Scoring Full Text and Semantic Search on Chunk Sizes from 100 to 2000 Tokens
python
RAG
information retrieval
fastbookRAG
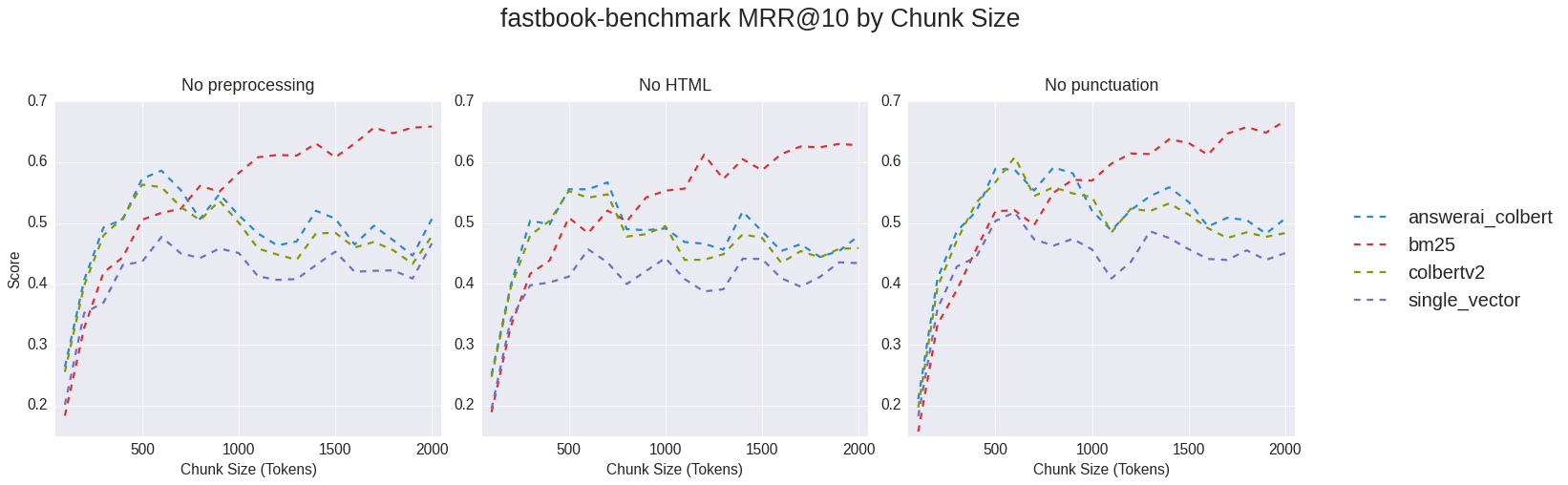
In this blog post, I run retrieval on three differently preprocessed datasets using four retrieval methods from chunk sizes 100 to 2000 tokens, using my fastbook-benchmark dataset to auto-score the results. Surprisingly, full text search yields the best MRR@10 (0.67) and Recall@10 (0.95) for a chunk size of 2000 tokens.
urls = {'01_intro.ipynb': 'https://drive.google.com/uc?export=view&id=1mmBjFH_plndPBC4iRZHChfMazgBxKK4_','02_production.ipynb': 'https://drive.google.com/uc?export=view&id=1Cf5QHthHy1z13H0iu3qrzAWgquCfqVHk','04_mnist_basics.ipynb': 'https://drive.google.com/uc?export=view&id=113909_BNulzyLIKUNJHdya0Hhoqie30I','08_collab.ipynb': 'https://drive.google.com/uc?export=view&id=1BtvStgFjUtvtqbSZNrL7Y2N-ey3seNZU','09_tabular.ipynb': 'https://drive.google.com/uc?export=view&id=1rHFvwl_l-AJLg_auPjBpNrOgG9HDnfqg','10_nlp.ipynb': 'https://drive.google.com/uc?export=view&id=1pg1pH7jMMElzrXS0kBBz14aAuDsi2DEP','13_convolutions.ipynb': 'https://drive.google.com/uc?export=view&id=19P-eEHpAO3WrOvdxgXckyhHhfv_R-hnS'}def download_file(url, filename):# Send a GET request to the URL response = requests.get(url)# Check if the request was successfulif response.status_code ==200:# Open the file in write-binary modewithopen(filename, 'wb') asfile:# Write the content of the response to the filefile.write(response.content)print(f"File downloaded successfully: {filename}")else:print(f"Failed to download file. Status code: {response.status_code}")for fname, url in urls.items(): download_file(url, fname)
def calculate_mrr(question, retrieved_passages, cutoff=10): retrieved_passages = retrieved_passages[:cutoff] highest_rank =0for ans_comp in question["answer_context"]: contexts = ans_comp.get("context", []) component_found =Falsefor rank, passage inenumerate(retrieved_passages, start=1):ifany(fix_text(context) in fix_text(passage) for context in contexts): highest_rank =max(highest_rank, rank) component_found =Truebreakifnot component_found:return0.0return1.0/highest_rank if highest_rank >0else0.0
calculate_recall function
def calculate_recall(question, retrieved_passages, cutoff=10): retrieved_passages = retrieved_passages[:cutoff]# Track if we've found at least one context for each answer component ans_comp_found = []for ans_comp in question["answer_context"]: contexts = ans_comp.get("context", []) found =False# Check if any context for this answer component appears in retrieved passagesfor passage in retrieved_passages:ifany(fix_text(context) in fix_text(passage) for context in contexts): found =Truebreak ans_comp_found.append(found)# Recall is ratio of answer components with at least one found contextreturnsum(ans_comp_found) /len(ans_comp_found)
load_data function
def load_data(chunks, db_path, chapter=1):try:# create virtual table if database doesn't existifnot os.path.exists(db_path):with sqlite3.connect(db_path) as conn: cur = conn.cursor() cur.execute(""" CREATE VIRTUAL TABLE fastbook_text USING FTS5(chapter, text); """) conn.commit()# load in the chunks for each chapterwith sqlite3.connect(db_path) as conn: cur = conn.cursor()for chunk in chunks: cur.execute("INSERT INTO fastbook_text(chapter, text) VALUES (?, ?)", (chapter, chunk)) conn.commit() res = cur.execute("SELECT * FROM fastbook_text WHERE chapter = ?", (chapter,)).fetchall()# make sure all the data was loaded into the databaseiflen(res) !=len(chunks):raiseValueError(f"Number of inserted chunks ({len(res)}) doesn't match input chunks ({len(chunks)})")returnTrueexcept sqlite3.Error as e:print(f"An error occurred: {e}")returnFalseexceptExceptionas e:print(f"An unexpected error occurred: {e}")returnFalse
db_search function
def db_search(df, limit=1): results = []with sqlite3.connect('fastbook.db') as conn: cur = conn.cursor()# concatenate the keywords into a string "keyword1 OR keyword 2 OR keyword3 ..."for _, row in df.iterrows(): keywords =' OR '.join([f'"{keyword.strip(",")}"'for keyword in row['keywords'].replace('"', '').split()]) q =f""" SELECT text, rank FROM fastbook_text WHERE fastbook_text MATCH ? AND chapter = ? ORDER BY rank LIMIT ? """ res = cur.execute(q, (keywords, str(row['chapter']), limit)).fetchall()# grab the retrieved chunk from the query results res = [item[0] for item in res]# if there are multiple chunks retrieved, combine them into a single string results.append(res)return results
fts_retrieval function
def fts_retrieval(data, df, chunk_size):if os.path.exists("fastbook.db"): os.remove("fastbook.db")for chapter, chunks in data.items(): documents = corpus_processor.process_corpus(chunks, chunk_size=chunk_size) documents = [doc['content'] for doc in documents]assert load_data(documents, 'fastbook.db', chapter) results = db_search(df, limit=10)assertlen(results) ==191for res in results:assertlen(res) <=10return results
single_vector_retrieval function
def single_vector_retrieval(data, benchmark, chunk_size):# Group questions by chapter questions = {}for q in benchmark["questions"]: chapter =str(q["chapter"])if chapter notin questions: questions[chapter] = [] questions[chapter].append(q['question_text'].strip('"\'')) q_embs = {}for chapter, _ in data.items(): qs = questions[chapter] q_embs[chapter] = emb_model.encode(qs, convert_to_tensor=True) results = []for chapter, chunks in data.items():# chunk chapter text documents = corpus_processor.process_corpus(chunks, chunk_size=chunk_size) documents = [doc['content'] for doc in documents]# Embed documents data_embs = emb_model.encode(documents, convert_to_tensor=True)# Compute cosine similarity and get top 10 indices for each row idxs = F.cosine_similarity(q_embs[chapter].unsqueeze(1), data_embs.unsqueeze(0), dim=2).sort(descending=True)[1] top_10_idxs = idxs[:, :10] # Get the top 10 indices for each row# Extract top 10 chunks for each row top_10_chunks = [ [documents[idx.item()] for idx in row_idxs]for row_idxs in top_10_idxs ] results.extend(top_10_chunks)assertlen(results) ==191for res in results:assertlen(res) <=10return results
index_free_retrieval function
def index_free_retrieval(data, model_nm, chunk_size, benchmark): questions_by_chapter = {}for q in benchmark["questions"]: chapter =str(q["chapter"])if chapter notin questions_by_chapter: questions_by_chapter[chapter] = [] questions_by_chapter[chapter].append(q)# Dictionary to store results per chapter chapter_results = {}# Process each chapter separatelyfor chapter in nbs.keys():# instantiate new RAG object RAG = RAGPretrainedModel.from_pretrained(model_nm)# Get questions for this chapter chapter_questions = questions_by_chapter[chapter]# encode chapter documents documents = corpus_processor.process_corpus(data[chapter], chunk_size=chunk_size) RAG.encode([x['content'] for x in documents], document_metadatas=[{"chapter": chapter} for _ inrange(len(documents))])# Perform retrieval for each question in this chapter results = []for q in chapter_questions: top_k =min(10, len(documents)) retrieved = RAG.search_encoded_docs(query = q["question_text"].strip('"\''), k=top_k) results.append(retrieved)# Store results chapter_results[chapter] = results results = []for chapter, res in chapter_results.items(): results.extend(res)assertlen(results) ==191 final_results = []for res in results:assertlen(res) <=10 intermediate_results = [r['content'] for r in res] final_results.append(intermediate_results)assertlen(final_results) ==191return final_results
def notebook_to_string(path):withopen(path, 'r', encoding='utf-8') as f: notebook = json.load(f) all_text ='' found_questionnaire =Falsefor cell in notebook['cells']:if cell['cell_type'] =='markdown'andany('## Questionnaire'in line for line in cell['source']): found_questionnaire =Truebreakif cell['cell_type'] in ['markdown', 'code']: all_text +=''.join(cell['source']) +'\n'return all_text
chunk_string function
def chunk_string(text, n):"""Split text into n chunks.""" skip =int(len(text) / n)return [text[i:i + skip] for i inrange(0, len(text), skip)]
def remove_punctuation(text):import stringreturn''.join(char if char.isalnum() else' 'if char in string.punctuation else char for char in text)
process_contexts function
def process_contexts(data):# Process questionsfor question in data['questions']:# Process only answer_contextif'answer_context'in question:for context_item in question['answer_context']:if'context'in context_item:ifisinstance(context_item['context'], list):# If context is a list, process each string in the list context_item['context'] = [ remove_punctuation(text) if text else textfor text in context_item['context'] ]elifisinstance(context_item['context'], str):# If context is a single string, process it directly context_item['context'] = remove_punctuation(context_item['context'])return data
Background
In this notebook, I evaluate four retrieval methods on my fastbook-benchmark dataset using various chunk sizes:
Full text search (using sqlite and Claude-generated keywords).
For each retrieval method, I’m looking to find the best MRR@10 and Recall@10 for three chunk size ranges:
Small: 100-500 tokens
Medium: 500-1000 tokens
Large: 1000+ tokens
I chose these ranges based on trends I saw during some experiments I ran with ColBERTv2 and answerai-colbert-small-v1 for a chunk size range of 100-3000 tokens.
I’m using corpus_processor.process_corpus for chunking.
Data Preprocessing
For each retrieval method/chunk size combination, I’ll preprocess my data three ways:
No preprocessing.
Remove HTML tags.
Remove punctuation.
Note that in each case, I am first converting the .ipynb for each chapter into a single string and splitting them into 2-3 chunks since for full-length texts were causing OOM during ColBERTv2 encoding.
Prep no preprocessing dataset
data_no_pp = {}n_chars =0for chapter, nb in nbs.items(): data_no_pp[chapter] = chunk_string(notebook_to_string(nb), 2)for c in data_no_pp[chapter]: n_chars +=len(c)assert n_chars ==503769
Prep no HTML dataset
data_no_html = {}n_chars =0for chapter, nb in nbs.items(): data_no_html[chapter] = chunk_string(notebook_to_string(nb), 2)for c in data_no_html[chapter]: n_chars +=len(c)assert n_chars ==503769n_chars =0for chapter, chunks in data_no_html.items(): data_no_html[chapter] = [clean_html(chunk) for chunk in chunks]for string in data_no_html[chapter]: n_chars +=len(string)assert n_chars ==493604
Prep no punctuation dataset
data_no_punc = {}n_chars =0for chapter, nb in nbs.items(): data_no_punc[chapter] = chunk_string(notebook_to_string(nb), 2)for c in data_no_punc[chapter]: n_chars +=len(c)assert n_chars ==503769n_chars =0for chapter, chunks in data_no_punc.items(): data_no_punc[chapter] = [remove_punctuation(chunk) for chunk in chunks]for string in data_no_punc[chapter]: n_chars +=len(string)# we are replacing punctuation with single space so n_chars doesn't changeassert n_chars ==503769
Surprisingly, full text search had the highest-overall MRR@10 with 0.67 for 2000-token chunks, for text with punctuation removed.
df[df['MRR@10'] == df['MRR@10'].max()]
data
method
chunk_size
MRR@10
Recall@10
19
no punctuation
bm25
2000
0.668046
0.94315
Best Overall Recall@10
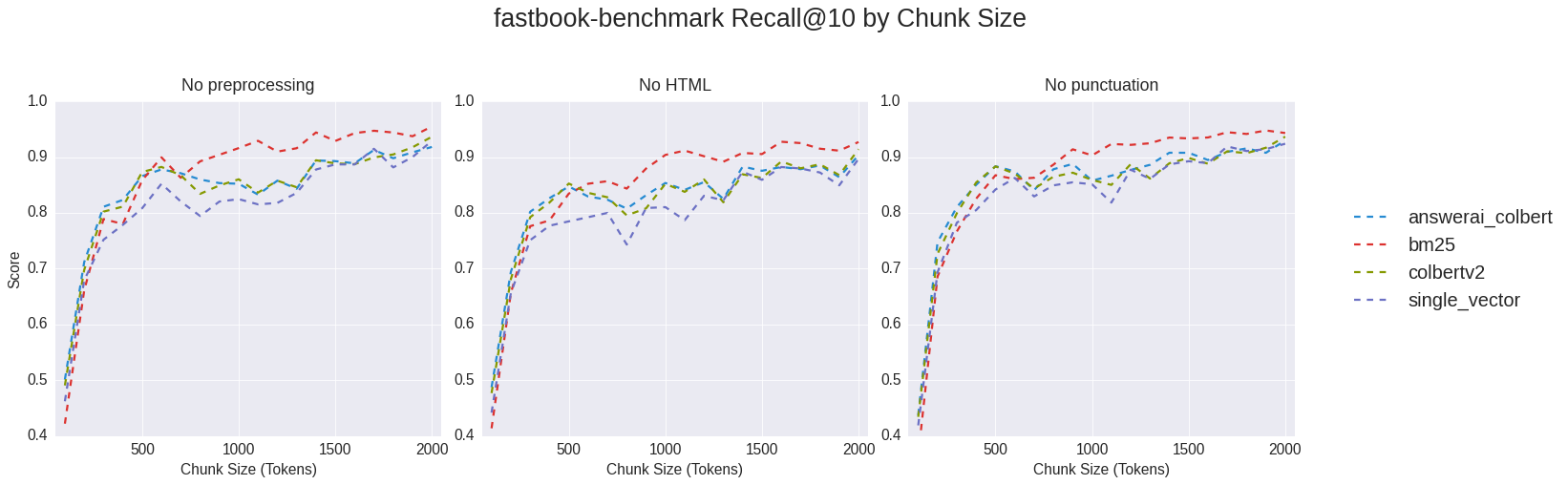
Full text search also yielded the best overall Recall@10 at 95%, also at a chunk size of 2000 tokens, but for text with no preprocessing on it (other than splitting the notebook into 2-3 chunks). Wow!
df[df['Recall@10'] == df['Recall@10'].max()]
data
method
chunk_size
MRR@10
Recall@10
19
no preprocessing
bm25
2000
0.658541
0.95493
Analyzing Metrics by Chunk Size Range
I care about chunk size because eventually I am going to pass on the retrieved context to an LLM for answer generation and context size will dictate latency and potentially performance.
All semantic search methods peak at a chunk size of ~500 tokens.
Full text search (BM25) mostly monotonically improves with chunk size.
Single-vector cosine simililarity is the worst-performing method after ~250 tokens.
For semantic search methods, in general, answerai-colbert-small-v1 > ColBERTv2 > Single-vector cosine similarity.
plot_metrics(df, metric="Recall@10")
Takeaways:
When the data is not preprocessed, all semantic search methods’ Recall@10 decreases from ~500 tokens to ~1000 tokens, then increase again to 2000 tokens.
After 500 tokens, full text search (BM25) has the best Recall@10 for most of the way.
Final Thoughts
This was an incredibly awesome experience. I did a couple iterations of these experiments before this notebook, each time refactoring my approach so that I could relatively concisely run these chunk size experiments. That process was tough at times but really rewarding.
My three main takeaways:
For small chunks, answerai-colbert-small-v1 has the best MRR@10 and Recall@10.
For medium chunks, use ColBERTv2 for the best MRR@10 and full text search for the best Recall@10.
For large chunks, full text search has the best MRR@10 and Recall@10.
I expect to try out all of these approaches after I integrate an LLM to turn this information retrieval pipeline to a RAG pipeline. My hypothesis is that smaller chunks will yield better responses from the LLM since there will be less “noise” and more “signal” in the context.