DataInspector with BinPackCollator: Inspecting Packed Dataloader Items
BinPackCollator and write a custom Composer callback to inspect the data and confirm that multiple sequences are packed in each batch item, leading to using 95% loss-generating tokens instead of 5%!
Background
I recently learned (via a desperation google search “llm foundry sequence packing”) that LLM-Foundry has a built-in sequence packer called BinPackCollator. To use it, you simply set two values in the training YAML: train_loader.name=finetuning and train_loader.dataset.packing_ratio to auto or a number greater than 1.0. I haven’t fully/thoroughly understood/traced how BinPackCollator is activated, but here’s what I have found:
build_collate_fnuses thepacking_ratioconfig value. Ifpacking_ratiois1.0it returns theSeq2SeqFinetuningCollator. If it’sauto, it calls the functionauto_packing_ratiowhich profiles the dataset to determine the optimalpacking_ratio(apacking_ratiowith zero waste). Ifpacking_ratiois greater than1.0, it then instantiatesBinPackCollatoras thecollate_fn.build_finetuning_dataloaderconstructs thecollate_fnfromregistry.collators(tbh, I haven’t yet grasped the concept of registry and how it works in LLM-Foundry, on my to-do list).- The main training script, command_utils/train.py uses
build_dataloaderwhich takes the training loader config and uses thenameattribute in the config (which isfinetuningin our case) toconstruct_from_registrywhich I do not understand how it works yet.
Here’s an example YAML snippet which shows the necessary attributes (name and packing_ratio) to utilize BinPackCollator:
train_loader:
name: finetuning
dataset:
streams:
my_data:
local: ${variables.data_local}
remote: ${variables.data_remote}
split: train
shuffle: true
max_seq_len: ${variables.max_seq_len}
shuffle_seed: ${variables.global_seed}
decoder_only_format: true
packing_ratio: 5.0In this blog post, I’m going to share a custom Composer callback I wrote to inspect data during training and ensure that sequences are being packed!
DataInspector
I’ll start by sharing the full code for my callback:
class DataInspector(Callback):
def __init__(self, save_path="/model-checkpoints/binpackcollator"):
self.save_path = Path(save_path)
self.log = {'log': {}}
def after_dataloader(self, state: State, logger: Logger) -> None:
self._log(
state,
"after_dataloader",
str(state.timestamp.batch.value),
[
('collate_fn', str(state.dataloader.collate_fn.base_collator)),
('input_ids_shape', str(state.batch['input_ids'].shape)),
('total_tokens', str(state.batch['input_ids'].shape[1])),
('decoded_tokens', str(state.model.tokenizer.decode(state.batch['input_ids'][0]))),
('padding_tokens', str(len([o for o in list(state.batch['input_ids'][0]) if o.item() == 0]))),
('non_padding_tokens', str(len([o for o in list(state.batch['input_ids'][0]) if o.item() != 0]))),
('input_ids[0]', str(list(state.batch['input_ids'][0]))),
])
def _log(self, state: State, event_name: str, batch_num: str, values: list[str]) -> None:
for label, value in values: self.log["log"][f"{event_name}_{batch_num}_{label}"] = value
self._save()
def _save(self) -> None:
os.makedirs(self.save_path, exist_ok=True)
log_file = self.save_path / "datainspector_logs.json"
with open(log_file, 'w') as f:
json.dump(self.log, f, indent=2)I started testing the callback by writing a very basic version first:
class DataInspector(Callback):
def __init__(self, save_path="/model-checkpoints/binpackcollator"):
self.save_path = Path(save_path)
self.log = {'log': {}}
def after_dataloader(self, state: State, logger: Logger) -> None:
self._log(state, "after_dataloader", "some value")
def _log(self, state: State, event_name: str, value: str) -> None:
self.log["log"][f"{event_name}"] = value
self._save()
def _save(self) -> None:
os.makedirs(self.save_path, exist_ok=True)
log_file = self.save_path / "datainspector_logs.json"
with open(log_file, 'w') as f:
json.dump(self.log, f, indent=2)The __init__ and _save methods are pretty straigtforward, as they instantiate the save_path and log and then save to the log at that save_path. I could have chosen any number of events to trigger logging, but I chose after_loader since I wanted to inspect the data after the dataloader was constructed. The _log basically takes in as input the strings you want to save in the self.log dictionary. Once this initial functionality was working, I added different items for logging one at a time, starting with input_ids, non_padding_tokens and padding_tokens (which are counts of tokens), inspecting the logs visually before I moved on to the next item. Along the way I learned that the dataloader’s collate_fn was LossGeneratingTokensCollatorWrapper and that its base_collator function was BinPackCollator.
Here’s a snippet of the log:
"log": {
"after_dataloader_0_collate_fn": "<llmfoundry.data.packing.BinPackCollator object at 0x2ad36237cc20>",
"after_dataloader_0_input_ids_shape": "torch.Size([4, 2048])",
"after_dataloader_0_total_tokens": "2048",
"after_dataloader_0_padding_tokens": "102",
"after_dataloader_0_non_padding_tokens": "1946",
...Here are screenshots of the actual log, first without using BinPackCollator:
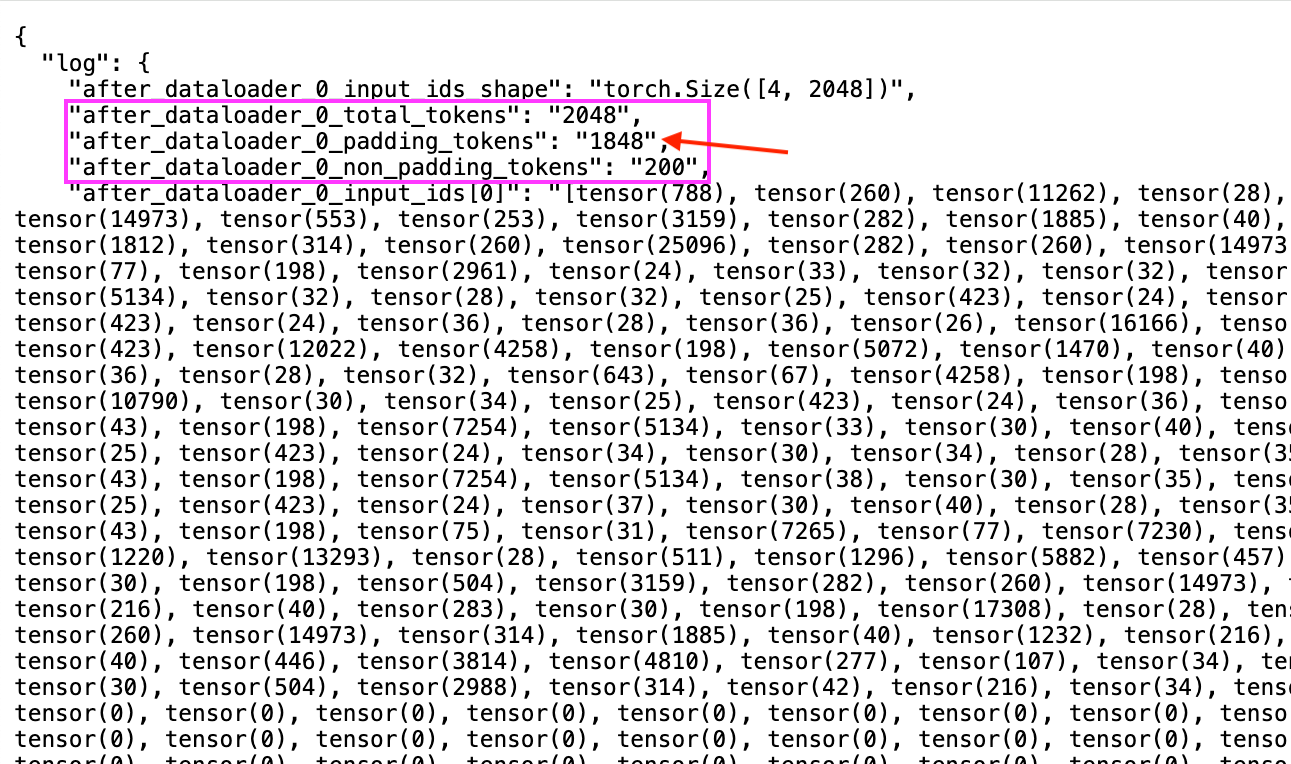
BinPackCollator. Note that the number of padding tokens represent ~90% of the max sequence length of 2048And with using BinPackCollator:
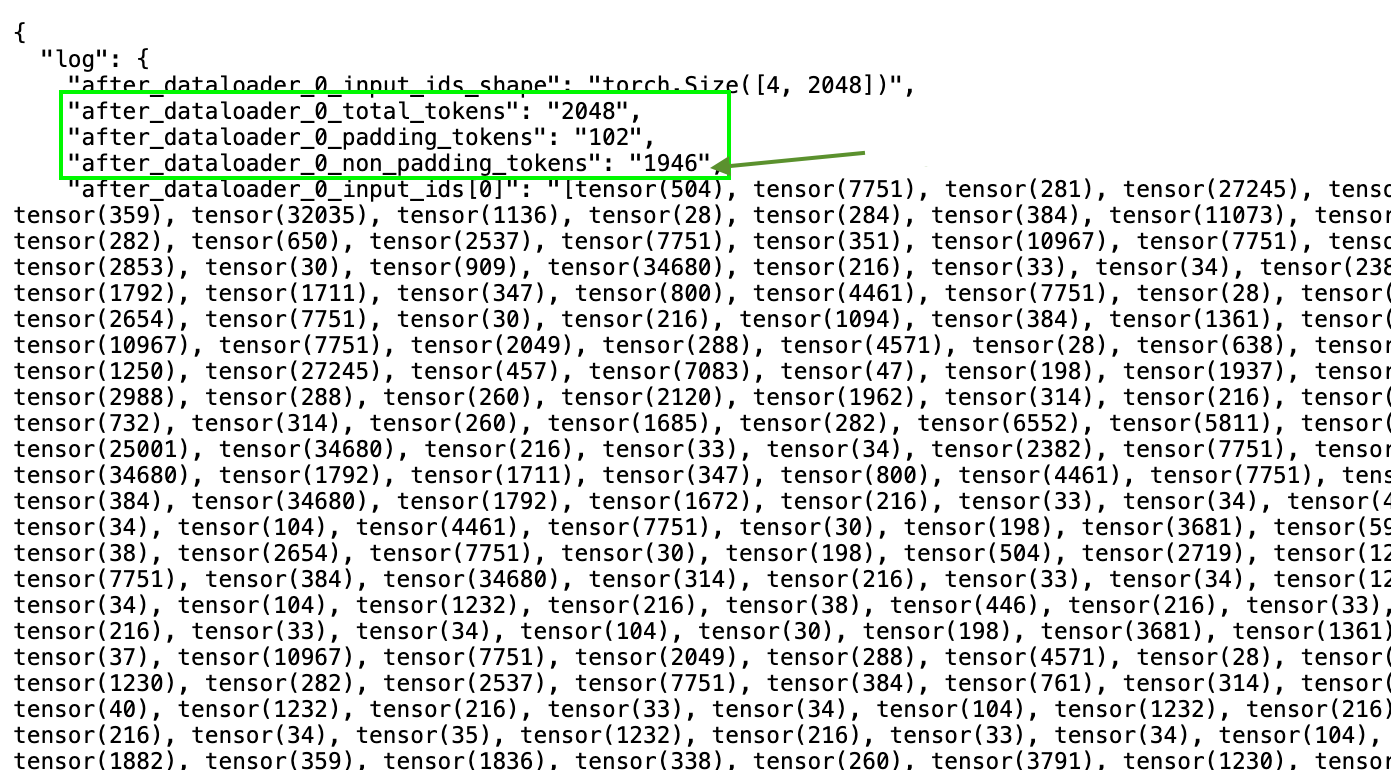
BinPackCollator. Now the non-padding token represent 90% of the sequence lengthUsing BinPackCollator, we are now using more than 90% of the maximum sequence length with loss generating tokens!
Closing Thoughts
This is the fourth or fifth custom Composer callback I’ve written and I am really enjoyin writing and using them! The callback system makes it so easy to “look at your data”, and visually inspect and confirm that the model and/or data artifacts are correct. Expect more blog posts around Composer callbacks.
