Debugging Flash Attention in LLM-Foundry (and a 20% Slow Down!)
Background
I’m learning a lot about LLM-Foundry while working on a group research project. In this blog post I’ll walk through how we figured out two things:
- LLM-Foundry, by default when using a HuggingFace LlamaModel, does not use
flash_attn_varlen_funcand instead usesflash_attn_func. In other words, it doesn’t unpad the batch by default. - When forcing LLM-Foundry to use
flash_attn_varlen_func, it slows down training time.
I’ll start by walking through the forward pass of the HuggingFace LlamaModel down to the attention mechanism which uses the _flash_attention_forward utility function which decides which Flash Attention interface is being used.
What is the value of the attention_mask?
The model we’re using is SmolLM2-135M which uses the now-deprecated LlamaFlashAttention2 module.
Inspecting the LlamaModel forward pass, the first instance of where the attention_mask is used:
causal_mask = self._update_causal_mask(
attention_mask, inputs_embeds, cache_position, past_key_values, output_attentions
)Looking at _update_causal_mask:
if self.config._attn_implementation == "flash_attention_2":
if attention_mask is not None and 0.0 in attention_mask:
return attention_mask
return NoneIf 0.0 in attention_mask then the attention_mask will be returned, other None is returned.
We’ll come back to this point later on.
When is flash_attn_varlen_func called?
Let’s assume 0.0 in attention_mask is True, so the attention_mask is kept as is and is passed onto the LlamaDecoderLayer and eventually the attention mechanism which calls _flash_attention_forward. flash_attention_forward is defined in transformers/modeling_flash_utils.py, and triggers the use of flash_attn_varlen_func if one of two conditions are true:
if attention_mask is not Noneor
elif (
position_ids is not None
and query_states.shape[0] == 1
and (max_length_q is not None or (query_length != 1 and not (torch.diff(position_ids, dim=-1) >= 0).all()))
)The elif condition is True if position_ids is not None and query_states.shape[0] == 1 and either max_length_q is not None or (query_length != 1 and not (torch.diff(position_ids, dim=-1) >= 0).all()). The torch.diff expression is False if the difference in consecutive values in position_ids are not greater than 0. For example, the following position_ids would yield False:
[0, 1, 2, 3, 0, 1, 2, 3, 4, 5, 0, 1, 2]torch.diff for the 4th and 5th position (3 to 0) is -3. We would expect such a position_ids sequence when you have packed sequences.
How do we check the value of attention_mask during training?
To do so, I wrote the following Composer callback:
class FlashAttentionDebug(Callback):
def before_forward(self, state: State, logger: Logger) -> None:
model = state.model
print(model.config._attn_implementation)
self.hooks = []
def create_hook_fn(name):
def hook_fn(module, args, kwargs, output):
if 'attention_mask' in kwargs:
print(f"{name} FlashAttentionDebug: attention_mask is None:", kwargs['attention_mask'] is None)
if kwargs['attention_mask'] is not None:
print(f"{name} FlashAttentionDebug: attention_mask:", kwargs['attention_mask'])
print(f"{name} FlashAttentionDebug: 0.0 in attention_mask:", 0.0 in kwargs['attention_mask'])
print(f"{name} FlashAttentionDebug: attention_mask.shape:", kwargs['attention_mask'].shape)
print(f"{name} FlashAttentionDebug: attention_mask.sum():", kwargs["attention_mask"].sum())
return hook_fn
attn_layer = model.model.base_model.model.model.layers[0].self_attn
hook_handle = attn_layer.register_forward_hook(create_hook_fn("attn_layer"), with_kwargs=True)
self.hooks.append(hook_handle)
decoder_layer = model.model.base_model.model.model.layers[0]
print(type(decoder_layer))
hook_handle = decoder_layer.register_forward_hook(create_hook_fn("decoder_layer"), with_kwargs=True)
self.hooks.append(hook_handle)
_model = model.model.base_model.model.model
print(type(_model))
hook_handle = _model.register_forward_hook(create_hook_fn("model"), with_kwargs=True)
self.hooks.append(hook_handle)
def after_forward(self, state: State, logger: Logger) -> None:
for hook in self.hooks:
hook.remove()
self.hooks = []create_hook_fn is a closure which returns hook_fn. I used this pattern so I could log the name of the module the hook is attached to. Note that when using register_forward_hook you must specify with_kwargs=True to pass kwargs to the hook function.
Here are the outputs when using the default LLM-Foundry pretraining setup:
flash_attention_2
<class 'transformers.models.llama.modeling_llama.LlamaDecoderLayer'>
<class 'transformers.models.llama.modeling_llama.LlamaModel'>
attn_layer FlashAttentionDebug: attention_mask is None: True
decoder_layer FlashAttentionDebug: attention_mask is None: True
model FlashAttentionDebug: attention_mask is None: False
model FlashAttentionDebug: attention_mask: tensor([[1, 1, 1, ..., 1, 1, 1]], device='cuda:0')
model FlashAttentionDebug: 0.0 in attention_mask: False
model FlashAttentionDebug: attention_mask.shape: torch.Size([1, 2048])
model FlashAttentionDebug: attention_mask.sum(): tensor(2048, device='cuda:0')Note that in the attention layer, attention_mask is None because as we can see in the model forward output, 0.0 is not in attention_mask (it’s full of 1s).
How do we create an attention_mask with 0.0s?
With the help of Cursor (my first time using it!) I was able to add one simple line to the __call__ method of the default pretraining collator ConcatenatedSequenceCollatorWrapper:
batch['attention_mask'] = (batch['input_ids'] != 0).long()Where input_ids are not 0 (the EOS token id used for padding) attention_mask will be 1; it will be 0 where there are padding tokens.
Since I’m using Modal for training, and since the image brings down our LLM-Foundry fork, and since I need to modify the ConcatenatedSequenceCollatorWrapper.__call__ method (which lives in llmfoundry/data/text_data.py) I add the following line after my Modal is built:
image = image.add_local_file("text_data.py", "/llm-foundry/llmfoundry/data/text_data.py")Running training with this modified collator the FlashAttentionDebug callback logs the following:
flash_attention_2
<class 'transformers.models.llama.modeling_llama.LlamaDecoderLayer'>
<class 'transformers.models.llama.modeling_llama.LlamaModel'>
attn_layer FlashAttentionDebug: attention_mask is None: False
attn_layer FlashAttentionDebug: attention_mask: tensor([[1, 1, 1, ..., 0, 0, 0]], device='cuda:0')
attn_layer FlashAttentionDebug: 0.0 in attention_mask: True
attn_layer FlashAttentionDebug: attention_mask.shape: torch.Size([1, 2048])
attn_layer FlashAttentionDebug: attention_mask.sum(): tensor(201, device='cuda:0')
decoder_layer FlashAttentionDebug: attention_mask is None: False
decoder_layer FlashAttentionDebug: attention_mask: tensor([[1, 1, 1, ..., 0, 0, 0]], device='cuda:0')
decoder_layer FlashAttentionDebug: 0.0 in attention_mask: True
decoder_layer FlashAttentionDebug: attention_mask.shape: torch.Size([1, 2048])
decoder_layer FlashAttentionDebug: attention_mask.sum(): tensor(201, device='cuda:0')
model FlashAttentionDebug: attention_mask is None: False
model FlashAttentionDebug: attention_mask: tensor([[1, 1, 1, ..., 0, 0, 0]], device='cuda:0')
model FlashAttentionDebug: 0.0 in attention_mask: True
model FlashAttentionDebug: attention_mask.shape: torch.Size([1, 2048])
model FlashAttentionDebug: attention_mask.sum(): tensor(201, device='cuda:0')Now we can see that in the attention layer, the attention_mask is not None. It contains 0.0 values (note how the sum, 201, is less than the sequence length of 2048) which is why the _update_causal_mask method returned attention_mask as is. We can also visually inspect the attention_mask tensor in the model, decoder layer and attention mechanism forward pass and see both 1s and 0s.
How do we know if flash_attn_varlen_func is being used?
Now that we know that introducing 0s in the attention_mask allows it to be passed through the model, including the attention mechanism, we should confirm that flash_attn_varlen_func is called. If you recall, one of the conditions for it being called was that attention_mask is not None. To check this, we can monkey-patch _upad_input which is the method called to unpad the batch if attention_mask is not None:
import transformers.modeling_flash_attention_utils as flash_utils
original_upad_input = flash_utils._upad_input
original_prepare_fa2_from_position_ids = flash_utils.prepare_fa2_from_position_ids
def debug_upad_input(query_states, key_states, value_states, attention_mask, query_length):
print("DEBUG: Using _upad_input")
print(f" query_states: {query_states.shape}")
print(f" key_states: {key_states.shape}")
print(f" value_states: {value_states.shape}")
print(f" attention_mask: {attention_mask.shape}")
print(f" query_length: {query_length}")
query_layer, key_layer, value_layer, indices_q, (cu_seqlens_q, cu_seqlens_k),(max_seqlen_in_batch_q, max_seqlen_in_batch_k) = original_upad_input(query_states, key_states, value_states, attention_mask, query_length)
print(f"query_layer.shape: ", query_layer.shape)
print(f"key_layer.shape: ", key_layer.shape)
print(f"value_layer.shape: ", value_layer.shape)
print(f"indices_q.shape: ", indices_q.shape)
print(f"cu_seqlens_q.shape: ", cu_seqlens_q.shape)
print(f"cu_seqlens_q: ", cu_seqlens_q.tolist())
print(f"cu_seqlens_k.shape: ", cu_seqlens_k.shape)
print(f"cu_seqlens_k: ", cu_seqlens_k.tolist())
print(f"max_seqlen_in_batch_q: ", max_seqlen_in_batch_q)
print(f"max_seqlen_in_batch_k: ", max_seqlen_in_batch_k)
print(f"indices_q: ", indices_q.tolist())
seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
print(seqlens_in_batch.tolist())
print(attention_mask[0].tolist())
return original_upad_input(query_states, key_states, value_states, attention_mask, query_length)
flash_utils._upad_input = debug_upad_inputI added a original_upad_input call and stored the output so I could see what gets passed on to flash_attn_varlen_func.
During the training run, with our modified collator, we see the following output (this was for a run with a batch size of 6):
DEBUG: Using _upad_input
query_states: torch.Size([6, 2048, 9, 64])
key_states: torch.Size([6, 2048, 3, 64])
value_states: torch.Size([6, 2048, 3, 64])
attention_mask: torch.Size([6, 2048])
query_length: 2048
query_layer.shape: torch.Size([1395, 9, 64])
key_layer.shape: torch.Size([1395, 3, 64])
value_layer.shape: torch.Size([1395, 3, 64])
indices_q.shape: torch.Size([1395])
cu_seqlens_q.shape: torch.Size([7])
cu_seqlens_q: [0, 220, 437, 732, 915, 1045, 1395]
cu_seqlens_k.shape: torch.Size([7])
cu_seqlens_k: [0, 220, 437, 732, 915, 1045, 1395]
max_seqlen_in_batch_q: 350
max_seqlen_in_batch_k: 350
Some key observations:
query_states has size 6 (batch size) x 2048 (sequence length) x 9 (num heads) x 64 (head dim).
query_layer (one of the _upad_input outputs and flash_attn_varlen_func inputs) has size 1395 (total sequence length) x 9 (num heads) x 64 (head dim).
The cu_seqlens_q that is a critical input to flash_attn_varlen_func show us that there are 6 sequences packed together and the “boundaries” of the sequences are [0, 220, 437, 732, 915, 1045, 1395]. Using my DataInspector callback I confirmed the number of non-padding tokens in the batch: 220, 217, 295, 183, 130, 350. The sum of these counts is 1395, the total sequence length passed to flash_attn_varlen_func.
Wait, flash_attn_varlen_func slows down training?
When using my modified collator, and therefore utilizing flash_attn_varlen_func the training time slows down by over 20%. This was certainly a surprise for me! After discussing this with our research advisor, we learned that this is likely because the HuggingFace implementation of the model unpads and re-pads the batch for each layer.
We can see this in the _flash_attention_forward method, after flash_attn_varlen_func is called:
attn_output = _pad_input(attn_output_unpad, indices_q, batch_size, query_length)The solution to mitigating this slow-down is to implement our own custom model where it unpads the batch only once. This will be our next task!
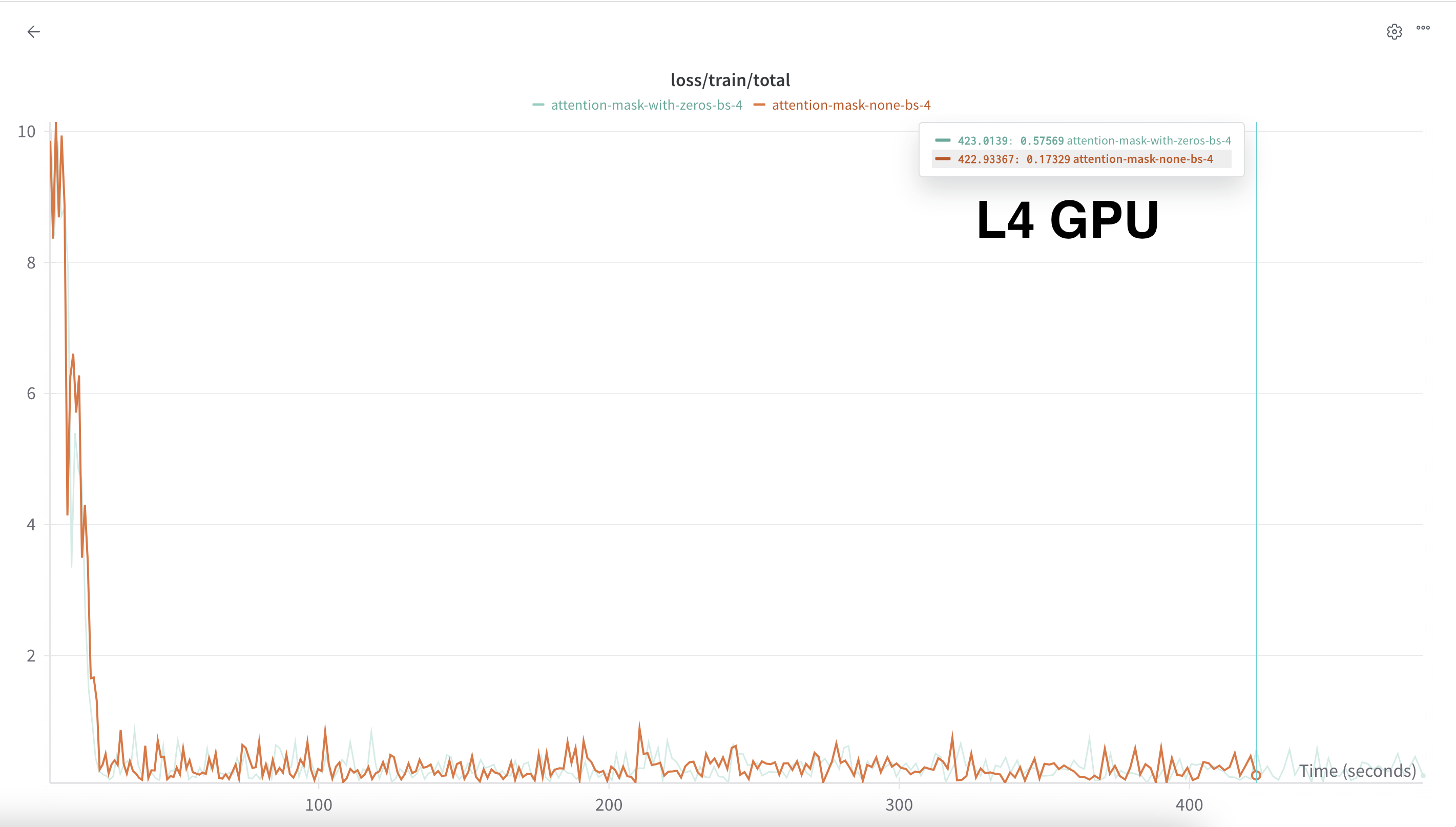
flash_attn_func usage results in a faster training. Click image to expand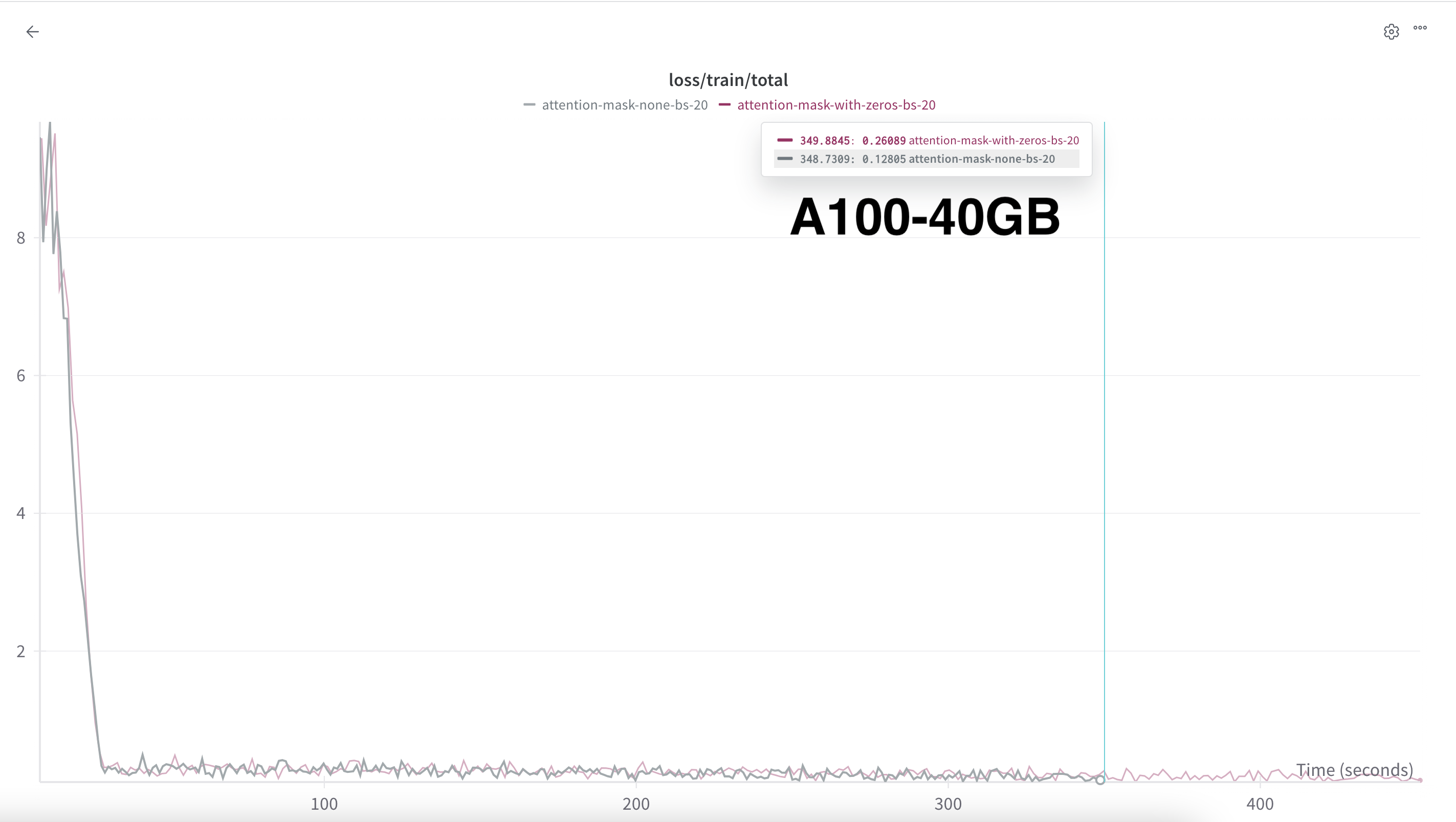
flash_attn_func usage results in a faster training. Click image to expandClosing Thoughts
The biggest takeaway from this experience, as has been the case for all practical training experiments I’ve run (whether for LMs or vision models) is that there’s a difference between what is theoretically efficient and whether that is practically efficient. In theory, flash_attn_varlen_func should be faster because you are not wasting the quadratic attention compute on padding tokens. In practice, unpadding and re-padding the batch for each layer for each forward pass adds an overhead which not only cancels out that attention computation speedup, but slows down the training compared to a fully-padded forward pass. This is a critical lesson I experience again and again, and it helps me understand the value of choosing the right implementation to actualize theoretical efficiencies.
I’m growing my YouTube channel this year, so if you like this type of content please subscribe!