!pip install -qq -U flash-attn --no-build-isolationHuggingFace’s Default KV Cache and the flash_attn_varlen_func Docstring
python
deep learning
Flash Attention
A deep dive into understanding
flash_attn_varlen_func’s docstring’s causal masks (for seqlen_q != seqlen_k) by exploring Hugging Face’s KV Cache (DynamicCache) in model.generate() with hands-on Q/K shape inspection. Unravels “bottom-right alignment” and why flash_attn_func gets called.
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
import torch
import torch.nn as nntokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM2-135M")
model = AutoModelForCausalLM.from_pretrained("HuggingFaceTB/SmolLM2-135M", attn_implementation="flash_attention_2", torch_dtype=torch.bfloat16).to("cuda")Background
I have recently been working on a research project which has required me to better understand sequence packing and Flash Attention, and eager attention as well. However, I’ve found that both in terms of my interest, and for practical understanding, that hasn’t been enough!
Tangentially, I also recently started using Gemini Pro 2.5 (the chat UI) and have been thoroughly enjoying it after using a year of daily use of Claude Pro. This seemed like a great opportunity to test out Gemini’s functionality to learn about a topic that is complex and currently outside of my comfort zone.
I fed Gemini the Flash Attention GitHub repo and explained that I wanted to thoroughly understand flash_attn_varlen_func to the point where I could make a detailed video walkthrough with visuals. It provided me with this condensed timeline:
- Phase 1: Python Layer & Sequence Packing Concepts
- Tasks: Understand
flash_attn_varlen_func’s Python call stack, the role ofcu_seqlens,max_seqlen, andtorch.autograd.Function. - Time: 1-2 Weeks
- Hours: Approximately 15-30 hours
- Tasks: Understand
- Phase 2: Core CUDA Kernel Deep Dive
- Tasks: Study the FlashAttention research paper(s).
- Analyze the C++/CUDA dispatcher code (e.g., in
csrc/flash_attn/flash_api.cpp). - Dissect the core CUDA kernels for variable length forward and backward passes (e.g., in
csrc/flash_attn/src/likeflash_fwd_kernel.handflash_bwd_kernel.h). - Time: 6-12 Weeks
- Hours: Approximately 125-240 hours
- Phase 3: Content Creation (Video/Blog)
- Tasks: Plan the structure for your content, create visuals, draft explanations, and prepare code snippets.
- Time: 2-3 Weeks
- Hours: Approximately 30-50 hours
- Total Estimated for CUDA Path
- Overall Timeline: Roughly 2.5 - 4.5 months
- Total Focused Hours: Approximately 170 - 320 hours
This is obviously an amibitious goal and timeline, especially because of my limited C++/CUDA knowledge and experience. However, I do believe this is a case of aim-for-the-stars-land-on-the-moon, as I’ve already experienced growth and learning in the first steps of Phase 1.
As I was reading through flash_attn_varlen_func source code, I got stuck on the following piece of the docstring:
If causal=True, the causal mask is aligned to the bottom right corner of the attention matrix.
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 = masked out) is:
1 1 1 1 0
1 1 1 1 1
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
0 0
0 0
0 0
1 0
1 1
If the row of the mask is all zero, the output will be zero.I didn’t have hands-on experience working with this concept, where the query length is different than the key and value length. Gemini helped me realize that this happens in the extremely common case of autoregressive generation—the next token (query length of 1) attends to the previous tokens (key/value length > 1). The concept of KV cache also came up in our conversation.
I don’t tend to understand things until I see them in code, so in this notebook, I’ll inspect the shapes of Q, K and V during the HuggingFace model.generate call. I’ll also peel back a couple layers and understand how HugginFace uses KV cache. After that exploration, I’ll return back to the flash_attn_varlen_func docstring and walk through the logic behind how the causal mask is shaped.
Understanding HuggingFace’s Default KV Cache
I’ll start by understanding how HuggingFace uses KV cache (I was surprised to find that it uses it by default!).
Inspecting model_kwargs for Caching Method
Looking at the generate source code, the first method call of interest when it comes to KV cache seems to be _prepare_cache_for_generation, which takes the following arguments: generation_config, model_kwargs, assistant_model, batch_size, max_cache_length, device. Going down the different elif statements, _prepare_cache_for_generation sets the following model_kwargs value:
model_kwargs[cache_name] = (
DynamicCache()
if not requires_cross_attention_cache
else EncoderDecoderCache(DynamicCache(), DynamicCache())
)Where cache_name is defined earlier in that method as:
cache_name = "past_key_values" if not is_hybrid_cache else "cache_params"I want to inspect what model_kwargs['past_key_values'] is.
_prepare_generation_config is used in generate to produce generation_config and model_kwargs.
generation_config, model_kwargs = model._prepare_generation_config(None)
generation_config, model_kwargs(GenerationConfig {
"bos_token_id": 0,
"eos_token_id": 0
},
{})I can now pass those on to _prepare_cache_for_generation, which will internally modify model_kwargs.
model._prepare_cache_for_generation(generation_config, model_kwargs, None, 1, 8192, "cuda")model_kwargs{'past_key_values': <transformers.cache_utils.DynamicCache at 0x78c3b80d9850>}I can see now that model_kwargs has a 'past_key_values' key which has a DynamicCache value.
How is past_key_values Used?
I think it makes sense to start by looking at the forward pass of the LlamaAttention module:
...
key_states = self.k_proj(hidden_states).view(hidden_shape).transpose(1, 2)
value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
...
if past_key_value is not None:
key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)The hidden_states pass through k_proj and v_proj to produce key_states and value_states, respectively, which are then passed to past_key_value.update to produce a new set of key_states and value_states. Looking at DynamicCache.update:
# Update the cache
if key_states is not None:
if len(self.key_cache) <= layer_idx:
# There may be skipped layers, fill them with empty lists
for _ in range(len(self.key_cache), layer_idx):
self.key_cache.append(torch.tensor([]))
self.value_cache.append(torch.tensor([]))
self.key_cache.append(key_states)
self.value_cache.append(value_states)
elif (
not self.key_cache[layer_idx].numel() # prefers not t.numel() to len(t) == 0 to export the model
): # fills previously skipped layers; checking for tensor causes errors
self.key_cache[layer_idx] = key_states
self.value_cache[layer_idx] = value_states
else:
self.key_cache[layer_idx] = torch.cat([self.key_cache[layer_idx], key_states], dim=-2)
self.value_cache[layer_idx] = torch.cat([self.value_cache[layer_idx], value_states], dim=-2)
return self.key_cache[layer_idx], self.value_cache[layer_idx]Let’s walk through each condition in the if-else block.
if len(self.key_cache) <= layer_idx
A full key_cache is has n_layers number of elements. If its number of elements is less than or equal to the layer_idx that means that it does not contain key_states for that layer_idx yet (because python starts count from 0). For example suppose layer_idx is 0, our first layer. if len(self.key_cache) <= layer_idx is True, that means len(self.key_cache) is 0 and doesn’t contain key_states for the first layer, as would be the case if you were generating the first token of a response. In this case you simply append the key_states to the cache.
If layer_idx is greater than len(self.key_cache) then it appends an empty tensor for the “skipped” layers. This would be a scenario where you were generating the first token of a response (len(self.key_cache) is 0) but starting with layer_idx of 2.
elif not self.key_cache[layer_idx].numel()
If a layer was skipped and it has an empty tensor as its key_cache then this condition is triggered and it simply assigned key_states to that layer’s key_cache.
else
I think this is the most common case, used for autoregressive next-token generation. The key_cache contains a non-empty value for this layer so it concatenates the current value with the new key_states. In this way, the key_cache for this layer grows over the course of next token generation. Specifically, it’s second to last dimension (sequence length) increases by 1 for each token processed.
return self.key_cache[layer_idx], self.value_cache[layer_idx]
Finally, the concatenated key_cache and value_cache for the given layer are returned. The update step is complete.
key_states and value_states after the past_key_values.update step are passed onto the attention_interface which we’ll look at later in this blog post.
attn_output, attn_weights = attention_interface(
self,
query_states,
key_states,
value_states,
attention_mask,
dropout=0.0 if not self.training else self.attention_dropout,
scaling=self.scaling,
**kwargs,
)Visualizing the DynamicCache.update
To see how the cache update takes place during autoregressive language generation, I’ll monkey-patch a debug_update method.
Show `debug_update
from typing import Any, Dict, Iterable, List, Optional, Tuple, Union
def debug_update(
self,
key_states: torch.Tensor,
value_states: torch.Tensor,
layer_idx: int,
cache_kwargs: Optional[Dict[str, Any]] = None,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Updates the cache with the new `key_states` and `value_states` for the layer `layer_idx`.
Parameters:
key_states (`torch.Tensor`):
The new key states to cache.
value_states (`torch.Tensor`):
The new value states to cache.
layer_idx (`int`):
The index of the layer to cache the states for.
cache_kwargs (`Dict[str, Any]`, `optional`):
Additional arguments for the cache subclass. No additional arguments are used in `DynamicCache`.
Return:
A tuple containing the updated key and value states.
"""
# Update the number of seen tokens
if layer_idx == 0:
self._seen_tokens += key_states.shape[-2]
# Update the cache
if key_states is not None:
if len(self.key_cache) <= layer_idx:
print(f"DEBUG: initializing cache for layer_idx {layer_idx}")
for _ in range(len(self.key_cache), layer_idx):
self.key_cache.append(torch.tensor([]))
self.value_cache.append(torch.tensor([]))
self.key_cache.append(key_states)
self.value_cache.append(value_states)
elif (
not self.key_cache[layer_idx].numel() # prefers not t.numel() to len(t) == 0 to export the model
): # fills previously skipped layers; checking for tensor causes errors
print(f"DEBUG: filling empty cache for layer_idx {layer_idx}")
self.key_cache[layer_idx] = key_states
self.value_cache[layer_idx] = value_states
else:
print(f"DEBUG: updating/concatenating cache for layer_idx {layer_idx}")
self.key_cache[layer_idx] = torch.cat([self.key_cache[layer_idx], key_states], dim=-2)
self.value_cache[layer_idx] = torch.cat([self.value_cache[layer_idx], value_states], dim=-2)
return self.key_cache[layer_idx], self.value_cache[layer_idx]from transformers.cache_utils import DynamicCache
if 'ORIGINAL_DYNAMIC_CACHE_UPDATE' not in globals():
ORIGINAL_DYNAMIC_CACHE_UPDATE = DynamicCache.update
print("Stored original DynamicCache.update.")
DynamicCache.update = debug_updateprompt = "The quick brown"
input_ids, attention_mask = tokenizer(prompt, return_tensors="pt").to("cuda").values()
outputs = model.generate(input_ids, pad_token_id=tokenizer.eos_token_id, do_sample=False, return_dict_in_generate=True, max_new_tokens=2)DEBUG: initializing cache for layer_idx 0
DEBUG: initializing cache for layer_idx 1
DEBUG: initializing cache for layer_idx 2
DEBUG: initializing cache for layer_idx 3
DEBUG: initializing cache for layer_idx 4
DEBUG: initializing cache for layer_idx 5
DEBUG: initializing cache for layer_idx 6
DEBUG: initializing cache for layer_idx 7
DEBUG: initializing cache for layer_idx 8
DEBUG: initializing cache for layer_idx 9
DEBUG: initializing cache for layer_idx 10
DEBUG: initializing cache for layer_idx 11
DEBUG: initializing cache for layer_idx 12
DEBUG: initializing cache for layer_idx 13
DEBUG: initializing cache for layer_idx 14
DEBUG: initializing cache for layer_idx 15
DEBUG: initializing cache for layer_idx 16
DEBUG: initializing cache for layer_idx 17
DEBUG: initializing cache for layer_idx 18
DEBUG: initializing cache for layer_idx 19
DEBUG: initializing cache for layer_idx 20
DEBUG: initializing cache for layer_idx 21
DEBUG: initializing cache for layer_idx 22
DEBUG: initializing cache for layer_idx 23
DEBUG: initializing cache for layer_idx 24
DEBUG: initializing cache for layer_idx 25
DEBUG: initializing cache for layer_idx 26
DEBUG: initializing cache for layer_idx 27
DEBUG: initializing cache for layer_idx 28
DEBUG: initializing cache for layer_idx 29
DEBUG: updating/concatenating cache for layer_idx 0
DEBUG: updating/concatenating cache for layer_idx 1
DEBUG: updating/concatenating cache for layer_idx 2
DEBUG: updating/concatenating cache for layer_idx 3
DEBUG: updating/concatenating cache for layer_idx 4
DEBUG: updating/concatenating cache for layer_idx 5
DEBUG: updating/concatenating cache for layer_idx 6
DEBUG: updating/concatenating cache for layer_idx 7
DEBUG: updating/concatenating cache for layer_idx 8
DEBUG: updating/concatenating cache for layer_idx 9
DEBUG: updating/concatenating cache for layer_idx 10
DEBUG: updating/concatenating cache for layer_idx 11
DEBUG: updating/concatenating cache for layer_idx 12
DEBUG: updating/concatenating cache for layer_idx 13
DEBUG: updating/concatenating cache for layer_idx 14
DEBUG: updating/concatenating cache for layer_idx 15
DEBUG: updating/concatenating cache for layer_idx 16
DEBUG: updating/concatenating cache for layer_idx 17
DEBUG: updating/concatenating cache for layer_idx 18
DEBUG: updating/concatenating cache for layer_idx 19
DEBUG: updating/concatenating cache for layer_idx 20
DEBUG: updating/concatenating cache for layer_idx 21
DEBUG: updating/concatenating cache for layer_idx 22
DEBUG: updating/concatenating cache for layer_idx 23
DEBUG: updating/concatenating cache for layer_idx 24
DEBUG: updating/concatenating cache for layer_idx 25
DEBUG: updating/concatenating cache for layer_idx 26
DEBUG: updating/concatenating cache for layer_idx 27
DEBUG: updating/concatenating cache for layer_idx 28
DEBUG: updating/concatenating cache for layer_idx 29As we can see by the printed output, for the first generated token update initializes cache with self.key_cache.append(key_states) and self.value_cache.append(value_states). For the subsequent tokens, it updates the cache with torch.cat.
I’ll re-assign the original update to DynamicCache to avoid cluttering with print outs.
DynamicCache.update = ORIGINAL_DYNAMIC_CACHE_UPDATEInspecting past_key_values During model.generate
With an understanding of how KV cache is updated, I’ll now turn my attention to the key and value cache contents during autoregressive generation.
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM2-135M")
model = AutoModelForCausalLM.from_pretrained("HuggingFaceTB/SmolLM2-135M", attn_implementation="flash_attention_2", torch_dtype=torch.bfloat16).to("cuda")prompt = "The quick brown"
prompt'The quick brown'input_ids, attention_mask = tokenizer(prompt, return_tensors="pt").to("cuda").values()
input_ids.shape, attention_mask.shape(torch.Size([1, 3]), torch.Size([1, 3]))By setting return_dict_in_generate=True we can retrieve past_key_values.
outputs = model.generate(input_ids, pad_token_id=tokenizer.eos_token_id, do_sample=False, return_dict_in_generate=True, max_new_tokens=5)
outputsGenerateDecoderOnlyOutput(sequences=tensor([[ 504, 2365, 6354, 16438, 27003, 690, 260, 23790]],
device='cuda:0'), scores=None, logits=None, attentions=None, hidden_states=None, past_key_values=<transformers.cache_utils.DynamicCache object at 0x78c4f80c4f50>)tokenizer.decode(outputs.sequences[0])'The quick brown fox jumps over the lazy'We have 8 total tokens—3 from the original prompt and 5 new tokens generated.
outputs.sequences.shapetorch.Size([1, 8])Inspecting the values in the KV cache: there are 30 items in key_cache and value_cache, corresponding to the 30 layers in the model. For the last generated token (the 8th token) there were 7 seen_tokens.
len(outputs.past_key_values.key_cache), len(outputs.past_key_values.value_cache)(30, 30)outputs.past_key_values.seen_tokens7The key_cache tensors all have the same shape: batch size, num_heads, seen_tokens, head_dim.
for k in outputs.past_key_values.key_cache: print(k.shape)torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])model.config.num_attention_heads, \
model.config.num_hidden_layers, \
model.config.num_key_value_heads(9, 30, 3)model.model.layers[0].self_attn.k_proj.out_features1923*64192The value_cache is similarly structured.
for v in outputs.past_key_values.value_cache: print(v.shape)torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 7, 64])init_k = outputs.past_key_values.key_cache[0]
init_k.shapetorch.Size([1, 3, 7, 64])While the shapes of the key_cache tensors across layers are the same, their contents are not. This is because each layer has its own self attention module with its own k_proj and v_proj layers with their own learned weights.
for k in outputs.past_key_values.key_cache[1:]: assert torch.allclose(init_k, k)--------------------------------------------------------------------------- AssertionError Traceback (most recent call last) <ipython-input-76-f08f1c95a8ee> in <cell line: 0>() ----> 1 for k in outputs.past_key_values.key_cache[1:]: assert torch.allclose(init_k, k) AssertionError:
Inspecting Intermediate Key/Value Cache Tensors During Generation
Now to understand how KV cache is used during generation: I want to inspect the shape of the key and value cache tensors as the prompt increases by one token at a time.
To achieve this, I’ll add a hook to the first layer’s self attention module’s forward pass using register_forward_hook. I came to an incorrect conclusion in a previous video and blog post that you can’t use register_forward_hook for the Llama attention module because it doesn’t capture keyword arguments. What I didn’t realize is that you can capture kwargs with register_forward_hook by setting with_kwargs=True, which I have done below.
I wrapped hook_fn in create_hook_fn because I wanted to print out the count of total generated tokens.
def create_hook_fn():
count = 1
def hook_fn(module, args, kwargs, output):
nonlocal count
print(count, kwargs['past_key_value'].key_cache[0].shape)
count += 1
return hook_fn
_hook_fn = create_hook_fn()
attn_layer = model.model.layers[0].self_attn
hook_handle = attn_layer.register_forward_hook(_hook_fn, with_kwargs=True)
outputs = model.generate(input_ids, pad_token_id=tokenizer.eos_token_id, do_sample=False, return_dict_in_generate=True, max_new_tokens=5)
hook_handle.remove()1 torch.Size([1, 3, 3, 64])
2 torch.Size([1, 3, 4, 64])
3 torch.Size([1, 3, 5, 64])
4 torch.Size([1, 3, 6, 64])
5 torch.Size([1, 3, 7, 64])Let’s parse this output:
- The first new token generated sees only the 3 tokens in the prompt. The KV cache subsequently has a third dimension of
3. - Each new token generated sees one more new token, so the third dimension (seen tokens) of
key_cacheandvalue_cacheincreases by1
I’ll slightly modify hook_fn so it prints out the first few shapes of key_cache, allowing us to see what all layers’ cache is storing from the perspective of layer_idx=0.
def create_hook_fn():
count = 1
def hook_fn(module, args, kwargs, output):
nonlocal count
print(count)
for k in kwargs['past_key_value'].key_cache[:5]: print(k.shape)
count += 1
return hook_fn
_hook_fn = create_hook_fn()
attn_layer = model.model.layers[0].self_attn
hook_handle = attn_layer.register_forward_hook(_hook_fn, with_kwargs=True)
outputs = model.generate(input_ids, pad_token_id=tokenizer.eos_token_id, do_sample=False, return_dict_in_generate=True, max_new_tokens=5)
hook_handle.remove()1
torch.Size([1, 3, 3, 64])
2
torch.Size([1, 3, 4, 64])
torch.Size([1, 3, 3, 64])
torch.Size([1, 3, 3, 64])
torch.Size([1, 3, 3, 64])
torch.Size([1, 3, 3, 64])
3
torch.Size([1, 3, 5, 64])
torch.Size([1, 3, 4, 64])
torch.Size([1, 3, 4, 64])
torch.Size([1, 3, 4, 64])
torch.Size([1, 3, 4, 64])
4
torch.Size([1, 3, 6, 64])
torch.Size([1, 3, 5, 64])
torch.Size([1, 3, 5, 64])
torch.Size([1, 3, 5, 64])
torch.Size([1, 3, 5, 64])
5
torch.Size([1, 3, 7, 64])
torch.Size([1, 3, 6, 64])
torch.Size([1, 3, 6, 64])
torch.Size([1, 3, 6, 64])
torch.Size([1, 3, 6, 64])Since we are capturing the key_cache shapes from the first layer (layer_idx=0), the other subsequent layer’s cache tensors are 1 token “behind”, since the new token’s hidden states have not passed through the model yet.
Ultimately, I want to tie this all back to the flash_attn_varlen_func’s dostring’s causal mask example, so I’ll take a look at the query_states shape, copying code from the LlamaAttention forward pass. I’ll also inspect the length of the key_cache and its shape, and the shape of value_cache.
def create_hook_fn():
count = 1
def hook_fn(module, args, kwargs, output):
nonlocal count
input_shape = kwargs['hidden_states'].shape[:-1]
hidden_shape = (*input_shape, -1, module.head_dim)
query_states = module.q_proj(kwargs['hidden_states']).view(hidden_shape).transpose(1, 2)
print(count, f"len(past_key_value): {len(kwargs['past_key_value'].key_cache)},", f"query_states.shape: {query_states.shape},", f"k.shape: {kwargs['past_key_value'].key_cache[0].shape},", f"v.shape: {kwargs['past_key_value'].value_cache[0].shape}")
count += 1
return hook_fn
_hook_fn = create_hook_fn()
attn_layer = model.model.layers[0].self_attn
hook_handle = attn_layer.register_forward_hook(_hook_fn, with_kwargs=True)
outputs = model.generate(input_ids, pad_token_id=tokenizer.eos_token_id, do_sample=False, return_dict_in_generate=True, max_new_tokens=5)
hook_handle.remove()1 len(past_key_value): 1, query_states.shape: torch.Size([1, 9, 3, 64]), k.shape: torch.Size([1, 3, 3, 64]), v.shape: torch.Size([1, 3, 3, 64])
2 len(past_key_value): 30, query_states.shape: torch.Size([1, 9, 1, 64]), k.shape: torch.Size([1, 3, 4, 64]), v.shape: torch.Size([1, 3, 4, 64])
3 len(past_key_value): 30, query_states.shape: torch.Size([1, 9, 1, 64]), k.shape: torch.Size([1, 3, 5, 64]), v.shape: torch.Size([1, 3, 5, 64])
4 len(past_key_value): 30, query_states.shape: torch.Size([1, 9, 1, 64]), k.shape: torch.Size([1, 3, 6, 64]), v.shape: torch.Size([1, 3, 6, 64])
5 len(past_key_value): 30, query_states.shape: torch.Size([1, 9, 1, 64]), k.shape: torch.Size([1, 3, 7, 64]), v.shape: torch.Size([1, 3, 7, 64])We see that there are 9 query heads, and 3 KV heads. The total hidden dimension for Q, K and V layers is 3 x 64 = 192.
When the first token is being the generated, the length of the key_cache for layer_idx=0 is 1, because this is the first attention module’s first forward pass. For subsequent tokens (2, 3, 4, 5) the length of the key_cache is 30, as the cache has been instantiated for all 30 layers after the first token is generated.
Finally, we see that the key_cache and value_cache shapes are equal, as expected.
Which Flash Attention Interface is Used?
Since this exercise is part of my journey to understand the flash_attn_varlen_func, I was curious to confirm by visual inspection which Flash Attention interface function was being used. To achieve this, I wrote a “debug” version for the following three functions:
How did I know which functions to modify? Well, largely because I have done this exercise before when I was trying to understand what triggered the use of flash_attn_varlen_func.
More concisely, I first inspected the forward pass of the attention module:
from inspect import getsource
print(getsource(model.model.layers[0].self_attn.forward)) def forward(
self,
hidden_states: torch.Tensor,
position_embeddings: Tuple[torch.Tensor, torch.Tensor],
attention_mask: Optional[torch.Tensor],
past_key_value: Optional[Cache] = None,
cache_position: Optional[torch.LongTensor] = None,
**kwargs: Unpack[FlashAttentionKwargs],
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
input_shape = hidden_states.shape[:-1]
hidden_shape = (*input_shape, -1, self.head_dim)
query_states = self.q_proj(hidden_states).view(hidden_shape).transpose(1, 2)
key_states = self.k_proj(hidden_states).view(hidden_shape).transpose(1, 2)
value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
cos, sin = position_embeddings
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
if past_key_value is not None:
# sin and cos are specific to RoPE models; cache_position needed for the static cache
cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
attention_interface: Callable = eager_attention_forward
if self.config._attn_implementation != "eager":
if self.config._attn_implementation == "sdpa" and kwargs.get("output_attentions", False):
logger.warning_once(
"`torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to "
'eager attention. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
)
else:
attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
attn_output, attn_weights = attention_interface(
self,
query_states,
key_states,
value_states,
attention_mask,
dropout=0.0 if not self.training else self.attention_dropout,
scaling=self.scaling,
**kwargs,
)
attn_output = attn_output.reshape(*input_shape, -1).contiguous()
attn_output = self.o_proj(attn_output)
return attn_output, attn_weights
In there I saw the following lines of interest:
if self.config._attn_implementation != "eager":
if self.config._attn_implementation == "sdpa" and kwargs.get("output_attentions", False):
logger.warning_once(
"`torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to "
'eager attention. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
)
else:
attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]In our case, the else block would trigger and ALL_ATTENTION_FUNCTIONS would be accesssed. Looking at that constant directly we can see that for our model’s _attn_implementation ('flash_attention_2') the attention interface funtion is flash_attention_forward.
model.config._attn_implementation'flash_attention_2'from transformers.modeling_utils import ALL_ATTENTION_FUNCTIONS
ALL_ATTENTION_FUNCTIONS[model.config._attn_implementation]transformers.integrations.flash_attention.flash_attention_forward
def flash_attention_forward(module: torch.nn.Module, query: torch.Tensor, key: torch.Tensor, value: torch.Tensor, attention_mask: Optional[torch.Tensor], dropout: float=0.0, scaling: Optional[float]=None, sliding_window: Optional[int]=None, softcap: Optional[float]=None, **kwargs) -> Tuple[torch.Tensor, None]
<no docstring>
Show `_debug_flash_attention_forward
from typing import Optional, Tuple
import inspect
from flash_attn import flash_attn_func, flash_attn_varlen_func
import torch
import os
from transformers.modeling_flash_attention_utils import is_flash_attn_greater_or_equal, fa_peft_integration_check, _upad_input, pad_input, prepare_fa2_from_position_ids
_flash_supports_window_size = "window_size" in list(inspect.signature(flash_attn_func).parameters)
flash_241 = is_flash_attn_greater_or_equal("2.4.1")
deterministic_g = None
def _debug_flash_attention_forward(
query_states: torch.Tensor,
key_states: torch.Tensor,
value_states: torch.Tensor,
attention_mask: Optional[torch.Tensor],
query_length: int,
is_causal: bool,
dropout: float = 0.0,
position_ids: Optional[torch.Tensor] = None,
softmax_scale: Optional[float] = None,
sliding_window: Optional[int] = None,
use_top_left_mask: bool = False,
softcap: Optional[float] = None,
deterministic: Optional[bool] = None,
cu_seq_lens_q: Optional[torch.LongTensor] = None,
cu_seq_lens_k: Optional[torch.LongTensor] = None,
max_length_q: Optional[int] = None,
max_length_k: Optional[int] = None,
target_dtype: Optional[torch.dtype] = None,
**kwargs,
):
if not use_top_left_mask:
causal = is_causal
else:
# TODO: Remove the `query_length != 1` check once Flash Attention for RoCm is bumped to 2.1.
causal = is_causal and query_length != 1
# Assuming 4D tensors, key_states.shape[1] is the key/value sequence length (source length).
use_sliding_windows = (
_flash_supports_window_size and sliding_window is not None and key_states.shape[1] > sliding_window
)
flash_kwargs = {"window_size": (sliding_window, sliding_window)} if use_sliding_windows else {}
if flash_241:
if deterministic is None:
global deterministic_g
if deterministic_g is None:
deterministic_g = os.environ.get("FLASH_ATTENTION_DETERMINISTIC", "0") == "1"
deterministic = deterministic_g
flash_kwargs["deterministic"] = deterministic
if softcap is not None:
flash_kwargs["softcap"] = softcap
# PEFT possibly silently casts tensors to fp32, this potentially reconverts to correct dtype or is a no op
query_states, key_states, value_states = fa_peft_integration_check(
query_states, key_states, value_states, target_dtype
)
# Contains at least one padding token in the sequence
if attention_mask is not None:
batch_size = query_states.shape[0]
query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = _upad_input(
query_states, key_states, value_states, attention_mask, query_length
)
cu_seqlens_q, cu_seqlens_k = cu_seq_lens
max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
print("if attention_mask is not None: flash_attn_varlen_func is being used")
attn_output_unpad = flash_attn_varlen_func(
query_states,
key_states,
value_states,
cu_seqlens_q=cu_seqlens_q,
cu_seqlens_k=cu_seqlens_k,
max_seqlen_q=max_seqlen_in_batch_q,
max_seqlen_k=max_seqlen_in_batch_k,
dropout_p=dropout,
softmax_scale=softmax_scale,
causal=causal,
**flash_kwargs,
)
attn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)
# If position_ids is provided and check all examples do not contain only 1 sequence, If tensor in increasing
# then we probably have one sequence, otherwise it is packed. Additionally check we are in pre-fill/training stage.
# Use `flash_attn_varlen_func` to prevent cross-example attention and also allow padding free approach
elif position_ids is not None and (
max_length_q is not None or (query_length != 1 and not (torch.diff(position_ids, dim=-1) >= 0).all())
):
batch_size = query_states.size(0)
if cu_seq_lens_q is None or cu_seq_lens_k is None:
query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = (
prepare_fa2_from_position_ids(query_states, key_states, value_states, position_ids)
)
cu_seq_lens_q, cu_seq_lens_k = cu_seq_lens
max_length_q, max_length_k = max_seq_lens
else:
query_states = query_states.reshape(-1, query_states.size(-2), query_states.size(-1))
key_states = key_states.reshape(-1, key_states.size(-2), key_states.size(-1))
value_states = value_states.reshape(-1, value_states.size(-2), value_states.size(-1))
print("position_ids is not None: flash_attn_varlen_func is being used")
attn_output = flash_attn_varlen_func(
query_states,
key_states,
value_states,
cu_seqlens_q=cu_seq_lens_q,
cu_seqlens_k=cu_seq_lens_k,
max_seqlen_q=max_length_q,
max_seqlen_k=max_length_k,
dropout_p=dropout,
softmax_scale=softmax_scale,
causal=causal,
**flash_kwargs,
)
attn_output = attn_output.view(batch_size, -1, attn_output.size(-2), attn_output.size(-1))
else:
print("flash_attn_func is being used")
attn_output = flash_attn_func(
query_states, key_states, value_states, dropout, softmax_scale=softmax_scale, causal=causal, **flash_kwargs
)
return attn_outputShow `debug_flash_attention_forward
from typing import Optional, Tuple
import torch
from transformers.modeling_flash_attention_utils import _flash_attention_forward, flash_attn_supports_top_left_mask
_use_top_left_mask = flash_attn_supports_top_left_mask()
def debug_flash_attention_forward(
module: torch.nn.Module,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
attention_mask: Optional[torch.Tensor],
dropout: float = 0.0,
scaling: Optional[float] = None,
sliding_window: Optional[int] = None,
softcap: Optional[float] = None,
**kwargs,
) -> Tuple[torch.Tensor, None]:
if kwargs.get("output_attentions", False) or kwargs.get("head_mask", None) is not None:
print(
"`flash_attention_2` does not support `output_attentions=True` or `head_mask`."
" Please set your attention to `eager` if you want any of these features."
)
# This is before the transpose
seq_len = query.shape[2]
# FA2 uses non-transposed inputs
query = query.transpose(1, 2)
key = key.transpose(1, 2)
value = value.transpose(1, 2)
# In PEFT, usually we cast the layer norms in float32 for training stability reasons
# therefore the input hidden states gets silently casted in float32. Hence, we need
# cast them back in the correct dtype just to be sure everything works as expected.
# This might slowdown training & inference so it is recommended to not cast the LayerNorms
# in fp32. (usually our RMSNorm modules handle it correctly)
target_dtype = None
if query.dtype == torch.float32:
if torch.is_autocast_enabled():
target_dtype = torch.get_autocast_gpu_dtype()
# Handle the case where the model is quantized
elif hasattr(module.config, "_pre_quantization_dtype"):
target_dtype = module.config._pre_quantization_dtype
else:
target_dtype = next(layer for layer in module.modules() if isinstance(layer, torch.nn.Linear)).weight.dtype
# FA2 always relies on the value set in the module, so remove it if present in kwargs to avoid passing it twice
kwargs.pop("is_causal", None)
print("DEBUG: calling _flash_attention_forward")
attn_output = _debug_flash_attention_forward(
query,
key,
value,
attention_mask,
query_length=seq_len,
is_causal=module.is_causal,
dropout=dropout,
softmax_scale=scaling,
sliding_window=sliding_window,
softcap=softcap,
use_top_left_mask=_use_top_left_mask,
target_dtype=target_dtype,
**kwargs,
)
return attn_output, NoneShow `debug_forward
from typing import Callable, Optional, Tuple, Union
from transformers.modeling_flash_attention_utils import FlashAttentionKwargs
from transformers.cache_utils import Cache, DynamicCache
from transformers.processing_utils import Unpack
from transformers.models.llama.modeling_llama import apply_rotary_pos_emb
from transformers.models.llama.modeling_llama import eager_attention_forward
from transformers.modeling_utils import ALL_ATTENTION_FUNCTIONS
def debug_forward(
self,
hidden_states: torch.Tensor,
position_embeddings: Tuple[torch.Tensor, torch.Tensor],
attention_mask: Optional[torch.Tensor],
past_key_value: Optional[Cache] = None,
cache_position: Optional[torch.LongTensor] = None,
**kwargs: Unpack[FlashAttentionKwargs],
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
input_shape = hidden_states.shape[:-1]
hidden_shape = (*input_shape, -1, self.head_dim)
query_states = self.q_proj(hidden_states).view(hidden_shape).transpose(1, 2)
key_states = self.k_proj(hidden_states).view(hidden_shape).transpose(1, 2)
value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
cos, sin = position_embeddings
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
if past_key_value is not None:
# sin and cos are specific to RoPE models; cache_position needed for the static cache
cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
attention_interface: Callable = eager_attention_forward
if self.config._attn_implementation != "eager":
if self.config._attn_implementation == "sdpa" and kwargs.get("output_attentions", False):
print(
"`torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to "
'eager attention. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
)
else:
#attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
attention_interface = debug_flash_attention_forward
attn_output, attn_weights = attention_interface(
self,
query_states,
key_states,
value_states,
attention_mask,
dropout=0.0 if not self.training else self.attention_dropout,
scaling=self.scaling,
**kwargs,
)
attn_output = attn_output.reshape(*input_shape, -1).contiguous()
attn_output = self.o_proj(attn_output)
return attn_output, attn_weightstokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM2-135M")
model = AutoModelForCausalLM.from_pretrained("HuggingFaceTB/SmolLM2-135M", attn_implementation="flash_attention_2", torch_dtype=torch.bfloat16).to("cuda")types.MethodType binds a function (debug_forward) as a method for a class (attn_layer_instance).
import types
types.MethodType??Init signature: types.MethodType(self, /, *args, **kwargs)
Docstring: Create a bound instance method object.
Type: type
Subclasses: attn_layer_instance = model.model.layers[0].self_attn
original_layer_forward = attn_layer_instance.forward
attn_layer_instance.forward = types.MethodType(debug_forward, attn_layer_instance)def create_hook_fn():
count = 1
def hook_fn(module, args, kwargs, output):
nonlocal count
input_shape = kwargs['hidden_states'].shape[:-1]
hidden_shape = (*input_shape, -1, module.head_dim)
query_states = module.q_proj(kwargs['hidden_states']).view(hidden_shape).transpose(1, 2)
print(count, len(kwargs['past_key_value'].key_cache), f"query_states.shape: {query_states.shape}", f"k.shape: {kwargs['past_key_value'].key_cache[0].shape}")
# for k in kwargs['past_key_value'].key_cache: print(k.shape) # do this for v as well
count += 1
return hook_fn
_hook_fn = create_hook_fn()
attn_layer = model.model.layers[0].self_attn
hook_handle = attn_layer.register_forward_hook(_hook_fn, with_kwargs=True)
outputs = model.generate(input_ids, pad_token_id=tokenizer.eos_token_id, do_sample=False, return_dict_in_generate=True, max_new_tokens=5)
print(outputs.sequences[0].shape)
hook_handle.remove()DEBUG: calling _flash_attention_forward
flash_attn_func is being used
1 1 query_states.shape: torch.Size([1, 9, 3, 64]) k.shape: torch.Size([1, 3, 3, 64])
DEBUG: calling _flash_attention_forward
flash_attn_func is being used
2 30 query_states.shape: torch.Size([1, 9, 1, 64]) k.shape: torch.Size([1, 3, 4, 64])
DEBUG: calling _flash_attention_forward
flash_attn_func is being used
3 30 query_states.shape: torch.Size([1, 9, 1, 64]) k.shape: torch.Size([1, 3, 5, 64])
DEBUG: calling _flash_attention_forward
flash_attn_func is being used
4 30 query_states.shape: torch.Size([1, 9, 1, 64]) k.shape: torch.Size([1, 3, 6, 64])
DEBUG: calling _flash_attention_forward
flash_attn_func is being used
5 30 query_states.shape: torch.Size([1, 9, 1, 64]) k.shape: torch.Size([1, 3, 7, 64])
torch.Size([8])From the print statements in my _debug_flash_attention_forward function, I can see that flash_attn_func, the non-variable-length interface, is being used for this generation. That makes sense because I only have 1 item in the batch.
Understanding the flash_attn_varlen_func Causal Mask Docstring
A quick recap of what we’ve learned so far:
- HuggingFace’s
model.generateuses KV cache by default (DynamicCache) stored aspast_key_values. - For most scenarios, the
DynamicCacheis updated by concatenating the previous token’skey_cacheandvalue_cachewith thekey_statesandvalue_statesgenerated for the current new token. - As the next token is generated for a given prompt,
query_stateshas a sequence length of1, whereaskey_cacheandvalue_cachetensors’ sequence dimension increases by 1. This is directly relates to theflash_attn_varlen_funccausal mask docstring example. model.generateutilized theflash_attn_funcinterface.
Let’s look at the flash_attn_varlen_func docstring snippet again:
If causal=True, the causal mask is aligned to the bottom right corner of the attention matrix.
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 = masked out) is:
1 1 1 1 0
1 1 1 1 1
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
0 0
0 0
0 0
1 0
1 1
If the row of the mask is all zero, the output will be zero.I’ll annotate the causal mask examples a bit:
seqlen_q=2 and seqlen_k=5
| k_0 | k_1 | k_2 | k_3 | k_4 | |
|---|---|---|---|---|---|
| q_0 | 1 | 1 | 1 | 1 | 0 |
| q_1 | 1 | 1 | 1 | 1 | 1 |
The final query token (q_1) sees all 5 key tokens. The first query token (q_0) only sees the first four key tokens.
seqlen_q=5 and seqlen_k=2
| k_0 | k_1 | |
|---|---|---|
| q_0 | 0 | 0 |
| q_1 | 0 | 0 |
| q_2 | 0 | 0 |
| q_3 | 1 | 0 |
| q_4 | 1 | 1 |
Again, the final query token (q_4) sees all key tokens. As a consequence, since there are only two key tokens, the first three query tokens do not see any key tokens.
In each example, we are offsetting the shorter sequence so that its last token aligns with the other sequences’s last token. This is what the flash_attn_varlen_func docstring means by
the causal mask is aligned to the bottom right corner of the attention matrix
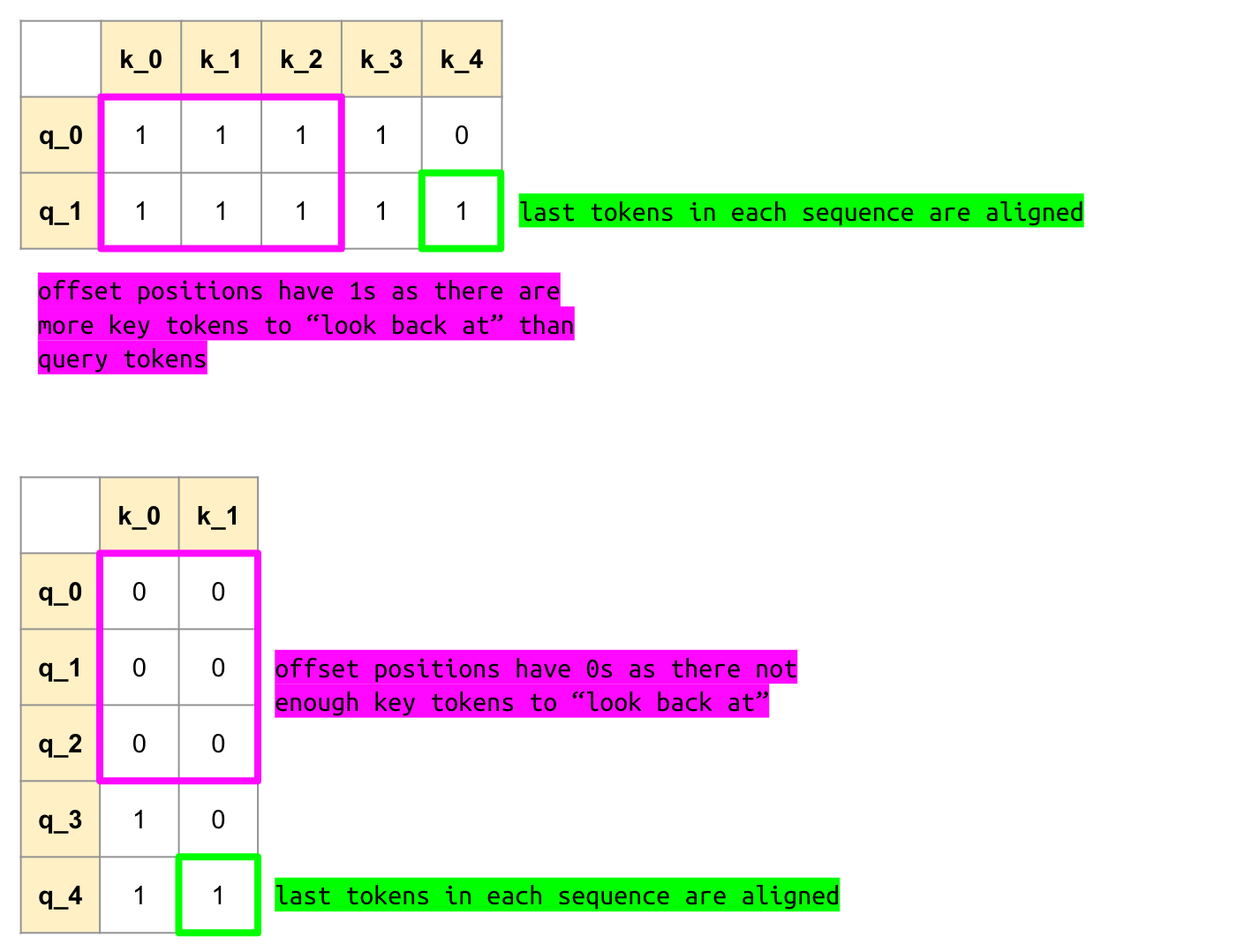
In the first case, the query sequence is shorter so we offset it by 3 positions to align with the last two tokens of the key sequence. The “offset” positions are 1s (this satisfies the rule of causality j <= i, query tokens can look back). In the second case, the key sequence is shorter so we offset it by 3 positions to align with the last two tokens of the query sequence. The offset positions are 0s (again, this satisfies causality, the query tokens have nothing to look back to).
The model.generate examples above are like the first case, where there are more key positions than query positions. The query token (the next-token being predicted) can look back at all key tokens.
A Math-y Way to think About It
For those of you who like to think through things with math.
Causality (in language modeling) means that a query token vector at the i-th position can only see its own and previous tokens’ key vectors. Having different sequence lengths for Q and K (5 and 2 or 2 and 5 in the flash_attn_varlen_func docstring example or 1 and 3-7 in my inspections above) requires you to pick how Q and K are aligned. In the case of flash_attn_varlen_func they choose to align Q and K such as the last Q token vector is aligned with the last K token vector. This becomes our “present moment” P with causality allowing access to previous tokens only.
Let’s define i as the position of query tokens and j as the position of key tokens. Causality is defined as token pairs that follow the inequality: j <= i + (seqlen_k - seqlen_q).
For the first causal mask example:
j |
i |
j <= i + (seqlen_k - seqlen_q) |
|---|---|---|
| 0 | 0 | 0 <= 0 + 3 (True) |
| 1 | 0 | 1 <= 0 + 3 (True) |
| 2 | 0 | 2 <= 0 + 3 (True) |
| 3 | 0 | 3 <= 0 + 3 (True) |
| 4 | 0 | 4 <= 0 + 3 (False) |
| 0 | 1 | 0 <= 1 + 3 (True) |
| 1 | 1 | 1 <= 1 + 3 (True) |
| 2 | 1 | 2 <= 1 + 3 (True) |
| 3 | 1 | 3 <= 1 + 3 (True) |
| 4 | 1 | 4 <= 1 + 3 (True) |
Where does j <= i + (seqlen_k - seqlen_q) come from?
Let q_i be a query that is seqlen_q - 1 - i steps before the end of the query sequence, and k_j be a key that is seqlen_k - 1 - j steps before the end of the key sequence. More concretely, for the example where seqlen_q = 2 and seqlen_k=5:
| q_i | Steps before end | seqlen_q - 1 - i |
|---|---|---|
| q_0 | 1 | 2 - 1 - 0 |
| q_1 | 0 | 2 - 1 - 1 |
| k_j | Steps before end | seqlen_k - 1 - j |
|---|---|---|
| k_0 | 4 | 5 - 1 - 0 |
| k_1 | 3 | 5 - 1 - 1 |
| k_2 | 2 | 5 - 2 - 1 |
| k_3 | 1 | 5 - 3 - 1 |
| k_4 | 0 | 5 - 4 - 1 |
By picking a “present moment” P (the last token in each sequence) have a unified timeline p such that causality is defined as: p_j <= p_i. k_j has a position on the timeline p_j = P - (seqlen_k - 1 - j) and q_i has a position on the timeline p_i = P - (seqlen_q - 1 - i). Causality requires that p_j <= p_i on our “unified timeline”. Writing that out:
P - (seqlen_k - 1 - j) <= P - (seqlen_q - 1 - i)
Cancelling out the Ps and distributing the minus sign:
-seqlen_k + 1 + j <= -seqlen_q + 1 + i
Isolating j on the lefthand side:
j <= -seqlen_q + 1 + i + seqlen_k - 1
Simplifying + reordering:
j <= i + (seqlen_k - seqlen_q)
We can think of this (seqlen_k - seqlen_q) to be an “offset” term between the two sequences.
Looking at this concretely for the second causal mask:
| k_0 | k_1 | |
|---|---|---|
| q_0 | 0 | 0 |
| q_1 | 0 | 0 |
| q_2 | 0 | 0 |
| q_3 | 1 | 0 |
| q_4 | 1 | 1 |
j |
i |
j <= i + (seqlen_k - seqlen_q) |
|---|---|---|
| 0 | 0 | 0 <= 0 - 3 (False) |
| 0 | 1 | 0 <= 1 - 3 (False) |
| 0 | 2 | 0 <= 2 - 3 (False) |
| 0 | 3 | 0 <= 3 - 3 (True) |
| 0 | 4 | 0 <= 4 - 3 (True) |
| 1 | 0 | 1 <= 0 - 3 (False) |
| 1 | 1 | 1 <= 1 - 3 (False) |
| 1 | 2 | 1 <= 2 - 3 (False) |
| 1 | 3 | 1 <= 3 - 3 (False) |
| 1 | 4 | 1 <= 4 - 3 (True) |
Closing Thoughts
Understanding flash_attn_varlen_func is going to require a sequence (pun intended) of such deep dives. It took me hours to just get through the docstring!! I’m also working on understanding ModernBERT’s sequence packing implementation (to the point of explaining it with visuals) and I expect it to interweave with my Flash Attention study, especially when understanding how ModernBERT prepares and packs sequences and related artifacts in preparation of passing it through the attention mechanism, utilizing flash_attn_varlen_func. It’s an exciting one-two punch for sure! I’m glad I’m working on them together.
I’ll end with listing out again what I’ve learned in this notebook/exercise, with a couple points added about the causal mask:
- HuggingFace’s
model.generateuses KV cache by default (DynamicCache) stored aspast_key_values. - For most scenarios, the
DynamicCacheis updated by concatenating the previous token’skey_cacheandvalue_cachewith thekey_statesandvalue_statesgenerated for the current new token. - As the next token is generated for a given prompt,
query_stateshas a sequence length of1, whereaskey_cacheandvalue_cachetensors’ sequence dimension increases by 1. This is directly relates to theflash_attn_varlen_funccausal mask docstring example. model.generateutilized theflash_attn_funcinterface.- The causal mask is aligned to the bottom-right of the attention matrix (the last tokens of the Q and K sequence are aligned).
- Causality, when \(Q_i\) and \(K_j\) sequences are of different length, is satisfied by the equation
j <= i + (seqlen_k - seqlen_q). - When there are more query tokens than key tokens, the “offset” (needed to align the last token of each sequence) results in 0s in the mask as there are no key tokens to “look back at”.
- When there are more key tokens than query tokens, the “offset” results in 1s as the query tokens can look back at more key tokens.
I’m trying to grow my YouTube channel this year so if you enjoyed this blog post, please subscribe!