from transformers import AutoModelForCausalLM, AutoTokenizerLossInspector: A Deep Dive Into LLM-Foundry’s Next-Token Prediction with a Custom Composer Callback
python
deep learning
LLM
I’m working on a research project where we’re fine-tuning small models with various techniques and datasets using LLM-Foundry. As part of our infrastructure setup, I wanted to thoroughly understand how a batch of data is prepared, and how the outputs of a model, along with the labels, are passed to the loss function. Enter the custom Composer callback LossInspector!
Background
I’m working on a research project where we’ll be fine-tuning small models with various techniques and datasets using LLM-Foundry. As part of our infrastructure setup, we wanted to make sure that we thoroughly understood how a batch of data is prepared by LLM-Foundry, and how the outputs of a model, along with the labels, are passed to the loss function to calculate the loss. To do so, with the help of Claude, I wrote up a custom Composer Callback. This is the third custom callback I’ve written for Composer/LLM-Foundry, you can read more about my first and second callbacks.
I was initially going to have two or three callbacks: one to inspect inputs/outputs to the embedding, one to inspect the input/outputs to the model’s forward pass, and one to inspect the loss function. 27 commits later, I had a relatively lean single callback that gave me all the information I needed.
I focused on three events during Composer’s training loop:
before_loss: to store the “untouched” batch from Composer’sstate.before_forward: to store the untouchedinput_idsandlabelsfrom the state’s batch.after_loss: to both capture the calculated loss and “manually” calculate the loss using the model’s loss function.
Before we go further into detail, here’s the callback code (and necessary imports):
Here’s my video walkthrough of the code in this notebook:
LossInspector Callback
from composer.core.callback import Callback
from composer.core import State
from composer.loggers import Logger
import torch
class LossInspector(Callback):
def __init__(self):
super().__init__()
self.inspected = False
self.input_ids = None
self.labels = None
def before_loss(self, state: State, logger: Logger) -> None:
if self.inspected:
return
self.state_outputs = state.outputs
self.state_batch = state.batch
def before_forward(self, state: State, logger: Logger) -> None:
# check that input_ids and labels are the same as after loss
self.input_ids = state.batch['input_ids'][0].detach().cpu()
self.labels = state.batch['labels'][0].detach().cpu()
def after_loss(self, state: State, logger: Logger) -> None:
if self.inspected:
return
print("\n=== LOSS CALCULATION INSPECTION ===")
# Get the framework loss from state
framework_loss = state.loss.item()
print(f"Framework loss: {framework_loss:.6f}")
# Access model's loss_function directly
logits = self.state_outputs['logits']
labels = self.state_batch['labels']
vocab_size = state.model.model.config.vocab_size
direct_loss = state.model.model.loss_function(
logits=logits,
labels=labels,
vocab_size=vocab_size
)
print(f"Direct call to model.loss_function: {direct_loss.item():.6f}")
print("\n-------- input_ids --------")
input_ids = self.state_batch['input_ids'][0].detach().cpu()
print(input_ids.tolist())
decoded_input = state.model.tokenizer.decode(input_ids)
print(decoded_input[:1000])
print("\n-------- labels --------")
labels = self.state_batch['labels'][0].detach().cpu()
print(labels.tolist())
valid_labels = labels[labels != -100]
decoded_labels = state.model.tokenizer.decode(valid_labels)
print(decoded_labels)
print("\n-------- matches before_forward values? --------")
print(f"input_ids: {torch.allclose(input_ids, self.input_ids)}")
print(f"labels: {torch.allclose(labels, self.labels)}")
self.inspected = TrueThe callback is then appended to the callbacks list before passed to the Composer trainer.
SmolLM2-135M Loss Function
It was surprisingly difficult to inspect the loss function. Or rather my lack of Composer/HuggingFace internals knowledge immediately surfaced with this task! Looking through the Composer GitHub repo and documentation, I found the following references to the model’s loss function—all quite helpful but too general:
loss = model.loss(outputs, targets)for epoch in range(NUM_EPOCHS):
for inputs, targets in dataloader:
outputs = model.forward(inputs)
loss = model.loss(outputs, targets)
loss.backward()
optimizer.step()
optimizer.zero_grad()def loss(self, outputs, batch):
# pass batches and `forward` outputs to the loss
_, targets = batch
return F.cross_entropy(outputs, targets)I looked at their MixUp algorithm’s source code in hopes for more detail but found none—though it did help me confirm how batches are handled:
class MixUp(Algorithm):
def match(self, event: Event, state: State) -> bool:
"""Determines whether the algorithm should run on a given event."""
return event in [Event.AFTER_DATALOADER, Event.AFTER_LOSS]
def apply(self, event: Event, state: State, logger: Logger) -> None:
"""Run the algorithm by modifying the State."""
input, target = state.batch
if event == Event.AFTER_DATALOADER:
new_input, self.permuted_target, self.mixing = mixup_batch(input, target, alpha=0.2)
state.batch = (new_input, target)
if event == Event.AFTER_LOSS:
modified_batch = (input, self.permuted_target)
new_loss = state.model.loss(state.outputs, modified_batch)
state.loss *= (1 - self.mixing)
state.loss += self.mixing * new_lossLooking at Composer’s HuggingFaceModel did not give me the necessary detail, but provided the key for the next step: the loss was stored in outputs.
def loss(self, outputs, batch):
if self.config.use_return_dict:
return outputs['loss']
else:
# loss is at index 0 in the output tuple
return outputs[0]Did this mean that the loss function was tucked away in the forward pass? Let’s take a look.
model_name = "HuggingFaceTB/SmolLM2-135M"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)import inspectforward_method = inspect.getsource(model.forward)
print(forward_method)I won’t print out the whole forward method, but will highlight that tucked away in there was the loss function call!
loss = None
if labels is not None:
loss = self.loss_function(logits=logits, labels=labels, vocab_size=self.config.vocab_size, **kwargs)Aha! The function in question is loss_function. Inspecting that in more detail:
print(hasattr(model, 'loss_function'))TrueThis was a great opportunity for a refresher on the next-token objective and auto-regressive nature of this model.
print(inspect.getsource(model.loss_function))def ForCausalLMLoss(
logits,
labels,
vocab_size: int,
num_items_in_batch: Optional[int] = None,
ignore_index: int = -100,
shift_labels: Optional[torch.Tensor] = None,
**kwargs,
) -> torch.Tensor:
# Upcast to float if we need to compute the loss to avoid potential precision issues
logits = logits.float()
if shift_labels is None:
# Shift so that tokens < n predict n
labels = nn.functional.pad(labels, (0, 1), value=ignore_index)
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
logits = logits.view(-1, vocab_size)
shift_labels = shift_labels.view(-1)
# Enable model parallelism
shift_labels = shift_labels.to(logits.device)
loss = fixed_cross_entropy(logits, shift_labels, num_items_in_batch, ignore_index, **kwargs)
return loss
The key for understanding next-token prediction are the following lines:
if shift_labels is None:
# Shift so that tokens < n predict n
labels = nn.functional.pad(labels, (0, 1), value=ignore_index)
shift_labels = labels[..., 1:].contiguous()nn.functional.pad adds padding tokens to labels, specifically 0 to the left-most end of the last dimension and 1 padding token to the right-most end. The token it uses as padding is ignore_index, which is -100.
Next, it shifts the labels by 1 element to the left with labels[..., 1:]. I took a moment to realize what this meant: the input_ids and labels, in terms of position, are the same! To align the labels with the logits (which are already “shifted” in the sense that the first position in logits corresponds to the first predicted token: the second token in the context) we have to shift the labels by 1. To ensure that the final token in input_ids doesn’t predict anything, we pad labels with -100, the value ignored in the loss calculation.
As a reminder, if the context we’re training our model on is “the cat sat on the table”, each next token is predicted based on all previous tokens:
the --> cat
the cat --> sat
the cat sat --> on
the cat sat on --> the
the cat sat on the --> tableThis is a good time to return to our callback and analyze its output, but before I do, here’s a quick demo of the label shifting operation:
from torch.nn.functional import pad
from torch import tensorlabels = tensor([3, 6, 4, 2])
labelstensor([3, 6, 4, 2])pad(labels, (0,1), value=-100)tensor([ 3, 6, 4, 2, -100])pad(labels, (1,0), value=-100)tensor([-100, 3, 6, 4, 2])pad(labels, (1,1), value=-100)tensor([-100, 3, 6, 4, 2, -100])pad(labels, (0,1), value=-100)[...,1:]tensor([ 6, 4, 2, -100])Callback Logs
There were four key print statements of interest in my callback. I’ll display each and show their printed value:
print(f"Framework loss: {framework_loss:.6f}")
Framework loss: 1.067513print(f"Direct call to model.loss_function: {direct_loss.item():.6f}")
Direct call to model.loss_function: 1.067513print(input_ids.tolist())print(labels.tolist())
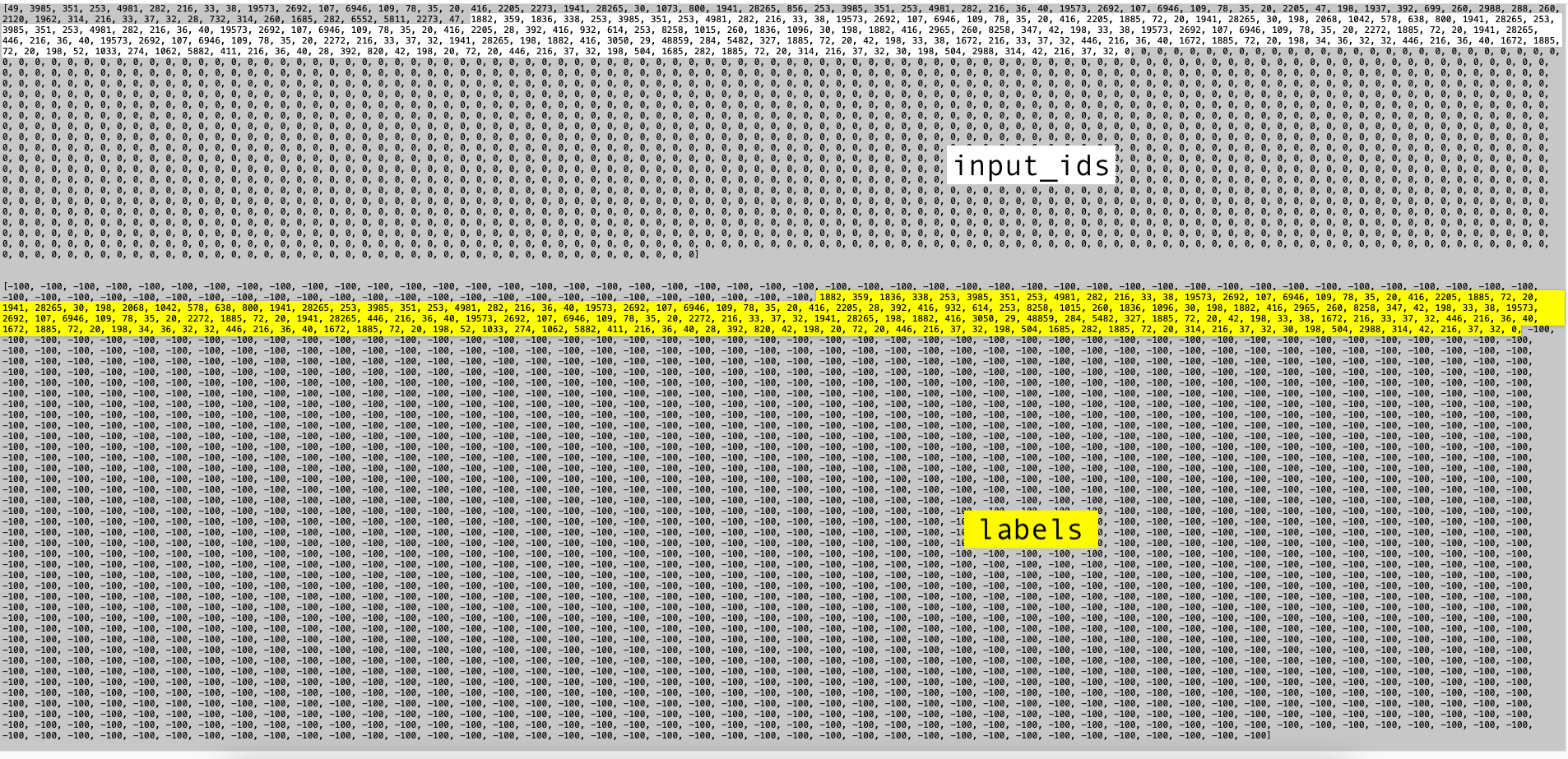
input_ids (top) and labels (bottom) with the response highlighted in yellowThe first two print statements confirmed that I was calling state.model.loss_function correctly. It also confirmed that the loss function doesn’t take in the input_ids.
The last two print statements confirmed my understanding: positionally speaking, the input_ids and labels are the same. In labels the positions of input_ids tokens that contain the prompt (and EOS tokens) are replaced with -100 and the tokens that represent the response are kept as is. For reference, here’s what input_ids looks like (both the prompt and the response) coming from an item of the MetaMathQA dataset (I have ommitted the hundreds of padding EOS tokens and formatted the text for clearer presentation):
A box with a volume of 16 $\text{cm}^3$ can hold X paperclips.
How many paperclips could a box with a volume of 48 $\text{cm}^3$ hold?
If we know the answer to the above question is 150, what is the value of unknown variable X?
We are given that a box with a volume of 16 $\text{cm}^3$ can hold $X$ paperclips.
To find out how many paperclips a box with a volume of 48 $\text{cm}^3$ can hold, we can set up a proportion using the given information.
We can write the proportion as:
16 $\text{cm}^3$ / $X$ paperclips = 48 $\text{cm}^3$ / 150 paperclips
We can cross-multiply and solve for $X$:
16 * 150 = 48 * $X$
2400 = 48 * $X$
Dividing both sides by 48, we get:
$X$ = 50
The value of $X$ is 50.
The answer is: 50<|endoftext|>labels has the prompt replaced with -100s, and the loss function then left-shifts the labels tokens by 1 spot to align with the logits for next-token prediction comparison.
Unsurprisingly, the input_ids and labels before the forward pass and after the loss calculation are the same:
print("\n-------- matches before_forward values? --------")
print(f"input_ids: {torch.allclose(input_ids, self.input_ids)}")
print(f"labels: {torch.allclose(labels, self.labels)}")-------- matches before_forward values? --------
input_ids: True
labels: TrueFinal Thoughts
With this baseline established, I can use this callback everytime we have processed a new dataset for training, inspecting the tokens, decoded text and loss values to ensure that the training loop will run properly for next-token prediction, whether it’s a continued pretraining or instruction fine-tuning dataset! Working with LLM-Foundry is a steep learning curve but I am learning a TON.