B | 0-Shot | 47.84% | 90% (274/303) | 57% (789/1391) | 4% (20/570) |
| C | 0-Shot | 40.46% | 91% (276/303) | 43% (594/1391) | 8% (46/570) |
| D | 0-Shot | 68.29% | 79% (240/303) | 61% (851/1391) | 80% (455/570) |
| E | 0-Shot | 51.19% | 97% (293/303) | 28% (396/1391) | 82% (470/570) |
| F | 0-Shot | 48.19% | 94% (286/303) | 21% (287/1391) | 91% (518/570) |
| G | 0-Shot | 61.09% | 93% (282/303) | 46% (646/1391) | 80% (455/570) |
| H | 0-Shot | 65.42% | 85% (257/303) | 57% (798/1391) | 75% (426/570) |
| I | 0-Shot | 66.12% | 81% (245/303) | 58% (800/1391) | 79% (452/570) |
| J | 3-Shot | 70.94% | 43% (131/302) | 75% (1042/1390) | 76% (431/569) |
| K | 3-Shot | 74.88% | 67% (201/302) | 75% (1043/1390) | 79% (449/569) |
| L | 3-Shot | 68.11% | 49% (149/302) | 65% (900/1390) | 86% (491/569) |
| M | 3-Shot | 56.97% | 49% (149/302) | 45% (625/1390) | 90% (514/569) |
| N | 3-Shot | 73.95% | 62% (188/302) | 75% (1038/1390) | 78% (446/569) |
| O | 3-Shot | 59.97% | 65% (196/302) | 46% (635/1390) | 92% (525/569) |
| P | 6-Shot | 63.91% | 95% (289/303) | 49% (678/1389) | 84% (476/566) |
| Q | 6-Shot | 65.72% | 69% (207/302) | 55% (765/1389) | 90% (512/567) |
| R | 6-Shot | 64.84% | 94% (285/303) | 49% (686/1387) | 87% (493/568) |
| S | 6-Shot | 62.98% | 96% (292/303) | 47% (656/1387) | 83% (474/568) |
| T | 6-Shot | 68.87% | 51% (155/302) | 70% (966/1387) | 76% (434/569) |
| U | 12-Shot | 65.50% | 53% (159/302) | 59% (820/1386) | 88% (496/564) |
| V | 12-Shot | 73.22% | 70% (209/300) | 80% (1103/1386) | 60% (337/566) |
| W | 12-Shot | 70.43% | 82% (246/301) | 66% (912/1384) | 75% (428/567) |
| X | 12-Shot | 76.60% | 91% (270/298) | 72% (1000/1386) | 80% (455/568) |
| Y | 12-Shot | 72.56% | 80% (243/303) | 77% (1069/1381) | 57% (322/568) |
| Z | 18-Shot | 71.33% | 50% (150/301) | 75% (1036/1382) | 74% (416/563) |
| AA | 17-Shot | 79.48% | 69% (206/300) | 86% (1180/1380) | 71% (400/567) |
| AB | 18-Shot | 74.22% | 77% (229/299) | 76% (1054/1381) | 68% (384/566) |
| AC | 18-Shot | 68.57% | 49% (148/302) | 73% (1013/1380) | 67% (379/564) |
| AD | 18-Shot | 74.98% | 89% (271/303) | 76% (1052/1379) | 64% (361/564) |
| AE | 24-Shot | 74.91% | 61% (181/299) | 92% (1267/1375) | 41% (230/566) |
| AF | 24-Shot | 73.08% | 37% (112/302) | 91% (1246/1375) | 50% (279/563) |
| AG | 24-Shot | 75.00% | 58% (173/300) | 92% (1265/1375) | 43% (242/565) |
| AH | 24-Shot | 77.46% | 78% (233/299) | 84% (1153/1375) | 62% (349/566) |
| AI | 23-Shot | 75.37% | 48% (143/301) | 92% (1266/1375) | 50% (280/565) |
| AJ | 30-Shot | 77.39% | 58% (172/298) | 94% (1284/1370) | 48% (273/566) |
| AK | 30-Shot | 67.78% | 63% (187/299) | 61% (844/1375) | 86% (483/560) |
| AL | 30-Shot | 76.54% | 58% (173/299) | 86% (1185/1372) | 63% (352/563) |
| AM | 30-Shot | 74.84% | 82% (242/296) | 72% (984/1376) | 79% (446/562) |
| AN | 30-Shot | 73.81% | 51% (154/300) | 77% (1052/1372) | 79% (443/562) |
| AO | 45-Shot | 74.18% | 54% (159/297) | 76% (1034/1366) | 81% (453/556) |
| AP | 45-Shot | 78.73% | 63% (186/296) | 87% (1192/1365) | 66% (369/558) |
| AQ | 45-Shot | 72.01% | 17% (51/301) | 89% (1210/1359) | 60% (337/559) |
| AR | 45-Shot | 73.86% | 53% (157/297) | 80% (1094/1364) | 70% (388/558) |
| AS | 45-Shot | 74.94% | 42% (125/297) | 89% (1219/1363) | 57% (319/559) |
| AT | 60-Shot | 72.19% | 47% (138/292) | 78% (1055/1356) | 72% (398/556) |
| AU | 60-Shot | 76.86% | 43% (127/296) | 91% (1237/1356) | 60% (330/552) |
| AV | 60-Shot | 75.45% | 26% (79/299) | 89% (1206/1352) | 68% (378/553) |
| AW | 60-Shot | 74.46% | 29% (88/299) | 86% (1157/1349) | 71% (396/556) |
| AX | 60-Shot | 79.63% | 62% (179/290) | 94% (1275/1352) | 54% (301/562) |
I’ll start out with a simple instruction.
promptA = """Label the following TEXT with a single word: negative, positive, or neutral
TEXT: {text}"""
print(promptA)Label the following TEXT with a single word: negative, positive, or neutral
TEXT: {text}formatted_prompt = promptA.format(text=dataset[0]['sentence'])
print(formatted_prompt)Label the following TEXT with a single word: negative, positive, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .generate_response(formatted_prompt)The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Starting from v4.46, the `logits` model output will have the same type as the model (except at train time, where it will always be FP32)'Negative.'Good—at least it’s responding with a sensible answer, although it’s not formatted how I’d like to be, so I expect to need more data cleaning than Qwen2-1.5B-Instruct’s responses.
At ~35ms per prompt it will take about 80 seconds to run inference on the full 2264 item dataset.
%timeit -n 10 generate_response(formatted_prompt)35.4 ms ± 472 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)df, acc = generate_responses(dataset, promptA)Label the following TEXT with a single word: negative, positive, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Starting from v4.46, the `logits` model output will have the same type as the model (except at train time, where it will always be FP32)0.5B yields messier responses. Note the period at the end of some of the strings. For now I’ll manually check each set of responses and clean them accordingly.
df['responses'].unique()array(['neutral.', 'positive', 'neutral', 'negative', 'positive.',
'negative.', 'negot', 'negative profit', 'net interest', 'teleste',
'neglig'], dtype=object)df['responses'] = df['responses'].str.replace('.', '', regex=False) df['responses'] = df['responses'].apply(lambda x: x if x in ['negative', 'positive', 'neutral'] else "other")0.5B doesn’t do terribly on this simple prompt (62.4% accuracy) but it’s almost 20% less accurate than 1.5B (~82% accuracy).
df['lm_match'] = df['label_text'] == df['responses']
acc = df.lm_match.mean()
acc0.62411660777385160.5B does a great job at classifying negative sentiment, does quite well at positive sentences, and has very few other responses overall.
make_cm(df)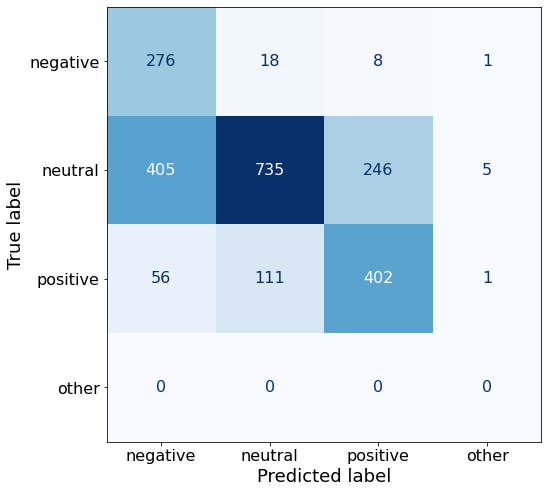
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_A.csv', index=False)promptB = """Instruct: label the following TEXT with a single word: negative, positive, or neutral
TEXT: {text}
label the TEXT with a single word: negative, positive, or neutral"""df, acc = generate_responses(dataset, promptB)Instruct: label the following TEXT with a single word: negative, positive, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .
label the TEXT with a single word: negative, positive, or neutralWith this prompt (where the instruction is repeated after the dataset text) 0.5B responds much more cleanly.
df['responses'].unique()array(['negative', 'neutral', 'positive'], dtype=object)However, it performs almost 20% worse!
df['lm_match'] = df['label_text'] == df['responses']
acc = df.lm_match.mean()
acc0.47835689045936397While it’s quite good still with negative sentiment, it performs significantly worse on positive sentences.
make_cm(df)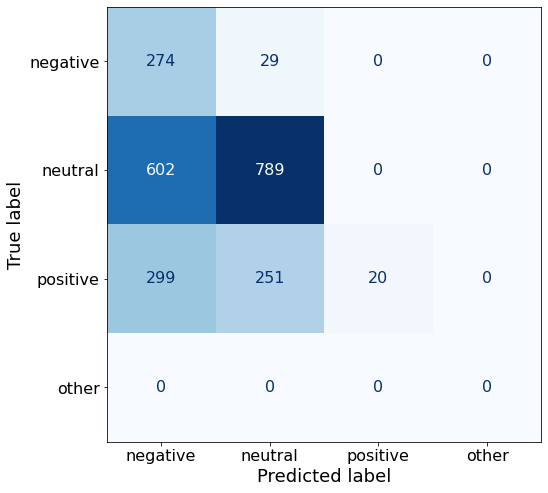
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_B.csv', index=False)I’ll use the same Prompt C as the 1.5B model: a reword of Prompt A (which performed well for 0.5B).
promptC = """Respond with a single word: negative, positive, or neutral
TEXT: {text}"""df, acc = generate_responses(dataset, promptC)Respond with a single word: negative, positive, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['negative.', 'negative', 'neutral', 'neutral.', 'positive',
'positive.', 'negative loss'], dtype=object)The change in prompt language significantly deteriorates 0.5B’s accuracy.
df['responses'] = df['responses'].str.replace('.', '', regex=False)
df['responses'] = df['responses'].apply(lambda x: x if x in ['negative', 'positive', 'neutral'] else "other")
df['lm_match'] = df['label_text'] == df['responses']
acc = df.lm_match.mean()
acc0.40459363957597170.5B still does really well on negative sentiment, but does horribly on positive and underwhelming for neutral sentences.
make_cm(df)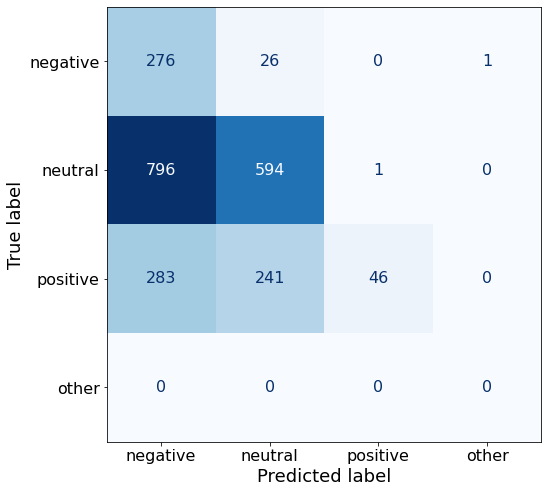
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_C.csv', index=False)I’ll change the order of sentiment listed in Prompt A by putting positive first:
promptD = """Label the following TEXT with a single word: positive, negative, or neutral
TEXT: {text}"""df, acc = generate_responses(dataset, promptD)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral.', 'positive', 'positive.', 'neutral', 'net income',
'the text', 'negative', 'negative.', 'negative net', 'negot',
'subscription'], dtype=object)Changing the order of sentiment (putting positive first) increases the overall accuracy by ~6%.
df['responses'] = df['responses'].str.replace('.', '', regex=False)
df['responses'] = df['responses'].apply(lambda x: x if x in ['negative', 'positive', 'neutral'] else "other")
df['lm_match'] = df['label_text'] == df['responses']
acc = df.lm_match.mean()
acc0.68286219081272080.5B’s performance on negative sentiment dips a bit (36 fewer correct) but that is more than compensated by the increase in correctly classified positive (+53) and neutral (+166) sentences.
make_cm(df)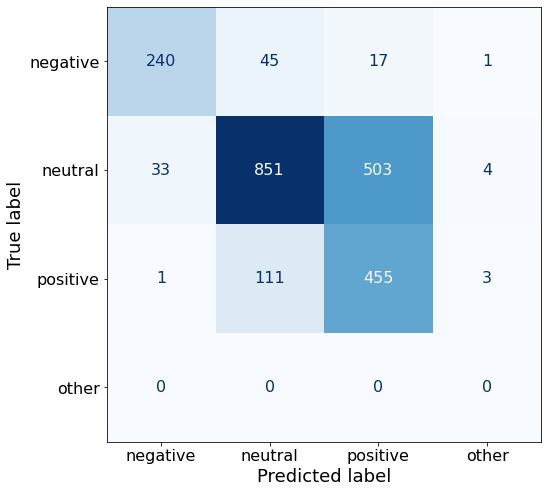
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_D.csv', index=False)I’ll try another combination:
promptE = """Label the following TEXT with a single word: negative, neutral, or positive
TEXT: {text}"""df, acc = generate_responses(dataset, promptE)Label the following TEXT with a single word: negative, neutral, or positive
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['negative.', 'positive', 'negative', 'positive.', 'neutral.',
'neutral', 'negative profit', 'negot', 'teleste'], dtype=object)This ordering of sentiment worsens the accuracy by 10 points.
df['responses'] = df['responses'].str.replace('.', '', regex=False)
df['responses'] = df['responses'].apply(lambda x: x if x in ['negative', 'positive', 'neutral'] else "other")
df['lm_match'] = df['label_text'] == df['responses']
acc = df.lm_match.mean()
acc0.51192579505300350.5B is nearly perfect for negative sentiment, and quite good with positive sentences, but abysmal for neutral.
make_cm(df)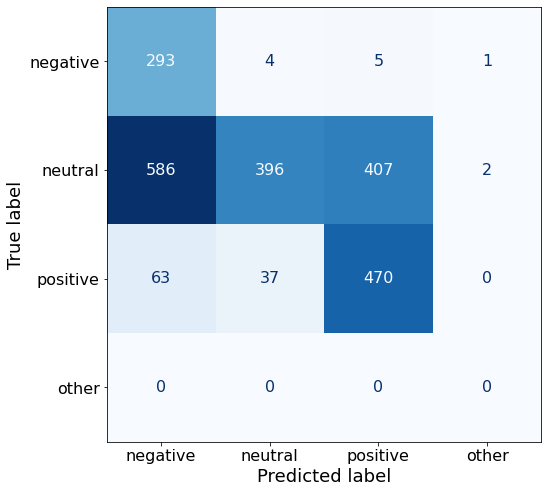
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_E.csv', index=False)Trying the next permutation of sentiments:
promptF = """Label the following TEXT with a single word: positive, neutral, or negative
TEXT: {text}"""df, acc = generate_responses(dataset, promptF)Label the following TEXT with a single word: positive, neutral, or negative
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral.', 'positive', 'positive.', 'negative', 'negative.',
'neutral', 'positive net', 'negativ', 'negot', 'subscription'],
dtype=object)This ordering of sentiments further worsens the overall accuracy.
df['responses'] = df['responses'].str.replace('.', '', regex=False)
df['responses'] = df['responses'].apply(lambda x: x if x in ['negative', 'positive', 'neutral'] else "other")
df['lm_match'] = df['label_text'] == df['responses']
acc = df.lm_match.mean()
acc0.4818904593639576positive sentences are classified correctly at the highest rate so far, and negative sentiment accuracy is very good, but the model does terribly on neutral sentences.
make_cm(df)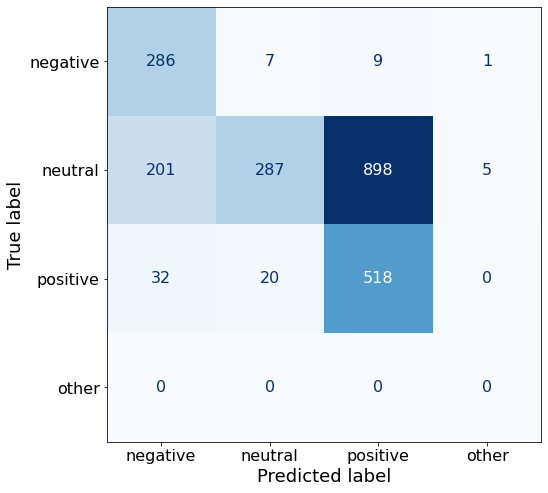
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_F.csv', index=False)The next ordering of sentiments:
promptG = """Label the following TEXT with a single word: neutral, negative, or positive
TEXT: {text}"""df, acc = generate_responses(dataset, promptG)Label the following TEXT with a single word: neutral, negative, or positive
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral.', 'positive', 'positive.', 'neutral', 'negative',
'negative.', 'positive profit', 'negot'], dtype=object)The accuracy of 61% is worse than the best-performing Prompt D (68%).
df['responses'] = df['responses'].str.replace('.', '', regex=False)
df['responses'] = df['responses'].apply(lambda x: x if x in ['negative', 'positive', 'neutral'] else "other")
df['lm_match'] = df['label_text'] == df['responses']
acc = df.lm_match.mean()
acc0.6108657243816255make_cm(df)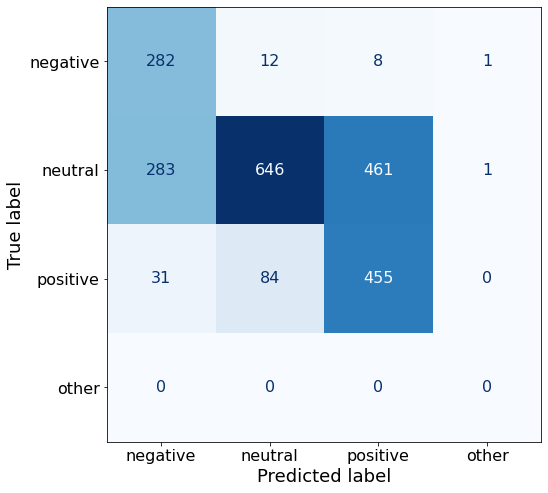
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_G.csv', index=False)The last ordering of sentiment:
promptH = """Label the following TEXT with a single word: neutral, positive, or negative
TEXT: {text}"""df, acc = generate_responses(dataset, promptH)Label the following TEXT with a single word: neutral, positive, or negative
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['positive', 'neutral.', 'positive.', 'neutral', 'negative',
'negative.', 'positive profit', 'negot'], dtype=object)This yields a 65% accuracy.
df['responses'] = df['responses'].str.replace('.', '', regex=False)
df['responses'] = df['responses'].apply(lambda x: x if x in ['negative', 'positive', 'neutral'] else "other")
df['lm_match'] = df['label_text'] == df['responses']
acc = df.lm_match.mean()
acc0.6541519434628975make_cm(df)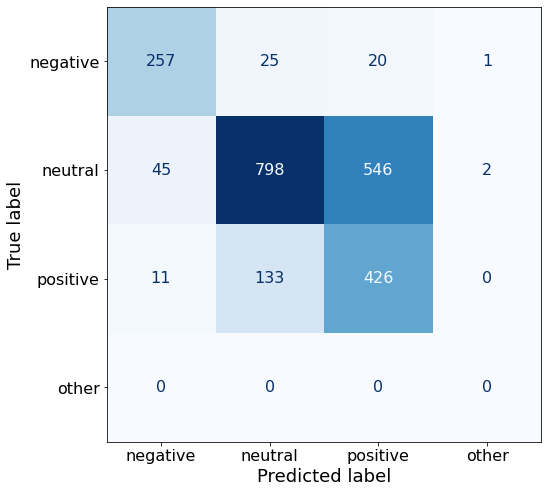
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_H.csv', index=False)I’ll make a small change to my best-performing prompt by adding a period at the end of the instruction.
promptI = """Label the following TEXT with a single word: positive, negative, or neutral.
TEXT: {text}"""df, acc = generate_responses(dataset, promptI)Label the following TEXT with a single word: positive, negative, or neutral.
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral.', 'positive', 'positive.', 'neutral', 'net income',
'negative', 'negative.', 'negative profit', 'nord', 'negot',
'the text', 'negation', 'neglig', 'subscription'], dtype=object)Adding a period to the end of the instruction worsens the accuracy a bit.
df['responses'] = df['responses'].str.replace('.', '', regex=False)
df['responses'] = df['responses'].apply(lambda x: x if x in ['negative', 'positive', 'neutral'] else "other")
df['lm_match'] = df['label_text'] == df['responses']
acc = df.lm_match.mean()
acc0.6612190812720848Adding a period worsens the performance on neutral by 51 sentences.
make_cm(df)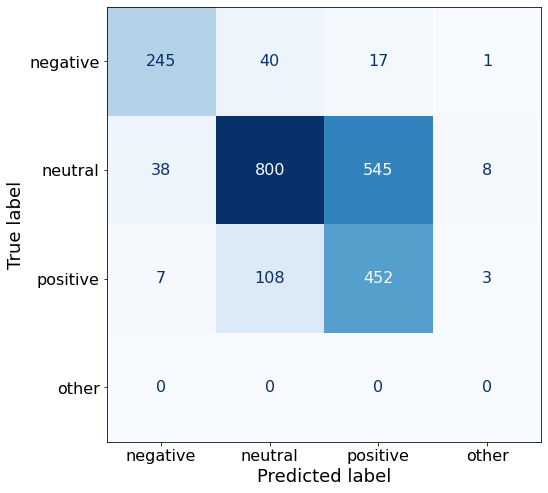
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_I.csv', index=False)I’ll now shift my attention to few-shot prompts, starting with 3-Shot.
exclude_idxs = [0, 1, 292]promptJ_ds = ds_subset(dataset, exclude_idxs)
promptJ_dsDataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2261
})promptJ = """Label the following TEXT with a single word: positive, negative, or neutral
TEXT: {text}"""Since ordering seems to matter, I’ll start with a neutral example, positive example and negative example.
examples = []
for idx in exclude_idxs:
examples.append((dataset[idx]['sentence'], dataset[idx]['label_text']))
examples[('According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .',
'neutral'),
("For the last quarter of 2010 , Componenta 's net sales doubled to EUR131m from EUR76m for the same period a year earlier , while it moved to a zero pre-tax profit from a pre-tax loss of EUR7m .",
'positive'),
('Jan. 6 -- Ford is struggling in the face of slowing truck and SUV sales and a surfeit of up-to-date , gotta-have cars .',
'negative')]df = few_shot_responses(promptJ_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: In the third quarter of 2010 , net sales increased by 5.2 % to EUR 205.5 mn , and operating profit by 34.9 % to EUR 23.5 mn .df['responses'].unique()array(['positive', 'neutral', 'negative'], dtype=object)3-Shot prompting resulted in the best accuracy so far! ~71%.
df['responses'] = df['responses'].apply(lambda x: x if x in ['negative', 'positive', 'neutral'] else "other")
df['lm_match'] = df['label_text'] == df['responses']
acc = df.lm_match.mean()
acc0.709420610349403Compared to my best 0-Shot Prompt D (68%) this prompt results in the model significantly underperforming on negative sentences, (131 < 240), but more than making up for it on neutral sentences (1042 > 851).
make_cm(df)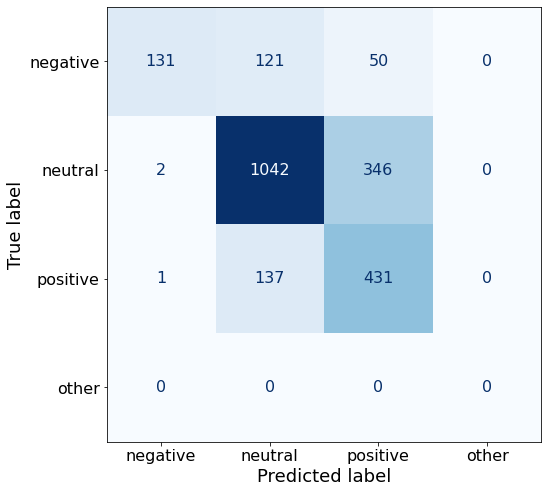
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_J.csv', index=False)I’ll re-order the examples and use the same Prompt J.
exclude_idxs = [0, 292, 1]examples = []
for idx in exclude_idxs:
examples.append((dataset[idx]['sentence'], dataset[idx]['label_text']))
examples[('According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .',
'neutral'),
('Jan. 6 -- Ford is struggling in the face of slowing truck and SUV sales and a surfeit of up-to-date , gotta-have cars .',
'negative'),
("For the last quarter of 2010 , Componenta 's net sales doubled to EUR131m from EUR76m for the same period a year earlier , while it moved to a zero pre-tax profit from a pre-tax loss of EUR7m .",
'positive')]df = few_shot_responses(promptJ_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: In the third quarter of 2010 , net sales increased by 5.2 % to EUR 205.5 mn , and operating profit by 34.9 % to EUR 23.5 mn .df['responses'].unique()array(['positive', 'neutral', 'negative'], dtype=object)Changing the order of examples to neutral, negative, positive increases the overall accuracy to almost 75%!
df['responses'] = df['responses'].apply(lambda x: x if x in ['negative', 'positive', 'neutral'] else "other")
df['lm_match'] = df['label_text'] == df['responses']
acc = df.lm_match.mean()
acc0.7487837240159222The model improves on all three sentiments compared to Prompt J.
make_cm(df)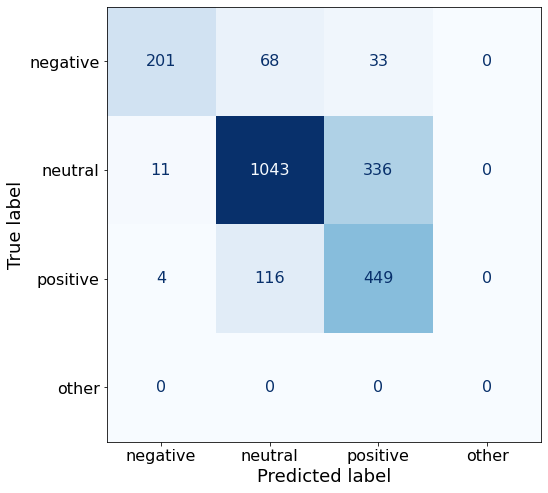
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_K.csv', index=False)I’ll re-order the examples and use the same Prompt J.
exclude_idxs = [1, 0, 292]
examples = []
for idx in exclude_idxs:
examples.append((dataset[idx]['sentence'], dataset[idx]['label_text']))
examples[("For the last quarter of 2010 , Componenta 's net sales doubled to EUR131m from EUR76m for the same period a year earlier , while it moved to a zero pre-tax profit from a pre-tax loss of EUR7m .",
'positive'),
('According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .',
'neutral'),
('Jan. 6 -- Ford is struggling in the face of slowing truck and SUV sales and a surfeit of up-to-date , gotta-have cars .',
'negative')]df = few_shot_responses(promptJ_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: In the third quarter of 2010 , net sales increased by 5.2 % to EUR 205.5 mn , and operating profit by 34.9 % to EUR 23.5 mn .df['responses'].unique()array(['positive', 'neutral', 'negative'], dtype=object)This ordering of examples drops the accuracy to 68%.
df['responses'] = df['responses'].apply(lambda x: x if x in ['negative', 'positive', 'neutral'] else "other")
df['lm_match'] = df['label_text'] == df['responses']
acc = df.lm_match.mean()
acc0.6811145510835913Compared to the best-performing Prompt K, this prompt yields a better accuracy for positive sentences (491 > 449).
make_cm(df)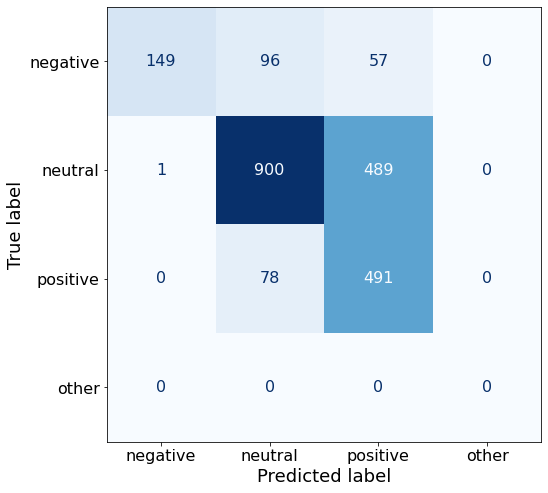
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_L.csv', index=False)I’ll re-order the examples and use the same Prompt J.
exclude_idxs = [1, 292, 0]
examples = []
for idx in exclude_idxs:
examples.append((dataset[idx]['sentence'], dataset[idx]['label_text']))
examples[("For the last quarter of 2010 , Componenta 's net sales doubled to EUR131m from EUR76m for the same period a year earlier , while it moved to a zero pre-tax profit from a pre-tax loss of EUR7m .",
'positive'),
('Jan. 6 -- Ford is struggling in the face of slowing truck and SUV sales and a surfeit of up-to-date , gotta-have cars .',
'negative'),
('According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .',
'neutral')]df = few_shot_responses(promptJ_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: In the third quarter of 2010 , net sales increased by 5.2 % to EUR 205.5 mn , and operating profit by 34.9 % to EUR 23.5 mn .df['responses'].unique()array(['positive', 'neutral', 'negative'], dtype=object)This ordering of examples worsens the accuracy, dropping it down to 57%.
df['responses'] = df['responses'].apply(lambda x: x if x in ['negative', 'positive', 'neutral'] else "other")
df['lm_match'] = df['label_text'] == df['responses']
acc = df.lm_match.mean()
acc0.5696594427244582This prompt yields better results for positive sentiment (514 > 449) than the best overall performing Prompt J.
make_cm(df)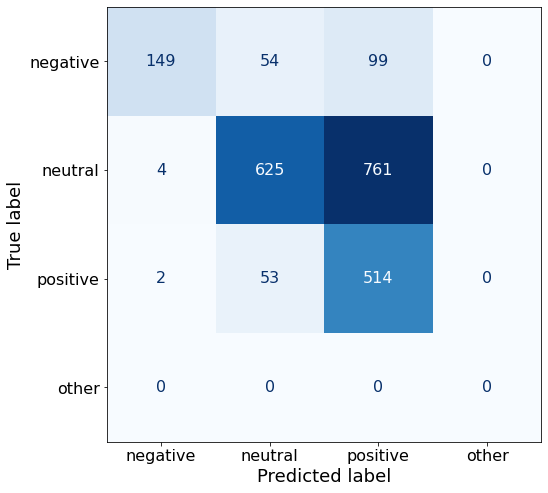
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_M.csv', index=False)Trying the next ordering of sentiments:
exclude_idxs = [292, 0, 1]
examples = []
for idx in exclude_idxs:
examples.append((dataset[idx]['sentence'], dataset[idx]['label_text']))
examples[('Jan. 6 -- Ford is struggling in the face of slowing truck and SUV sales and a surfeit of up-to-date , gotta-have cars .',
'negative'),
('According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .',
'neutral'),
("For the last quarter of 2010 , Componenta 's net sales doubled to EUR131m from EUR76m for the same period a year earlier , while it moved to a zero pre-tax profit from a pre-tax loss of EUR7m .",
'positive')]df = few_shot_responses(promptJ_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: In the third quarter of 2010 , net sales increased by 5.2 % to EUR 205.5 mn , and operating profit by 34.9 % to EUR 23.5 mn .df['responses'].unique()array(['positive', 'neutral', 'negative'], dtype=object)This ordering results in the second-highest overall accuracy at 74%.
df['responses'] = df['responses'].apply(lambda x: x if x in ['negative', 'positive', 'neutral'] else "other")
df['lm_match'] = df['label_text'] == df['responses']
acc = df.lm_match.mean()
acc0.7394957983193278This prompt performs slightly worse for all three sentiments than the so far best-overall performing Prompt K.
make_cm(df)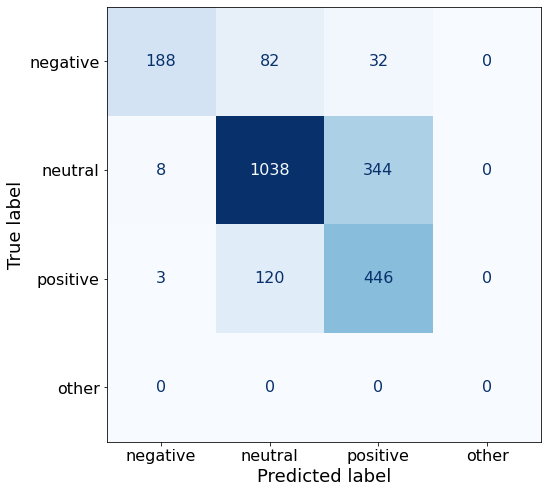
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_N.csv', index=False)Here’s the final 3-sentiment ordering:
exclude_idxs = [292, 1, 0]
examples = []
for idx in exclude_idxs:
examples.append((dataset[idx]['sentence'], dataset[idx]['label_text']))
examples[('Jan. 6 -- Ford is struggling in the face of slowing truck and SUV sales and a surfeit of up-to-date , gotta-have cars .',
'negative'),
("For the last quarter of 2010 , Componenta 's net sales doubled to EUR131m from EUR76m for the same period a year earlier , while it moved to a zero pre-tax profit from a pre-tax loss of EUR7m .",
'positive'),
('According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .',
'neutral')]df = few_shot_responses(promptJ_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: In the third quarter of 2010 , net sales increased by 5.2 % to EUR 205.5 mn , and operating profit by 34.9 % to EUR 23.5 mn .df['responses'].unique()array(['positive', 'neutral', 'negative'], dtype=object)This ordering of sentiment does not beat my so far best-performing accuracy.
df['responses'] = df['responses'].apply(lambda x: x if x in ['negative', 'positive', 'neutral'] else "other")
df['lm_match'] = df['label_text'] == df['responses']
acc = df.lm_match.mean()
acc0.599734630694383This prompt yields a much better performance on positive sentiment than my best performing Prompt K (525 > 449).
make_cm(df)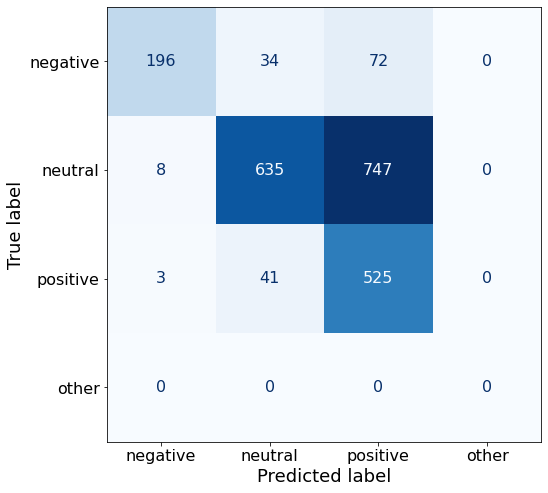
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_O.csv', index=False)Next, I’ll increase the number of examples to 6. Note that I won’t be trying all permutations but a few random ones.
exclude_idxs = [random.randint(0, 2263) for _ in range(6)]
promptP_ds = ds_subset(dataset, exclude_idxs=exclude_idxs)
promptP_dsDataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2258
})The random examples I have picked don’t include a negative sentence. I’m curious to see how the model performs on this.
examples = []
for idx in exclude_idxs:
examples.append((dataset[idx]['sentence'], dataset[idx]['label_text']))
[el[1] for el in examples]['positive', 'neutral', 'positive', 'neutral', 'positive', 'positive']df = few_shot_responses(promptP_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)This prompt results in a worse performance in overall accuracy.
get_acc(df)0.6390611160318866Even though no negative examples were given, this prompt yields considerably more correct negative sentences (289) than the best-performing Prompt K (201).
make_cm(df)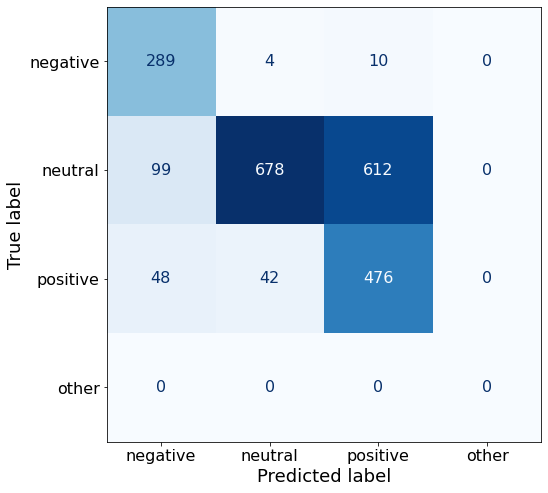
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_P.csv', index=False)I’ll try another random set of 6 examples, this time making sure there’s at least one of each sentiment.
exclude_idxs = [random.randint(0, 2263) for _ in range(6)]
promptQ_ds = ds_subset(dataset, exclude_idxs=exclude_idxs)
examples = []
for idx in exclude_idxs:
examples.append((dataset[idx]['sentence'], dataset[idx]['label_text']))
promptQ_ds, [el[1] for el in examples](Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2258
}),
['positive', 'positive', 'positive', 'neutral', 'negative', 'neutral'])df = few_shot_responses(promptQ_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative', 'live'], dtype=object)This set of 6 examples does not improve upon the best-overall accuracy of 75%.
get_acc(df)0.6572187776793623Something we haven’t seen in awhile, an other response.
make_cm(df)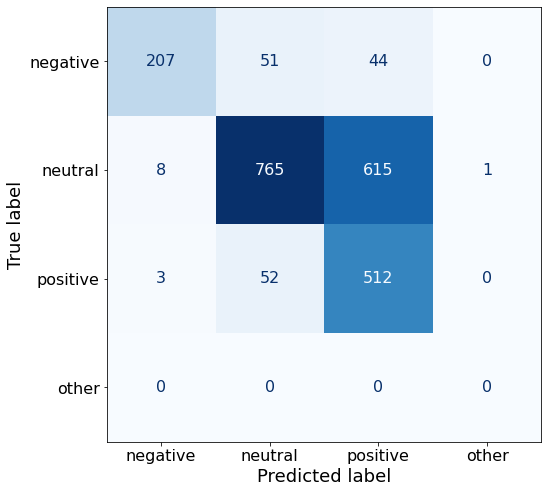
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_Q.csv', index=False)exclude_idxs = [random.randint(0, 2263) for _ in range(6)]
promptR_ds = ds_subset(dataset, exclude_idxs=exclude_idxs)
examples = []
for idx in exclude_idxs:
examples.append((dataset[idx]['sentence'], dataset[idx]['label_text']))
promptR_ds, [el[1] for el in examples](Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2258
}),
['neutral', 'neutral', 'positive', 'positive', 'neutral', 'neutral'])df = few_shot_responses(promptR_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)No improvements on accuracy with this prompt.
get_acc(df)0.6483613817537643Compared to the best-performing Prompt K, this prompt yields considerably more correct negative (285 > 201) and positive (493 > 449) sentences but underperforms on neutral sentences (686 < 1043).
make_cm(df)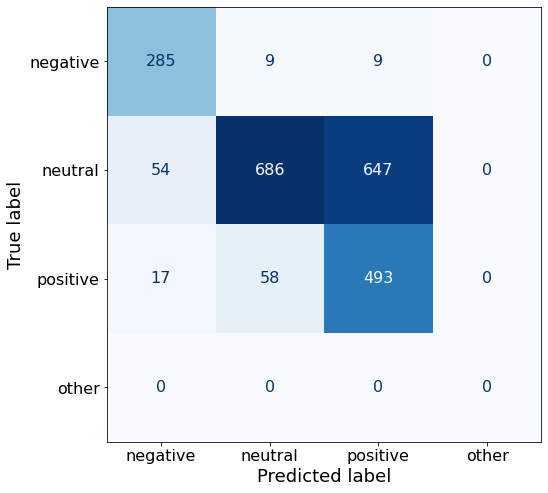
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_R.csv', index=False)exclude_idxs = [random.randint(0, 2263) for _ in range(6)]
promptS_ds = ds_subset(dataset, exclude_idxs=exclude_idxs)
examples = []
for idx in exclude_idxs:
examples.append((dataset[idx]['sentence'], dataset[idx]['label_text']))
promptS_ds, [el[1] for el in examples](Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2258
}),
['neutral', 'neutral', 'positive', 'neutral', 'positive', 'neutral'])This set of examples has no negative sentences and a majority of neutral sentences.
df = few_shot_responses(promptS_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Starting from v4.46, the `logits` model output will have the same type as the model (except at train time, where it will always be FP32)df['responses'].unique()array(['negative', 'positive', 'neutral'], dtype=object)This set of examples does not improve on the best-overall accuracy of 75% (Prompt K).
get_acc(df)0.6297608503100088It does, however, have a considerably larger number of correctly labeled negative sentences (292 > 201).
make_cm(df)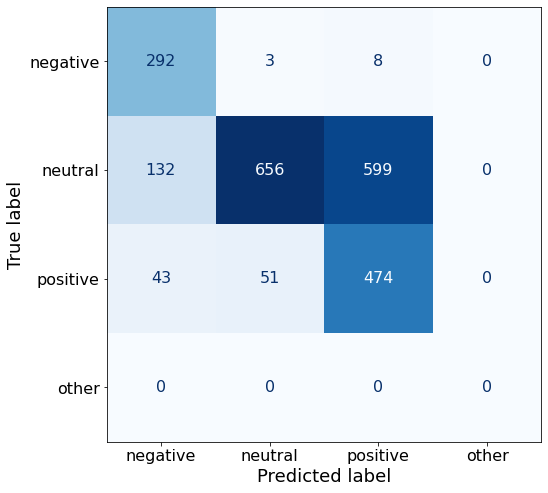
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_S.csv', index=False)I’ll try one more 6-shot prompt before I increase the number of examples.
exclude_idxs = [random.randint(0, 2263) for _ in range(6)]
promptT_ds = ds_subset(dataset, exclude_idxs=exclude_idxs)
examples = []
for idx in exclude_idxs:
examples.append((dataset[idx]['sentence'], dataset[idx]['label_text']))
promptT_ds, [el[1] for el in examples](Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2258
}),
['neutral', 'neutral', 'positive', 'neutral', 'negative', 'neutral'])df = few_shot_responses(promptT_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)Similar to the other 6-Shot examples, this set of examples does not improve on the best overall accuracy.
get_acc(df)0.6886625332152347make_cm(df)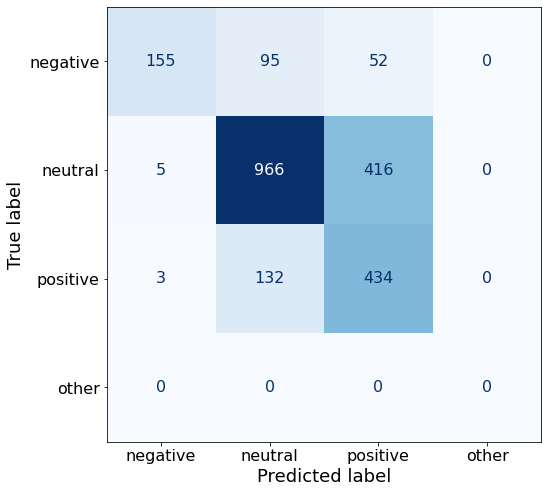
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_T.csv', index=False)I’ll now increase the number of examples in the prompt to 12, and try out 5 random sets of 12 examples.
exclude_idxs = [random.randint(0, 2263) for _ in range(12)]
promptU_ds = ds_subset(dataset, exclude_idxs=exclude_idxs)
examples = []
for idx in exclude_idxs:
examples.append((dataset[idx]['sentence'], dataset[idx]['label_text']))
promptU_ds, [el[1] for el in examples](Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2252
}),
['positive',
'negative',
'positive',
'neutral',
'positive',
'positive',
'neutral',
'positive',
'neutral',
'neutral',
'positive',
'neutral'])df = few_shot_responses(promptU_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)Increasing the number of examples to 12, at least the 12 I chose here, doesn’t improve on the best overall accuracy.
get_acc(df)0.6549733570159858The number of correct positive sentences is considerably higher than Prompt K (496 > 449).
make_cm(df)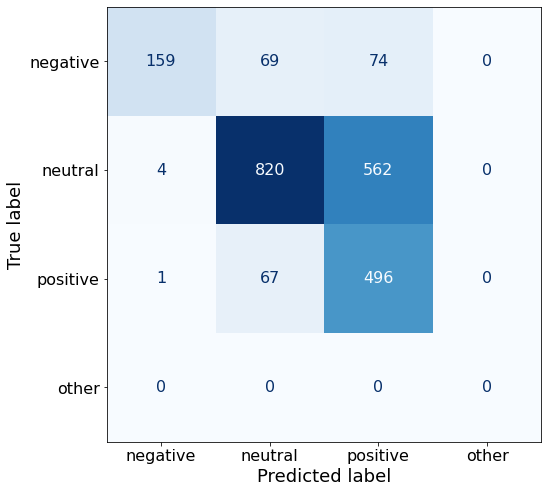
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_U.csv', index=False)exclude_idxs = [random.randint(0, 2263) for _ in range(12)]
promptV_ds = ds_subset(dataset, exclude_idxs=exclude_idxs)
examples = []
for idx in exclude_idxs:
examples.append((dataset[idx]['sentence'], dataset[idx]['label_text']))
promptV_ds, [el[1] for el in examples](Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2252
}),
['neutral',
'positive',
'positive',
'neutral',
'neutral',
'negative',
'negative',
'neutral',
'positive',
'neutral',
'positive',
'negative'])df = few_shot_responses(promptV_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: For the last quarter of 2010 , Componenta 's net sales doubled to EUR131m from EUR76m for the same period a year earlier , while it moved to a zero pre-tax profit from a pre-tax loss of EUR7m .df['responses'].unique()array(['positive', 'neutral', 'negative'], dtype=object)This prompt performs well, and competes with but doesn’t improve upon the best overall accuracy of 75%.
get_acc(df)0.7322380106571936This prompt performs considerably better on neutral sentences than Prompt K (1103 > 1043).
make_cm(df)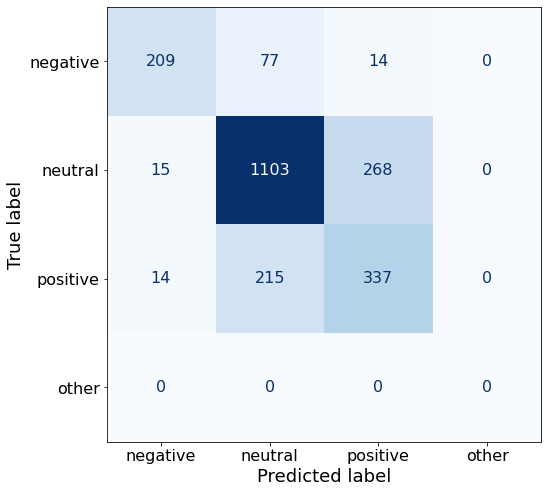
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_V.csv', index=False)exclude_idxs = [random.randint(0, 2263) for _ in range(12)]
promptW_ds = ds_subset(dataset, exclude_idxs=exclude_idxs)
examples = []
for idx in exclude_idxs:
examples.append((dataset[idx]['sentence'], dataset[idx]['label_text']))
promptW_ds, [el[1] for el in examples](Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2252
}),
['neutral',
'negative',
'neutral',
'positive',
'neutral',
'neutral',
'positive',
'neutral',
'neutral',
'negative',
'positive',
'neutral'])df = few_shot_responses(promptW_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)The accuracy worsens with this set of 12 examples.
get_acc(df)0.7042628774422736make_cm(df)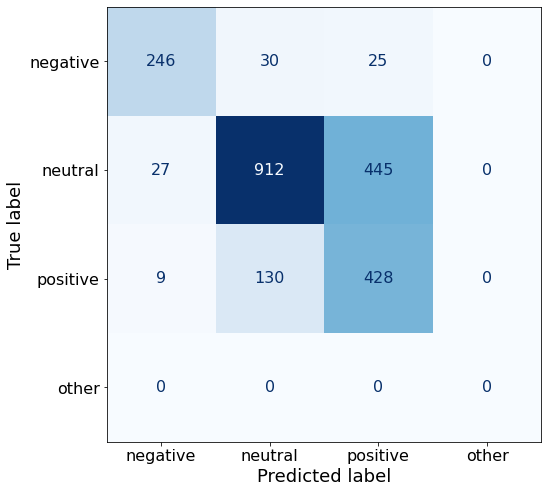
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_W.csv', index=False)def get_ds(n):
exclude_idxs = [random.randint(0, 2263) for _ in range(n)]
prompt_ds = ds_subset(dataset, exclude_idxs=exclude_idxs)
examples = []
for idx in exclude_idxs:
examples.append((dataset[idx]['sentence'], dataset[idx]['label_text']))
print(prompt_ds, [el[1] for el in examples])
return prompt_ds, examplespromptX_ds, examples = get_ds(12)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2252
}) ['positive', 'neutral', 'negative', 'neutral', 'positive', 'negative', 'neutral', 'negative', 'negative', 'neutral', 'neutral', 'negative']df = few_shot_responses(promptX_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Starting from v4.46, the `logits` model output will have the same type as the model (except at train time, where it will always be FP32)df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)Aha! This prompt improves upon the best overall accuracy, reaching about 77%.
get_acc(df)0.7659857904085258Compared to Prompt K (75%) this prompt performs worse on neutral sentences (1000 < 1043) but more than makes up for it on negative (270 > 201) and positive (455 > 449) sentences.
make_cm(df)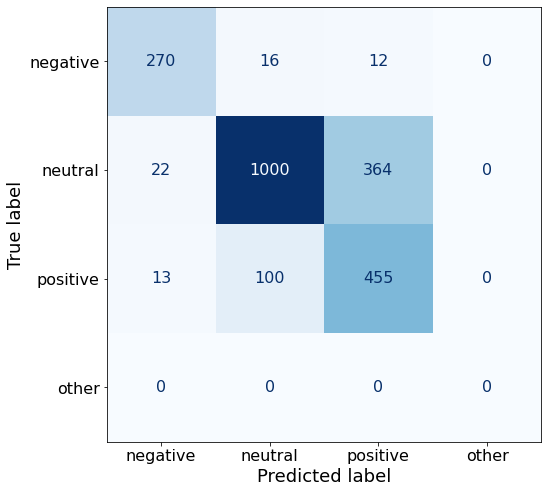
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_X.csv', index=False)promptY_ds, examples = get_ds(12)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2252
}) ['neutral', 'neutral', 'neutral', 'neutral', 'positive', 'neutral', 'neutral', 'positive', 'neutral', 'neutral', 'neutral', 'neutral']df = few_shot_responses(promptY_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['negative', 'positive', 'neutral'], dtype=object)This prompt does not improve on the best overall accuracy.
get_acc(df)0.7255772646536413This prompt performs well on negative and neutral sentences but its worse performance on positive sentences brings down the overall accuracy.
make_cm(df)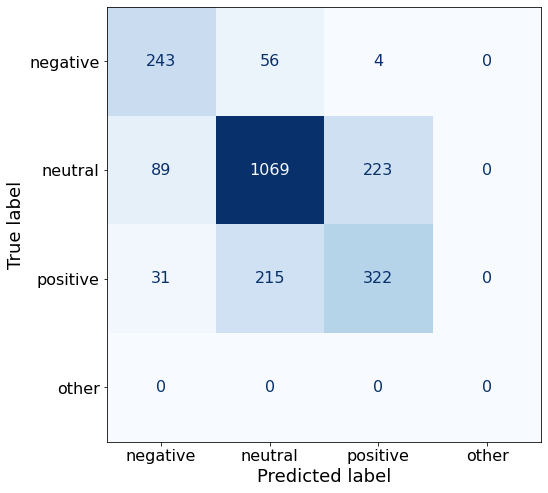
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_Y.csv', index=False)Next, I’ll try 5 prompts with 18 examples.
promptZ_ds, examples = get_ds(18)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2246
}) ['neutral', 'neutral', 'neutral', 'positive', 'neutral', 'neutral', 'neutral', 'positive', 'positive', 'neutral', 'positive', 'positive', 'neutral', 'positive', 'negative', 'negative', 'positive', 'neutral']df = few_shot_responses(promptZ_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)This prompt does not improve upon overall accuracy.
get_acc(df)0.7132680320569902make_cm(df)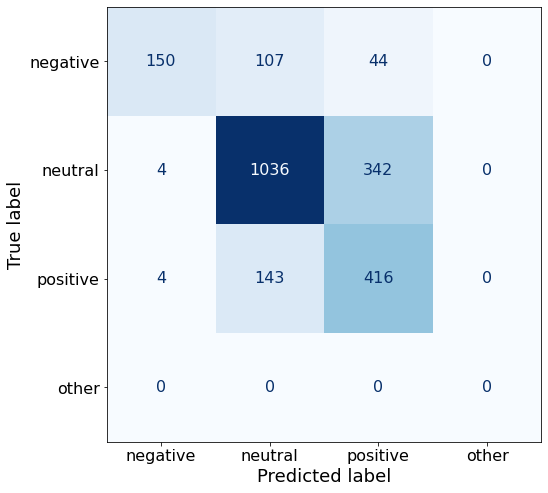
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_Z.csv', index=False)promptAA_ds, examples = get_ds(18)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2247
}) ['neutral', 'negative', 'neutral', 'neutral', 'neutral', 'neutral', 'neutral', 'positive', 'positive', 'neutral', 'negative', 'neutral', 'neutral', 'neutral', 'negative', 'neutral', 'positive', 'neutral']df = few_shot_responses(promptAA_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)This set of 18 examples increases the best overall accuraacy to almost 80%!
get_acc(df)0.7948375611927013Compared to Prompt X, this prompt performs worse on negative (206 < 270) and positive (400 < 455) but more than makes up for it on neutral sentences (1180 > 1000).
make_cm(df)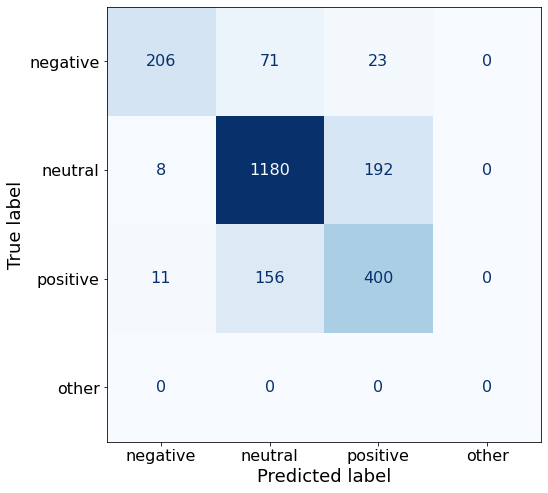
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AA.csv', index=False)promptAB_ds, examples = get_ds(18)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2246
}) ['neutral', 'neutral', 'neutral', 'positive', 'positive', 'neutral', 'neutral', 'neutral', 'negative', 'neutral', 'negative', 'neutral', 'negative', 'neutral', 'negative', 'neutral', 'positive', 'positive']df = few_shot_responses(promptAB_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)This prompt does not improve upon the best overall accuracy.
get_acc(df)0.7422083704363313make_cm(df)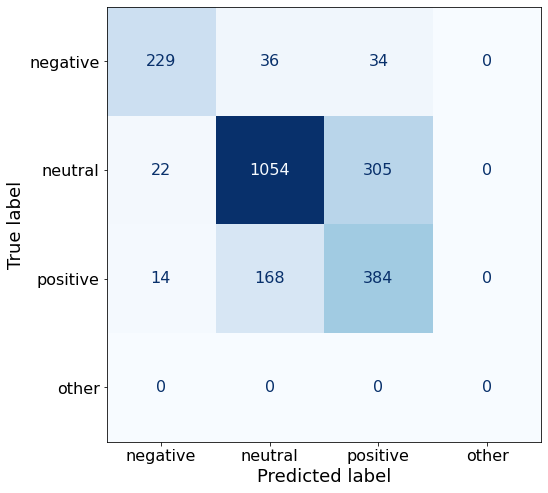
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AB.csv', index=False)promptAC_ds, examples = get_ds(18)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2246
}) ['neutral', 'neutral', 'positive', 'neutral', 'neutral', 'neutral', 'negative', 'neutral', 'neutral', 'neutral', 'positive', 'positive', 'positive', 'neutral', 'positive', 'neutral', 'positive', 'neutral']df = few_shot_responses(promptAC_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Starting from v4.46, the `logits` model output will have the same type as the model (except at train time, where it will always be FP32)df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)This prompt does not improve upon the best overall accuracy.
get_acc(df)0.6856634016028496make_cm(df)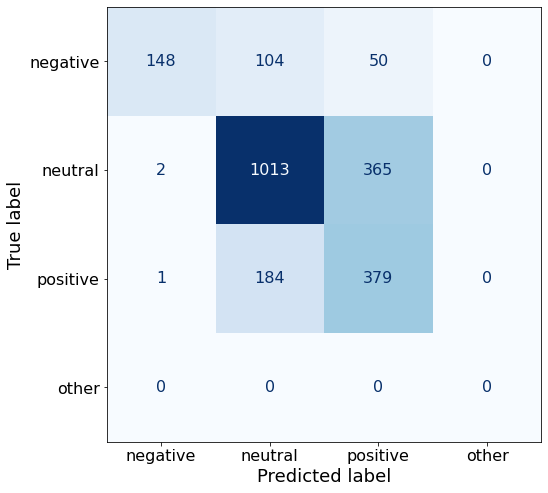
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AC.csv', index=False)promptAD_ds, examples = get_ds(18)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2246
}) ['neutral', 'neutral', 'positive', 'neutral', 'neutral', 'positive', 'positive', 'neutral', 'neutral', 'neutral', 'neutral', 'neutral', 'neutral', 'positive', 'positive', 'neutral', 'neutral', 'positive']df = few_shot_responses(promptAD_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)This prompt does not improve upon the best overall accuracy.
get_acc(df)0.7497773820124666This prompt yields considerably more correct negative sentences (271 > 206) than the best-performing Prompt AA.
make_cm(df)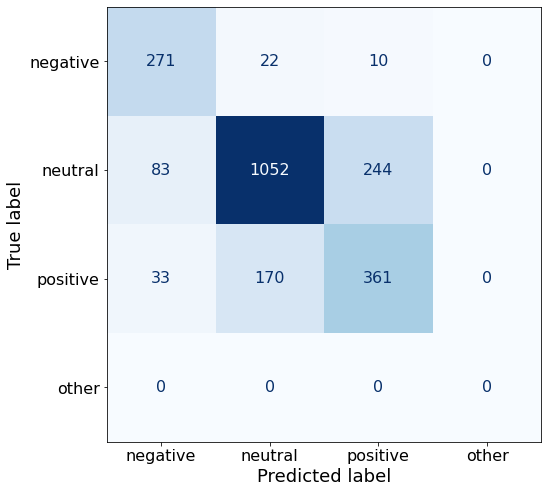
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AD.csv', index=False)Next, I’ll try 5 prompts with 24 examples each.
promptAE_ds, examples = get_ds(24)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2240
}) ['neutral', 'neutral', 'neutral', 'negative', 'neutral', 'neutral', 'neutral', 'negative', 'neutral', 'negative']df = few_shot_responses(promptAE_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)Increasing the number of examples to 24 (at least for these 24 examples) does not improve upon the overall accuracy.
get_acc(df)0.7491071428571429Compared to the best performing Prompt AA, this prompt yields considerably more correct neutral sentences (1267 > 1180).
make_cm(df)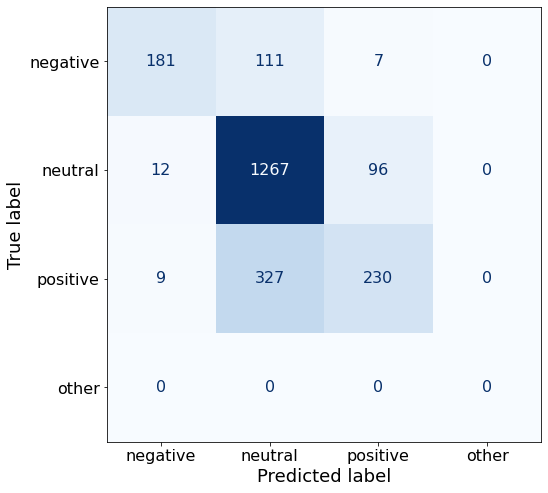
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AE.csv', index=False)promptAF_ds, examples = get_ds(24)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2240
}) ['positive', 'neutral', 'positive', 'neutral', 'neutral', 'neutral', 'neutral', 'neutral', 'neutral', 'neutral']df = few_shot_responses(promptAF_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)This prompt doesn’t improve upon the best overall accuracy, and performs better than Prompt AA on neutral sentences.
get_acc(df)0.7308035714285714make_cm(df)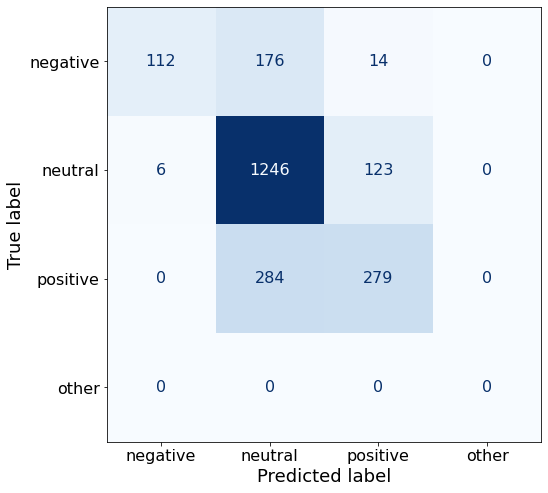
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AF.csv', index=False)promptAG_ds, examples = get_ds(24)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2240
}) ['neutral', 'neutral', 'neutral', 'neutral', 'neutral', 'neutral', 'neutral', 'positive', 'neutral', 'neutral']df = few_shot_responses(promptAG_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)The same trend continues for this set of 24 examples.
get_acc(df)0.75make_cm(df)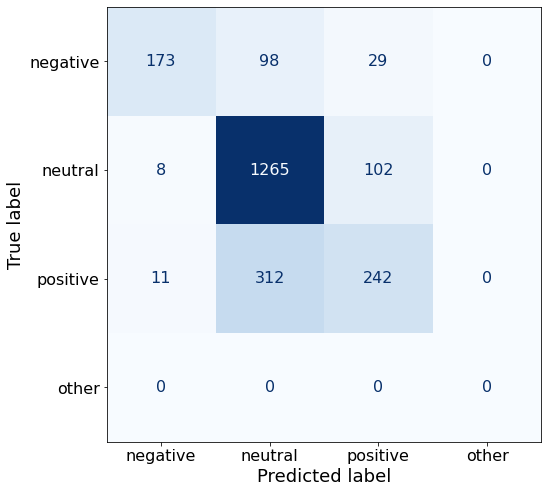
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AG.csv', index=False)Two more 24-Shot prompts to go.
promptAH_ds, examples = get_ds(24)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2240
}) ['positive', 'neutral', 'neutral', 'neutral', 'negative', 'neutral', 'negative', 'neutral', 'neutral', 'neutral']df = few_shot_responses(promptAH_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Starting from v4.46, the `logits` model output will have the same type as the model (except at train time, where it will always be FP32)df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)This prompt does not improve upon the best overall accuracy (though it comes close).
get_acc(df)0.7745535714285714This prompt yields more correct negative sentences than Prompt AA (233 > 206).
make_cm(df)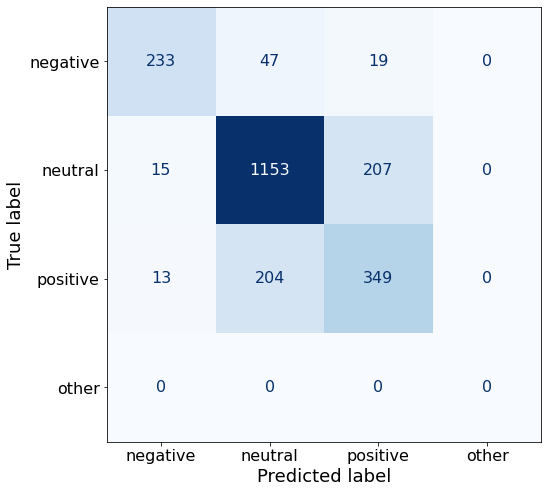
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AH.csv', index=False)promptAI_ds, examples = get_ds(24)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2241
}) ['neutral', 'neutral', 'neutral', 'neutral', 'neutral', 'negative', 'neutral', 'neutral', 'positive', 'neutral']df = few_shot_responses(promptAI_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)This prompt does not improve upon the best overall accuracy.
get_acc(df)0.7536813922356091This prompt yields considerably more correct neutral sentences than the best performing Prompt AA (1266 > 1180).
make_cm(df)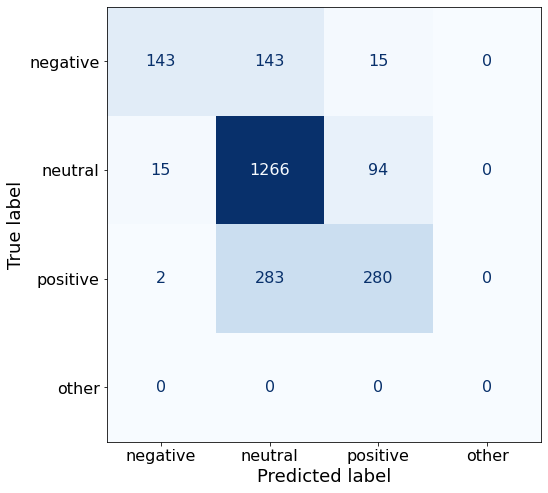
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AI.csv', index=False)Next, I’ll try 5 different 30-Shot prompts.
promptAJ_ds, examples = get_ds(30)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2234
}) ['neutral', 'neutral', 'positive', 'neutral', 'neutral', 'positive', 'neutral', 'negative', 'neutral', 'neutral']df = few_shot_responses(promptAJ_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)This prompt doesn’t improve the best overall accuracy.
get_acc(df)0.7739480752014324As seems to be the trend, this prompt results in more correct neutral responses (1284) than Prompt AA (1180).
make_cm(df)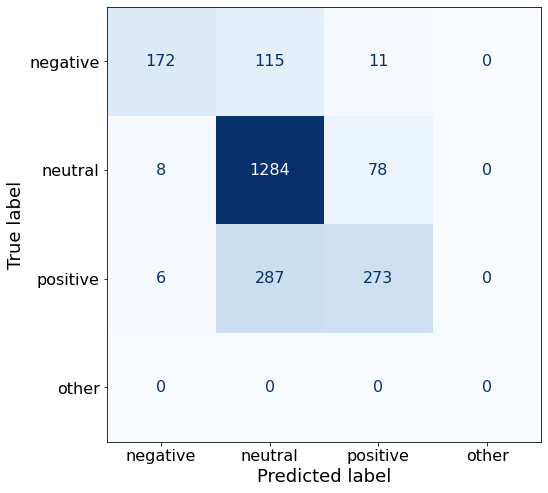
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AJ.csv', index=False)promptAK_ds, examples = get_ds(30)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2234
}) ['neutral', 'neutral', 'neutral', 'negative', 'negative', 'positive', 'neutral', 'neutral', 'positive', 'positive']df = few_shot_responses(promptAK_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)The model performs considerably worse with these 30 examples.
get_acc(df)0.6777081468218442make_cm(df)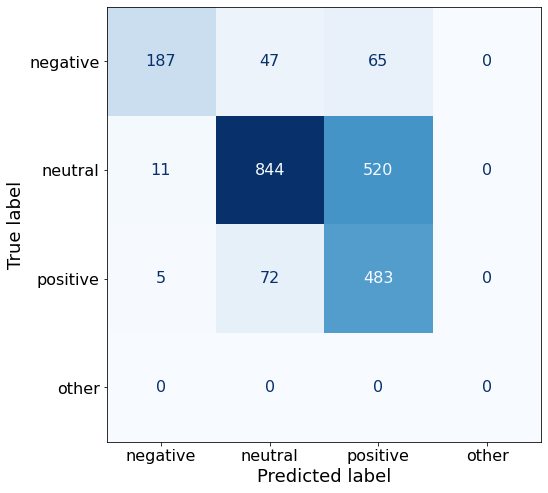
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AK.csv', index=False)promptAL_ds, examples = get_ds(30)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2234
}) ['positive', 'neutral', 'positive', 'positive', 'neutral', 'neutral', 'neutral', 'neutral', 'neutral', 'neutral']df = few_shot_responses(promptAL_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)The trend continues: the overall accuracy doesn’t improve but the model’s performance on neutral sentences does.
get_acc(df)0.76544315129812make_cm(df)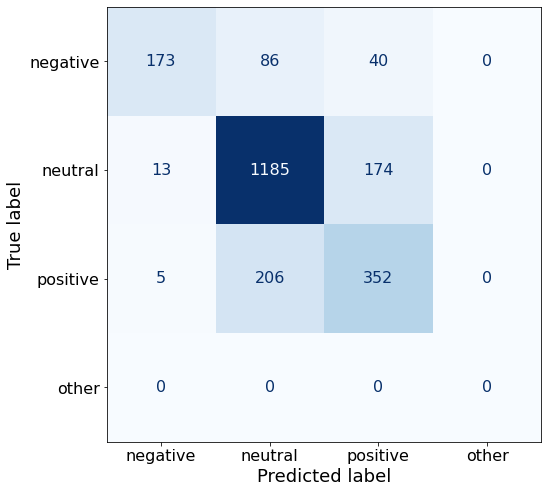
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AL.csv', index=False)Two more 30-Shot prompts to go.
promptAM_ds, examples = get_ds(30)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2234
}) ['negative', 'neutral', 'positive', 'negative', 'neutral', 'neutral', 'positive', 'negative', 'positive', 'neutral']df = few_shot_responses(promptAM_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)The overall accuracy doesn’t improve but the model’s performance on negative and positive sentences does.
get_acc(df)0.7484333034914951make_cm(df)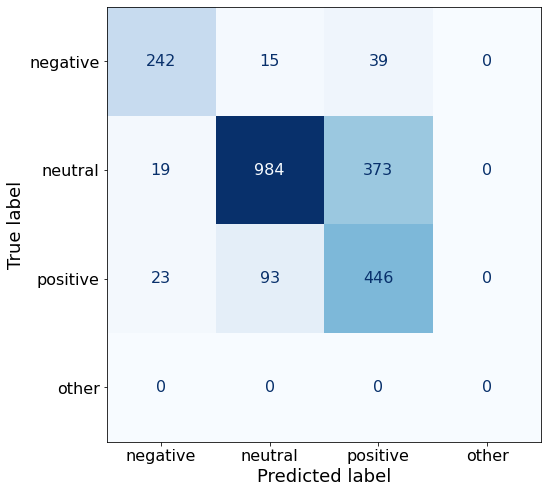
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AM.csv', index=False)promptAN_ds, examples = get_ds(30)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2234
}) ['positive', 'neutral', 'neutral', 'neutral', 'negative', 'neutral', 'neutral', 'neutral', 'neutral', 'neutral']df = few_shot_responses(promptAN_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)The overall accuracy doesn’t improve but the model’s performance on positive sentences does.
get_acc(df)0.7381378692927484make_cm(df)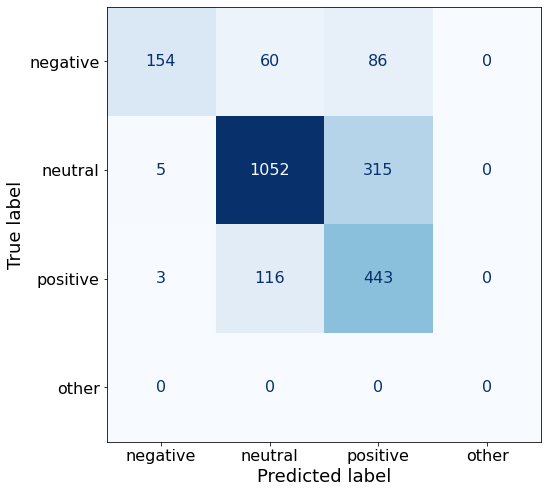
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AN.csv', index=False)Next, I’ll increase the number of examples to 45.
promptAO_ds, examples = get_ds(45)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2219
}) ['neutral', 'neutral', 'positive', 'neutral', 'neutral', 'negative', 'neutral', 'neutral', 'positive', 'neutral']df = few_shot_responses(promptAO_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)The overall accuracy doesn’t improve but the model’s performance on positive sentences does.
get_acc(df)0.7417755745831456make_cm(df)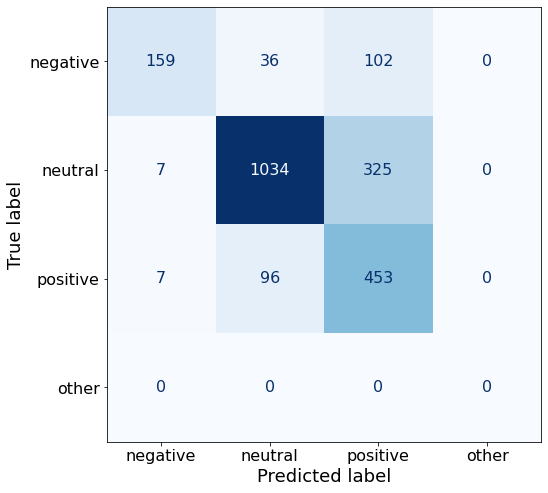
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AO.csv', index=False)promptAP_ds, examples = get_ds(45)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2219
}) ['neutral', 'positive', 'negative', 'neutral', 'positive', 'neutral', 'positive', 'positive', 'neutral', 'positive']df = few_shot_responses(promptAP_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)The overall accuracy doesn’t improve but the model’s performance on neutral sentences does.
get_acc(df)0.7872915727805317make_cm(df)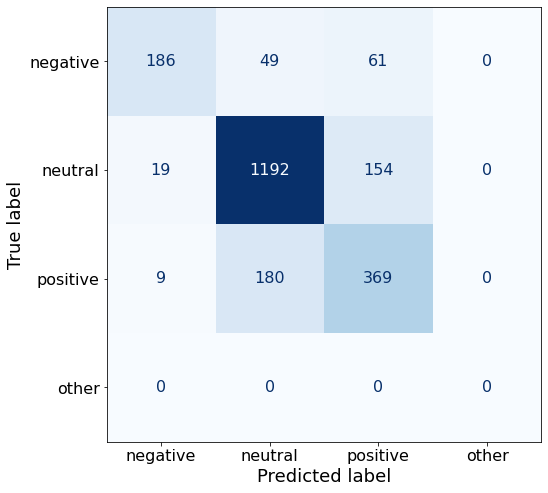
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AP.csv', index=False)promptAQ_ds, examples = get_ds(45)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2219
}) ['neutral', 'neutral', 'negative', 'neutral', 'neutral', 'positive', 'positive', 'neutral', 'neutral', 'neutral']df = few_shot_responses(promptAQ_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)The overall accuracy doesn’t improve but the model’s performance on neutral sentences does.
get_acc(df)0.7201442091031997make_cm(df)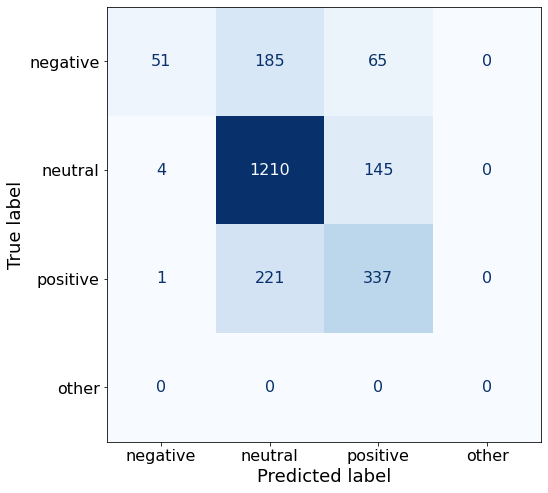
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AQ.csv', index=False)promptAR_ds, examples = get_ds(45)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2219
}) ['neutral', 'negative', 'neutral', 'positive', 'neutral', 'neutral', 'positive', 'positive', 'neutral', 'positive']df = few_shot_responses(promptAR_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Starting from v4.46, the `logits` model output will have the same type as the model (except at train time, where it will always be FP32)df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)This prompt performs worse than the best overall Prompt AA.
get_acc(df)0.7386210004506535make_cm(df)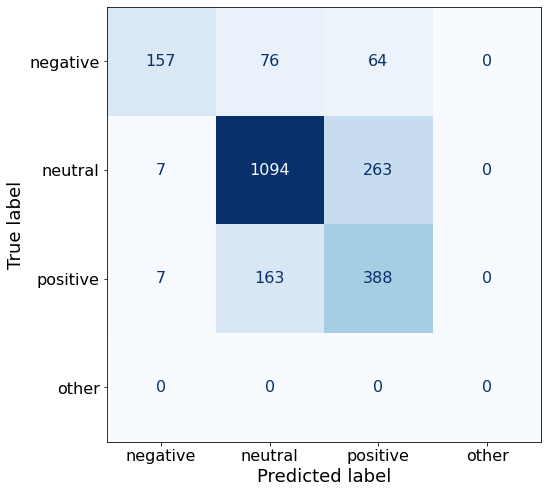
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AR.csv', index=False)promptAS_ds, examples = get_ds(45)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2219
}) ['neutral', 'negative', 'neutral', 'neutral', 'neutral', 'neutral', 'neutral', 'neutral', 'neutral', 'neutral']df = few_shot_responses(promptAS_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: For the last quarter of 2010 , Componenta 's net sales doubled to EUR131m from EUR76m for the same period a year earlier , while it moved to a zero pre-tax profit from a pre-tax loss of EUR7m .The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Starting from v4.46, the `logits` model output will have the same type as the model (except at train time, where it will always be FP32)df['responses'].unique()array(['positive', 'neutral', 'negative'], dtype=object)Compared to Prompt AA, this prompt yields a worse overall accuracy but improves on neutral sentences (1291 > 1180).
get_acc(df)0.7494366831906264make_cm(df)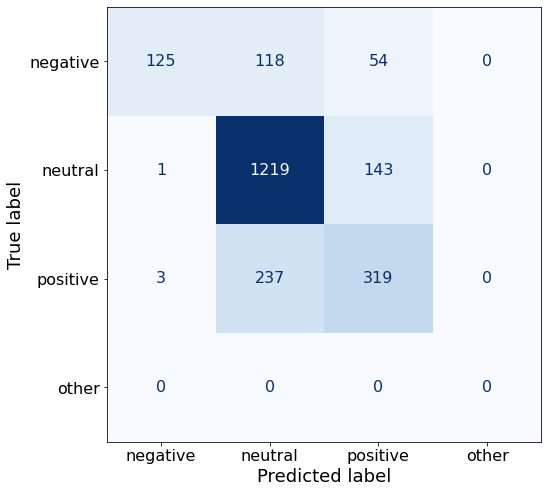
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AS.csv', index=False)Next, I’ll move on to the final number of examples: 60.
promptAT_ds, examples = get_ds(60)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2204
}) ['positive', 'neutral', 'neutral', 'negative', 'negative', 'neutral', 'neutral', 'neutral', 'negative', 'neutral']df = few_shot_responses(promptAT_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)Upping the number of examples to 60 does not improve results.
get_acc(df)0.7218693284936479make_cm(df)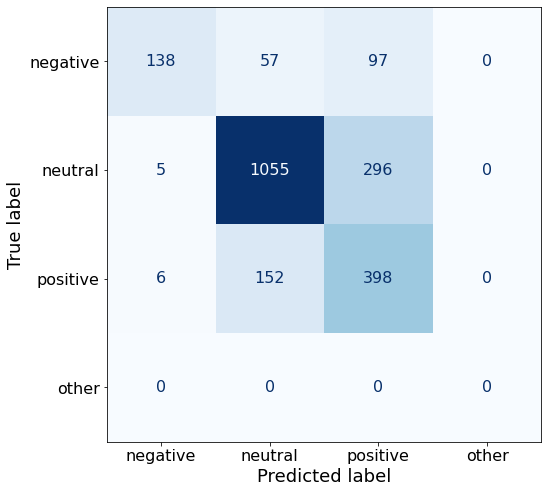
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AT.csv', index=False)promptAU_ds, examples = get_ds(60)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2204
}) ['neutral', 'positive', 'neutral', 'positive', 'negative', 'positive', 'positive', 'negative', 'positive', 'neutral']df = few_shot_responses(promptAU_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)Compared to Prompt AA, this prompt yields a worse overall accuracy but improves on neutral sentences (1237 > 1180).
get_acc(df)0.7686025408348457make_cm(df)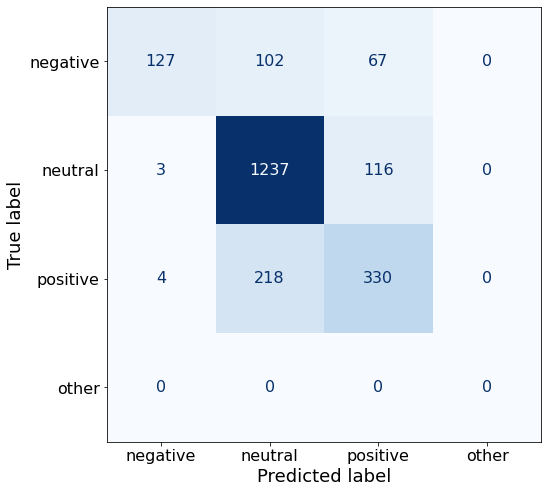
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AU.csv', index=False)promptAV_ds, examples = get_ds(60)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2204
}) ['positive', 'neutral', 'neutral', 'neutral', 'positive', 'positive', 'neutral', 'positive', 'negative', 'neutral']df = few_shot_responses(promptAV_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)Compared to Prompt AA, this prompt yields a worse overall accuracy but improves on neutral sentences (1206 > 1180).
get_acc(df)0.7545372050816697make_cm(df)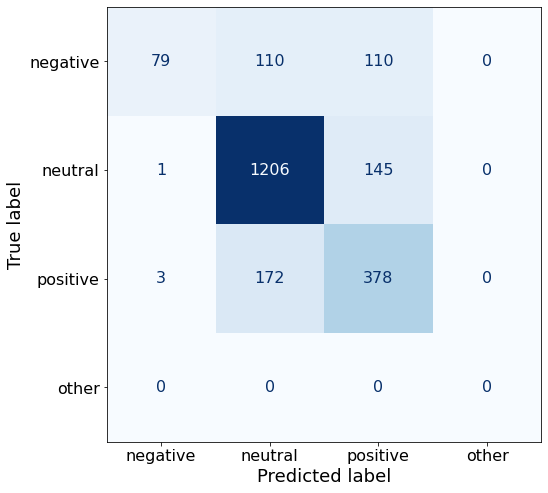
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AV.csv', index=False)promptAW_ds, examples = get_ds(60)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2204
}) ['neutral', 'neutral', 'neutral', 'neutral', 'neutral', 'neutral', 'negative', 'neutral', 'neutral', 'neutral']df = few_shot_responses(promptAW_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)This prompt does not improve upon Prompt AA results.
get_acc(df)0.7445553539019963make_cm(df)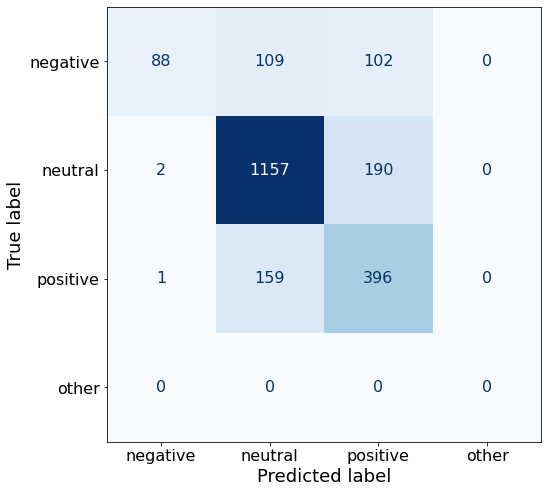
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AW.csv', index=False)promptAX_ds, examples = get_ds(60)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2204
}) ['neutral', 'neutral', 'negative', 'negative', 'neutral', 'negative', 'positive', 'neutral', 'positive', 'negative']df = few_shot_responses(promptAX_ds, promptJ, examples)Label the following TEXT with a single word: positive, negative, or neutral
TEXT: According to Gran , the company has no plans to move all production to Russia , although that is where the company is growing .df['responses'].unique()array(['neutral', 'positive', 'negative'], dtype=object)Aha! We finally improve on the overall accuracy of Prompt AA. This prompt yields a slightly higher accuracy that still rounds off to 80%.
get_acc(df)0.7962794918330308make_cm(df)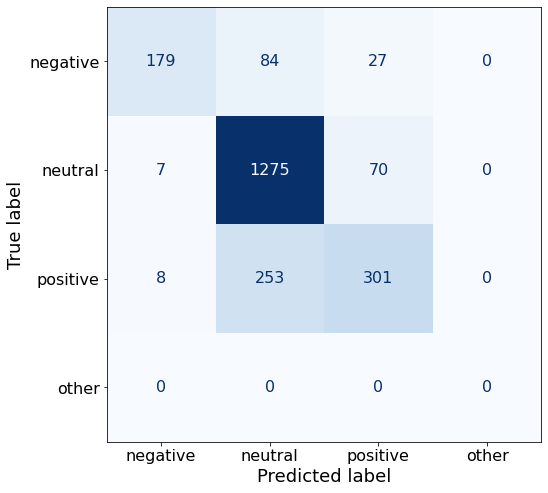
df.to_csv('/notebooks/Qwen2-0.5B-Instruct_AX.csv', index=False)While 60-shot Prompt AX had a slightly higher accuracy (79.63%) I am going to pick the 16-Shot Prompt AA as my best prompt (79.48%) since it has less than a third of the examples, which translates to about a third of the tokens, thus leading to quicker response generation.
def test_gen(examples):
few_shot_examples = []
for example in examples:
few_shot_examples.append({"role": "user", "content": promptJ.format(text=example[0])})
few_shot_examples.append({"role": "assistant", "content": example[1]})
messages = few_shot_examples + [{"role": "user", "content": promptJ.format(text=dataset[0]['sentence'])}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=2
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0].strip().lower()
return responsepromptAA_ds, examples = get_ds(18)Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2246
}) ['negative', 'neutral', 'positive', 'neutral', 'neutral', 'positive', 'neutral', 'neutral', 'positive', 'positive']1 response generation takes 72ms. Running full dataset inference 10 times will take about 30 minutes.
%timeit -n 10 test_gen(examples)The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.72 ms ± 42.9 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)few_shot_responses functiondef few_shot_responses(dataset, prompt, examples):
responses = []
dataset = dataset.map(add_prompt, fn_kwargs={"prompt": prompt})
few_shot_examples = []
for example in examples:
few_shot_examples.append({"role": "user", "content": prompt.format(text=example[0])})
few_shot_examples.append({"role": "assistant", "content": example[1]})
for row in dataset:
messages = few_shot_examples + [{"role": "user", "content": row['prompt']}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=2
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0].strip().lower()
responses.append(response)
# calculate accuracy
df = dataset.to_pandas()
df['responses'] = pd.Series(responses)
df['responses'] = df['responses'].apply(lambda x: x if x in ['negative', 'positive', 'neutral'] else "other")
df['lm_match'] = df['label_text'] == df['responses']
acc = df.lm_match.mean()
return df, accget_ds functiondef get_ds(n):
exclude_idxs = [random.randint(0, 2263) for _ in range(n)]
prompt_ds = ds_subset(dataset, exclude_idxs=exclude_idxs)
examples = []
for idx in exclude_idxs:
examples.append((dataset[idx]['sentence'], dataset[idx]['label_text']))
return prompt_ds, examplesI didn’t store the exact 18 examples that I used the first time for Prompt AA, so I had to try different 18-Shot examples until I achieved an accuracy close to 79.48%. It took me about 20 tries, but I finally found a set of examples that broke the 79% threshold.
for _ in range(20):
n = 18
ds, examples = get_ds(n)
if len(ds) != 2264 - n: pass
df, acc = few_shot_responses(ds, promptJ, examples)
if round(acc, 2) >= 0.79: breakacc0.815227070347284ds, len(examples)(Dataset({
features: ['sentence', 'label', 'label_text', '__index_level_0__'],
num_rows: 2246
}),
18)accs = []
for _ in range(10):
df, acc = few_shot_responses(ds, promptJ, examples)
accs.append(acc)For this prompt, the overall accuracy ranges from 80.8% to 82.4%.
pd.Series(accs).describe()count 10.000000
mean 0.816830
std 0.005397
min 0.807658
25% 0.814003
50% 0.817453
75% 0.819791
max 0.824577
dtype: float64Takeaways from my Qwen2-0.5B experiments:
Here are the results of Qwen2-0.5B in the context of the other models that I have experimented with:
| Model | Prompting Strategy | Overall Accuracy | negative |
neutral |
positive |
|---|---|---|---|---|---|
| claude-3-5-sonnet-20240620 | 3-Shot | 94.78% | 98% (297/303) | 94% (1302/1391) | 95% (544/570) |
| claude-3-opus-20240229 | 0-Shot | 94.13% | 98% (297/303) | 96% (1333/1391) | 88% (501/570) |
| phi-3.5 | 20-Shot | 93.94% | 96% (286/299) | 98% (1355/1379) | 83% (467/566) |
| phi-3 | 30-Shot w/System Prompt | 92.79% | 98% (290/297) | 94% (1284/1373) | 88% (499/564) |
| claude-3-haiku-20240307 | 3-Shot | 92.39% | 90% (272/303) | 91% (1267/1391) | 96% (550/570) |
| phi-2 | 6-Shot | 91.94% | 88% (267/302) | 94% (1299/1387) | 90% (510/569) |
| Qwen2-1.5B | 27-Shot | 86.10% | 90% (264/294) | 96% (1320/1382) | 61% (342/561) |
| **Qwen2-0.5B | 17-Shot | 79.48% | 69% (206/300) | 86% (1180/1380) | 71% (400/567) |
Here are the results from this notebook:
| Prompt | Strategy | Accuracy | Negative | Neutral | Positive |
|---|---|---|---|---|---|
| A | 0-Shot | 62.41% | 91% (276/303) | 53% (735/1391) | 71% (402/570) |
| B | 0-Shot | 47.84% | 90% (274/303) | 57% (789/1391) | 4% (20/570) |
| C | 0-Shot | 40.46% | 91% (276/303) | 43% (594/1391) | 8% (46/570) |
| D | 0-Shot | 68.29% | 79% (240/303) | 61% (851/1391) | 80% (455/570) |
| E | 0-Shot | 51.19% | 97% (293/303) | 28% (396/1391) | 82% (470/570) |
| F | 0-Shot | 48.19% | 94% (286/303) | 21% (287/1391) | 91% (518/570) |
| G | 0-Shot | 61.09% | 93% (282/303) | 46% (646/1391) | 80% (455/570) |
| H | 0-Shot | 65.42% | 85% (257/303) | 57% (798/1391) | 75% (426/570) |
| I | 0-Shot | 66.12% | 81% (245/303) | 58% (800/1391) | 79% (452/570) |
| J | 3-Shot | 70.94% | 43% (131/302) | 75% (1042/1390) | 76% (431/569) |
| K | 3-Shot | 74.88% | 67% (201/302) | 75% (1043/1390) | 79% (449/569) |
| L | 3-Shot | 68.11% | 49% (149/302) | 65% (900/1390) | 86% (491/569) |
| M | 3-Shot | 56.97% | 49% (149/302) | 45% (625/1390) | 90% (514/569) |
| N | 3-Shot | 73.95% | 62% (188/302) | 75% (1038/1390) | 78% (446/569) |
| O | 3-Shot | 59.97% | 65% (196/302) | 46% (635/1390) | 92% (525/569) |
| P | 6-Shot | 63.91% | 95% (289/303) | 49% (678/1389) | 84% (476/566) |
| Q | 6-Shot | 65.72% | 69% (207/302) | 55% (765/1389) | 90% (512/567) |
| R | 6-Shot | 64.84% | 94% (285/303) | 49% (686/1387) | 87% (493/568) |
| S | 6-Shot | 62.98% | 96% (292/303) | 47% (656/1387) | 83% (474/568) |
| T | 6-Shot | 68.87% | 51% (155/302) | 70% (966/1387) | 76% (434/569) |
| U | 12-Shot | 65.50% | 53% (159/302) | 59% (820/1386) | 88% (496/564) |
| V | 12-Shot | 73.22% | 70% (209/300) | 80% (1103/1386) | 60% (337/566) |
| W | 12-Shot | 70.43% | 82% (246/301) | 66% (912/1384) | 75% (428/567) |
| X | 12-Shot | 76.60% | 91% (270/298) | 72% (1000/1386) | 80% (455/568) |
| Y | 12-Shot | 72.56% | 80% (243/303) | 77% (1069/1381) | 57% (322/568) |
| Z | 18-Shot | 71.33% | 50% (150/301) | 75% (1036/1382) | 74% (416/563) |
| AA | 17-Shot | 79.48% | 69% (206/300) | 86% (1180/1380) | 71% (400/567) |
| AB | 18-Shot | 74.22% | 77% (229/299) | 76% (1054/1381) | 68% (384/566) |
| AC | 18-Shot | 68.57% | 49% (148/302) | 73% (1013/1380) | 67% (379/564) |
| AD | 18-Shot | 74.98% | 89% (271/303) | 76% (1052/1379) | 64% (361/564) |
| AE | 24-Shot | 74.91% | 61% (181/299) | 92% (1267/1375) | 41% (230/566) |
| AF | 24-Shot | 73.08% | 37% (112/302) | 91% (1246/1375) | 50% (279/563) |
| AG | 24-Shot | 75.00% | 58% (173/300) | 92% (1265/1375) | 43% (242/565) |
| AH | 24-Shot | 77.46% | 78% (233/299) | 84% (1153/1375) | 62% (349/566) |
| AI | 23-Shot | 75.37% | 48% (143/301) | 92% (1266/1375) | 50% (280/565) |
| AJ | 30-Shot | 77.39% | 58% (172/298) | 94% (1284/1370) | 48% (273/566) |
| AK | 30-Shot | 67.78% | 63% (187/299) | 61% (844/1375) | 86% (483/560) |
| AL | 30-Shot | 76.54% | 58% (173/299) | 86% (1185/1372) | 63% (352/563) |
| AM | 30-Shot | 74.84% | 82% (242/296) | 72% (984/1376) | 79% (446/562) |
| AN | 30-Shot | 73.81% | 51% (154/300) | 77% (1052/1372) | 79% (443/562) |
| AO | 45-Shot | 74.18% | 54% (159/297) | 76% (1034/1366) | 81% (453/556) |
| AP | 45-Shot | 78.73% | 63% (186/296) | 87% (1192/1365) | 66% (369/558) |
| AQ | 45-Shot | 72.01% | 17% (51/301) | 89% (1210/1359) | 60% (337/559) |
| AR | 45-Shot | 73.86% | 53% (157/297) | 80% (1094/1364) | 70% (388/558) |
| AS | 45-Shot | 74.94% | 42% (125/297) | 89% (1219/1363) | 57% (319/559) |
| AT | 60-Shot | 72.19% | 47% (138/292) | 78% (1055/1356) | 72% (398/556) |
| AU | 60-Shot | 76.86% | 43% (127/296) | 91% (1237/1356) | 60% (330/552) |
| AV | 60-Shot | 75.45% | 26% (79/299) | 89% (1206/1352) | 68% (378/553) |
| AW | 60-Shot | 74.46% | 29% (88/299) | 86% (1157/1349) | 71% (396/556) |
| AX | 60-Shot | 79.63% | 62% (179/290) | 94% (1275/1352) | 54% (301/562) |